A tag already exists with the provided branch name. Many Git commands accept both tag and branch names, so creating this branch may cause unexpected behavior. Are you sure you want to create this branch?
Cancel Create
highload-2018 / 2.1-vk-architecture.md
- Go to file T
- Go to line L
- Copy path
- Copy permalink
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Cannot retrieve contributors at this time
171 lines (109 sloc) 8.56 KB
- Open with Desktop
- View raw
- Copy raw contents Copy raw contents Copy raw contents
Copy raw contents
FAQ по архитектуре и работе ВКонтакте
Алексей Акулович, ВКонтакте
- FAQ по архитектуре и работе ВКонтакте
- Архитектура
- Базы данных
- Логи
- Мониторинг
- Деплой
- Другие доклады про архитектуру VK
- фронты: независимые сервера с nginx, анонсируют общие IP,терминируют HTTPS/WSS.
- бэкенды: http сервера на kPHP, модель работы prefork, вместо перезапуска сбрасывают состояние (global/static vars). Для распределения нагрузки:
- Бэкенды группируются: general, mobile, api и т.п. Выбирает между ними nginx на фронте.
- Сбор метрик и перебалансировка.
- для терминирования HTTPS
- чтобы использовать серые IP-адреса для cs
- для отказоустойчивости через общие IP
- спорно — чтобы клиент держал меньше соединений
Обычно видео гоняется напрямую, а более лёгкий контент — через прокси.
Алексей Акулович — Архитектура растущего проекта на примере ВКонтакте
- у pp один IP на группу, в результате один файл оседает во всех кешах
- pp нельзя шардировать и ставить в регионах
Как устроены sun:
- маршрутизация anycast
- кеширование
- поддержка весов
- можно ставить в регионах
- шардирование по id контента (например, когда 100000 человек запрашивают аватарку одного пользователя)
- сбор сетей региона по BGP
- инфа загружается в базу, + geoip
- по IP пользователя определяем регион
Называем engines, потому что это не совсем базы данных.
В 2008-2009 использовали MySQL и Memcached, но они не выдержали взрывного роста пользователей. Заменили их на велосипеды.
Типов движков очень много. На каждую задачу — новый тип движка. Очереди, списки, сеты — всё что угодно.
Движки одного типа объединяются в кластеры. Код не знает расположения и размера кластеров. Для этого между серверами и базами есть ещё rpc-proxy:
- общая шина
- service discovery, forwarding
- circuit breaker
На каждом сервере есть локальный rpc-proxy, который знает, куда направить запросы и где находятся engines.
Если один engine идёт в другой, то тоже делает это через прокси. Engine не должен знать ничего, кроме себя.
FAQ по архитектуре и работе ВКонтакте / Алексей Акулович (ВКонтакте)
Персистентное хранение данных:
- движки пишут бинлоги: binary log (WAL, AOF). Пишутся в одинаковом бинарном формате (TL scheme), чтобы админы их читали своими инструментами.
- снапшоты: слепок данных + offset в бинлоге. Общее начало, тело произвольное.
При перезапуске движок сначала читает снапшот, восстанавливает из него своё состояние. Потом из него находит offset, по нему дочитывает остаток из бинлога, восстанавливает окончательное состояние.
Результат: репликация данных:
- statement-based
- инкрементальный унос «хвоста» бинлога
Эта же схема используется для создания бэкапов.

- отправка в memcached. Там кольцевой буфер ( ring-buffer: prefix.idx = line ).
- отправка в logs-engine (разработан in-house)
Хранятся в ClickHouse. Чтобы это заработало, приходится локальный rpc-proxy заменить на KittenHouse, а на движке добавлять KittenHouse reverse proxy.
А ещё есть nginx, чтобы получать логи по UDP.

Есть два типа метрик.
Системные и админские метрики:
- netdata собирает статистику,
- отсылает в Graphite Carbon
- ClickHouse
- можно смотреть через Grafana
Продуктовые и разработческие метрики:
- много метрик
- очень много событий — от 0,6 до 1 триллиона в сутки
- храним 2+ года
Эксперимент: собираем метрики на ClickHouse
- удобнее основной системы
- требует меньше серверов, но сами сервера жирнее
Git, GitLab, TeamCity
- git pruduction branch
- diff файла
- записывается в binlog copyfast
- реплицируется на сервера через gossip replication
- применяется локальными репликами на локальной файловой системе
- большой бинарь, сотни МБ
- git master branch
- версию пишем в binlog copyfast
- реплицируем версию на сервера
- сервер вытягивает свежий бинарник через gossip replication
- graceful-перезапуск на новую версию
- бинари в .deb
- git master branch
- версию пишем в binlog copyfast
- реплицируем версию на сервера
- сервер вытягивает свежий .deb
- dpkg -i
- graceful-перезапуск на новую версию
Другие доклады про архитектуру VK
- Системный администратор ВКонтакте. Как?
- Разработка в ненадёжной нагруженной среде
- Как VK вставляет данные в ClickHouse с десятков тысяч серверов: на Highload Siberia и на Highload Moscow
- Архитектура растущего проекта на примере ВКонтакте
Источник: github.com
Архитектура как устроен вконтакте
Архитектуры и масштабируемость
Доклад принят в программу конференции
Мнение Программного комитета о докладе
В докладе вы узнаете про устройство крупнейшей социальной сети СНГ. Почему понадобилось реализовывать свои собственные базы данных, почему так важно локальное расположение баз данных по отношению к сервисам и как Congestion Control на прикладном уровне повысил отказоустойчивость системы.
Целевая аудитория
От бэкенд-разработчиков до системных архитекторов.
Тезисы
ВКонтакте ежедневно обслуживает десятки миллионов пользователей, позволяет обмениваться миллиардами сообщений и хранит десятки петабайт фотографий. Мы рассмотрим подходы и архитектуру решений, с помощью которых мы храним эти данные и предоставляем к ним эффективный доступ.
Расскажу, почему не используем сторонние базы данных, а сами пишем свои движки и как обеспечиваем доступность наших сервисов. Особое внимание уделю организации нашей mesh-архитектуры, устройству RPC и тому, как мы реализуем механизмы защиты от перегрузок и балансировку запросов без использования разделяемого стейта. В том числе подробно разберу технические детали реализации защитных механик.
Доклад будет полезен как с точки зрения опыта и идей построения больших систем, так и просто для того, чтобы узнать, как под капотом устроена крупнейшая социальная сеть СНГ.
Руководитель DB Engineering https://highload.ru/moscow/2022/abstracts/9578″ target=»_blank»]highload.ru[/mask_link]
VK Видео: архитектура сервиса на основе пользовательских метрик
Когда говорят о выборе архитектуры IT-системы, почти всегда упускают один ма-а-аленький нюанс: мы делаем продукты для пользователей, не для себя. А пользователям совершенно неважно, какая у сервиса архитектура. Никто в отзывах не ставит звёздочки за event-driven подход или классную реализацию service mesh — разве что в редких случаях, когда речь о продуктах для разработчиков.
Техническое совершенство — современные инструменты, предельная оптимизация, чистота кода и лаконичная, но гибкая и масштабируемая архитектура — всё это нужно нам, технарям. А как это всё связано со счастьем пользователей, как его измерять и учитывать при проектировании сервиса, разберёмся под катом.

В прошлой статье мы выяснили, как построить отказоустойчивую систему и обеспечить первое пользовательское требование — чтобы сервис всегда был доступен. Здесь поговорим о том, какие архитектурные решения помогут сделать любую контентную платформу лучше для пользователей.
Искать связь между архитектурой и пользовательским опытом будем на примере VK Видео. Эта платформа объединяет все видеосервисы компании VK, содержит 5 000 серверов, хранилище на 1 эксабайт данных, обеспечивает до 2,5 млрд просмотров видео в сутки и 4 Тбит/с трафика. Чтобы проследить формирование платформы, оглянемся назад и посмотрим, с чего всё начиналось. А затем обобщим главные пользовательские метрики и разберём основные составляющие архитектуры:
- Метрики пользовательского опыта
- Загрузка: скорость
- Транскодирование: качество
- Мгновенная доступность
- Раздача: надёжность, скорость, качество
- Воспроизведение и просмотр
- ML на службе у метрик пользовательского опыта
История одного видеосервиса
Архитектура нашей платформы начала складываться почти десять лет назад. Картинка ниже — это артефакт из 2013 года: тогда в Одноклассниках мы создали такую схему архитектуры. И теперь это почти единственная документация, которая сохранилась с тех пор.

Тогда у нас было 10 млн ежемесячной аудитории, которые генерировали 50 млн просмотров в сутки и 100 Гбит/с трафика. Все видео умещались в хранилище на 5 Пбайт, а для обслуживания платформы хватало 200 серверов. Это несколько процентов от сегодняшних объёмов, но в то время это были неплохие нагрузки, которые уже требовали серьёзного подхода к разработке.
За почти десять лет развития платформы мы сделали многое. Например, всего на год позже YouTube поддержали 4К, сделали сервис трансляций и показали рекордный стрим на 3 Тбит/сек (подробности см. в этом докладе). На этой же базе создали сервис коротких вертикальных видео VK Клипы — раньше YouTube Shorts и подобных форматов у других социальных сетей.
В 2021-м объединили видеоконтент из соцсетей и сервисов VK и официально запустили VK Видео. С момента запуска уже вышло много продуктовых релизов: ML-автосубтитры, нейросетевая технология NeuroHD для повышения разрешения и FPS, офлайн-просмотр, приложение для SmartTV и другие технологии, о которых ещё поговорим в этой статье.
Изначальная архитектура позволила нам реализовать все эти новшества без существенной перестройки и глобального изменения подхода. Она состоит из блоков, из которых выстраивается архитектура любого контентного сервиса:

- пользователи загружают контент на наши серверы;
- мы его как-то преобразуем, чтобы потом эффективнее показывать другим пользователям;
- сохраняем и раздаём.
У любого видеохостинга, сервиса для постинга фотографий или обмена музыкой примерно такая же структура. Но некоторые из них нравятся пользователям больше. Бывает, что мы бьёмся над качеством технических решений, а люди всё равно предпочитают конкурентов, у которых под капотом всё «на проволоке и изоленте». В этой статье попробуем разобраться, почему так и как связать счастье пользователей с техническими метриками.
Метрики пользовательского опыта
Есть разные метрики, которые помогают отслеживать, насколько аудитория довольна сервисом. Например, CSat (Customer Satisfaction Score) — это когда пользователь ставит приложению звёздочки в сторе; NPS (Net Promoter Score) — когда советует (или наоборот, не советует) сервис друзьям и коллегам; CSI (Customer Satisfaction Index) — баланс ожиданий, полученной пользы и качества; индекс TRI*M учитывает опыт использования, готовность рекомендовать продукт и продолжать работать с ним, а также мнение о преимуществах сервиса перед альтернативами. Все эти показатели можно и нужно измерять, проводя опросы.
Ещё есть множество технических метрик, на которые завязаны мониторинги. У всех нас прописаны SLI/SLO, мы следим за availability своих сервисов, измеряем и стараемся уменьшать latency, потерю пакетов, метрики приложения вроде PLT, TTI и LCP.
Свести всё это вместе можно через QoE — Quality of experience. Это обобщающая метрика родом из телекома. Она учитывает разные факторы, влияющие на восприятие системы целиком: от технических (задержек и качества сети) до характеристик устройства и самого пользователя (страна, образование). QoE обычно отображается в engagement (вовлечённости) и коррелирующем с ней счастье пользователя.
Очевидно, что никто не станет много и часто пользоваться сервисом, который не устраивает. Но при этом счастье и удовлетворённость зависят ещё и от цены, бренда и других факторов.
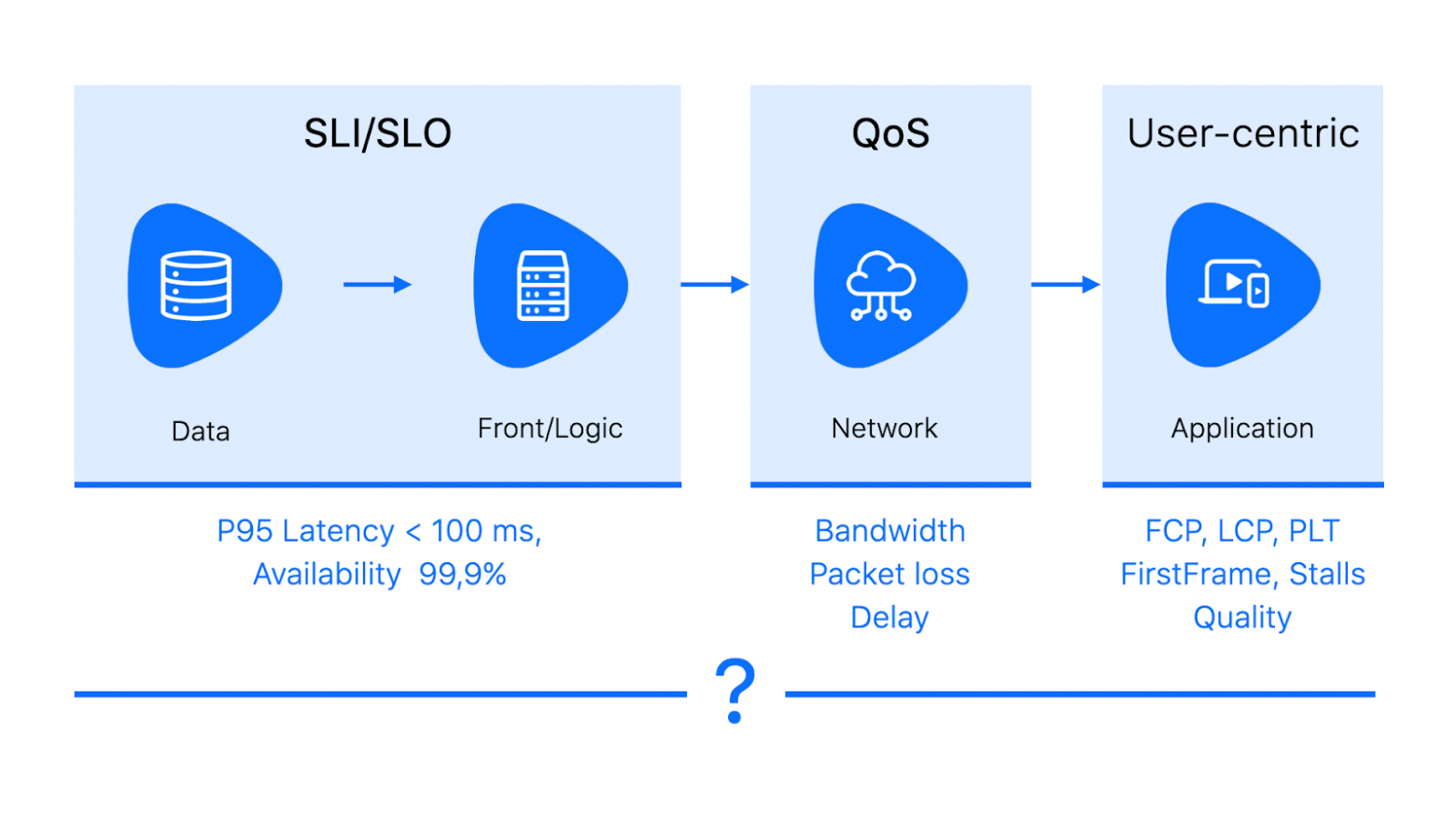
QoE сильно коррелирует с продуктовыми метриками. Отслеживая её, можно увидеть, какие изменения в архитектуре сервиса и технологические решения влияют на мнение пользователей о продукте. Самый простой способ измерять QoE — это собирать MOS (mean opinion score): периодически просить пользователей оценить сервис по пятибалльной шкале, от «отлично» до «плохо».
Если собрать достаточно много оценок в разных ситуациях, то можно попытаться найти корреляцию удовлетворённости пользователя и некоторых технических параметров. Например, в исследовании о QoE-driven видеостриминге в LTE-сетях приводится зависимость MOS от битрейта видео.
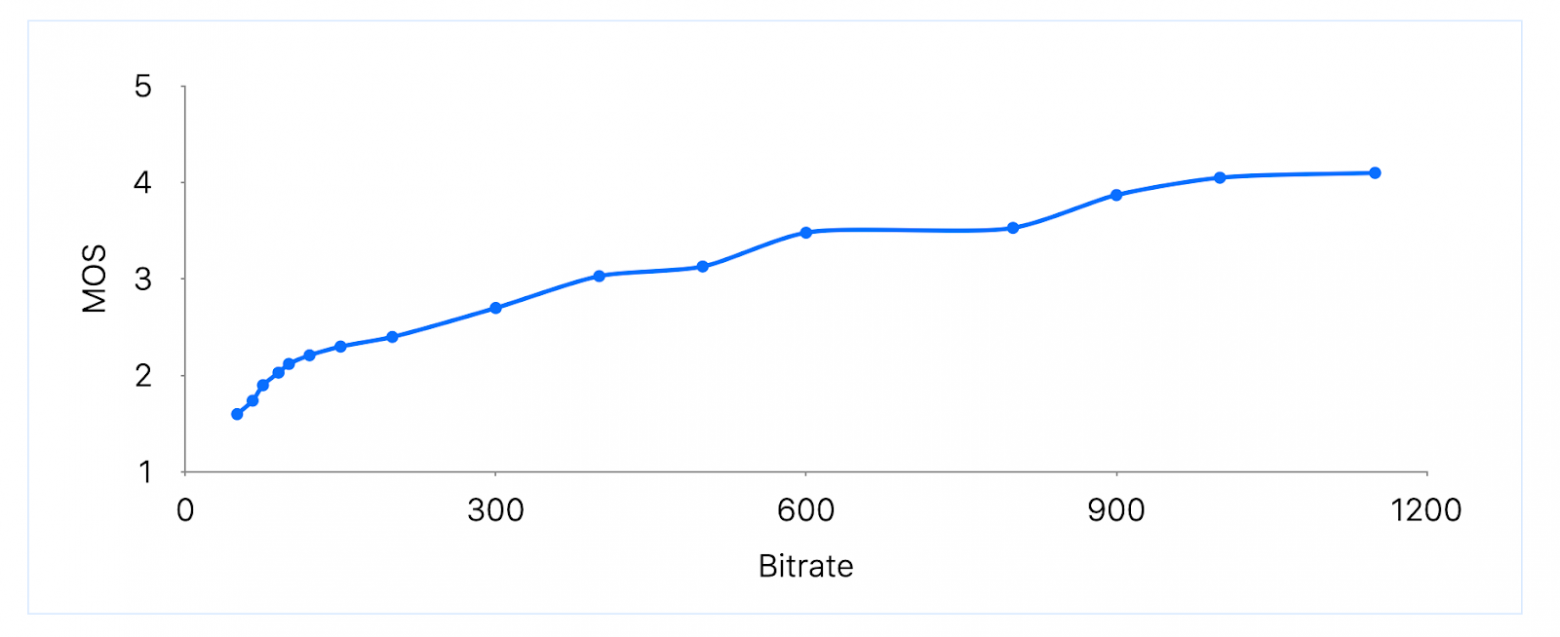
В другой статье MOS измеряют относительно FPS. Результаты холиварные: разница между 15 и 30 FPS очень существенная, повышение с 30 до 60 FPS даёт небольшой прирост MOS, а FPS больше 60 практически не улучшает пользовательский опыт. Но эти данные за 2011 год. Возможно, с тех пор мы стали придирчивее и лучше замечаем разницу в кадровой частоте.
Пользовательские ожидания год от года растут: то, что недавно было стандартом качества, скоро может стать неудовлетворительным. А ещё в определённых обстоятельствах метрики могут конфликтовать между собой. Например, при недостаточной пропускной способности сети нужно искать компромисс между битрейтом и FPS — и находить баланс тоже лучше через метрики и эксперименты.
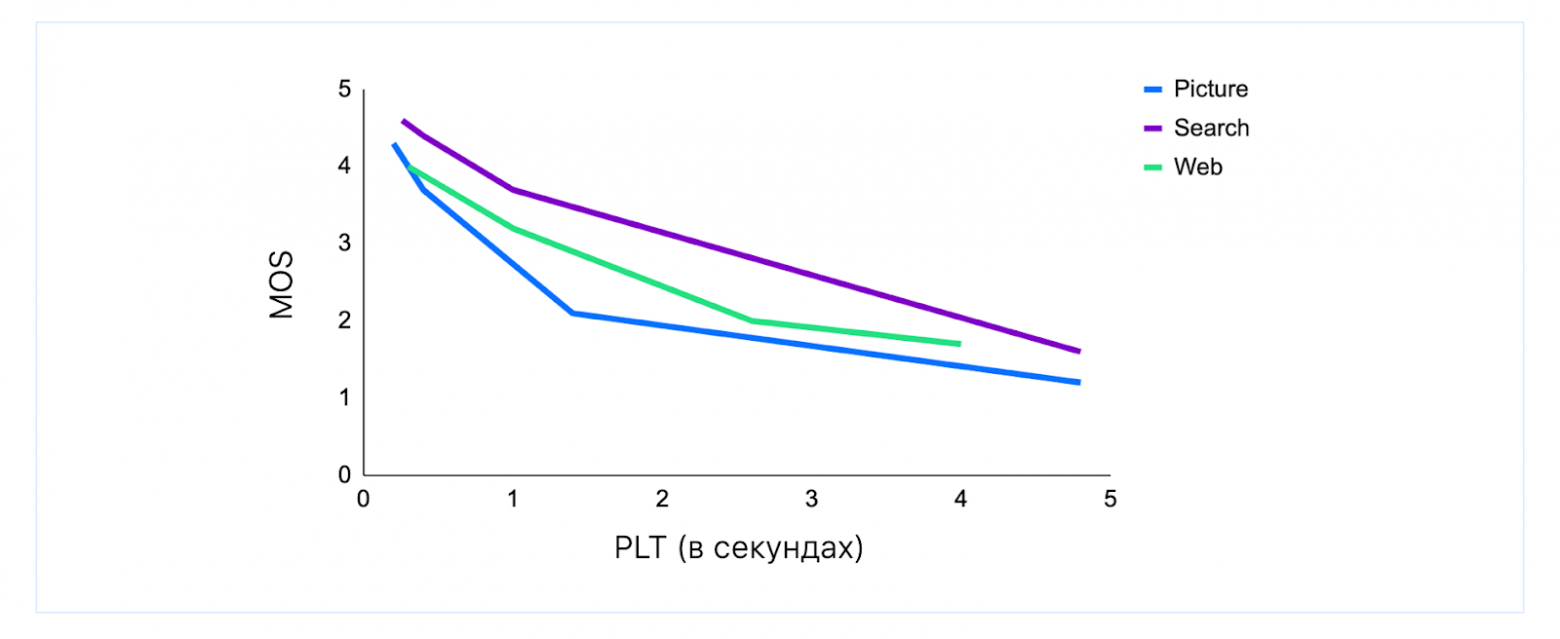
QoE также применима к веб-сервисам (см. статью Waiting times in quality of experience for web based services). В частности, можно увидеть, что к разным видам действий немного разные требования по Page Load Time (PLT): картинки должны загружаться мгновенно, а результатов поиска пользователи готовы секундочку подождать. Но в любом случае после ожидания больше 200 мс оценки начинают проседать.
Хорошие показатели QoE не гарантируют успех у пользователей, но без них завоевать аудиторию вряд ли получится. Дальше на примерах рассмотрим основные составляющие видеоплатформы и ключевые характеристики, влияющие на QoE.
Загрузка: скорость
Требования пользователей к загрузке и скачиванию файлов полностью описывает мультик двадцатилетней (!) давности.
Но с тех пор сильно изменились и размеры файлов, и ожидания от качества и скорости загрузки. Загрузка обязана быть отказоустойчивой и возобновляемой — как этого добиться, рассказываем в другой статье. Остаётся вопрос скорости: быстро — это как?
Метрики говорят, что если небольшой файл не загружается за 5–7 секунд, то пользователь начинает нервничать. На графике ниже пример с файлом в 25 Мбайт: сейчас это короткое видео, несколько фотографий или небольшая презентация. А ещё видно, что и для больших объёмов ждать 2 минуты никто не хочет.
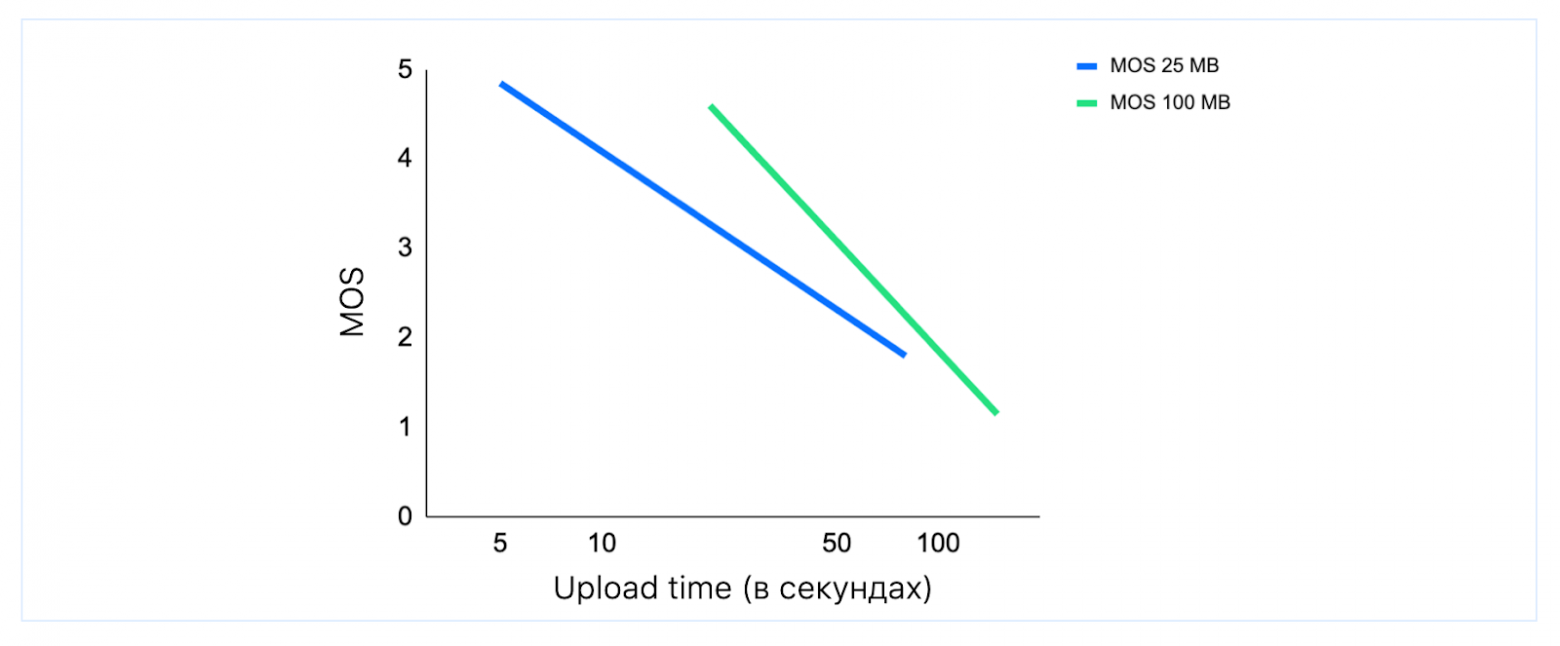
Причём рядовой пользователь не хочет и не должен разбираться, на чьей стороне проблема: дело в неустойчивой сети, слабом телефоне или сервис действительно плохо работает. Человек, скорее всего, просто останется недоволен приложением.
Чтобы ускорить upload, нужно эффективнее использовать пропускную способность. Вариантов для этого не так много: HTTP/1.1, HTTP/2 и HTTP/3.
HTTP/1.1 и загрузка чанками
Работает так: разбиваем файл на чанки; отправляем целиком первый блок данных POST-запросом, ждём ответа 200 OK (здесь появляется задержка в RTT — Round Trip Time), затем отправляем следующий блок новым POST-запросом.
Допустим, чанки размером по 4 Мбайта. Тогда, чтобы загрузить файл в 1 Гбайт, понадобится 256 лишних RTT, то есть 38 секунд при RTT = 150 мс (это, в принципе, немного: RTT может быть и 400 мс).
HTTP/2 и мультиплексирование
Конечно, если использовать мультиплексирование и в одно соединение запихнуть несколько потоков, будет быстрее.
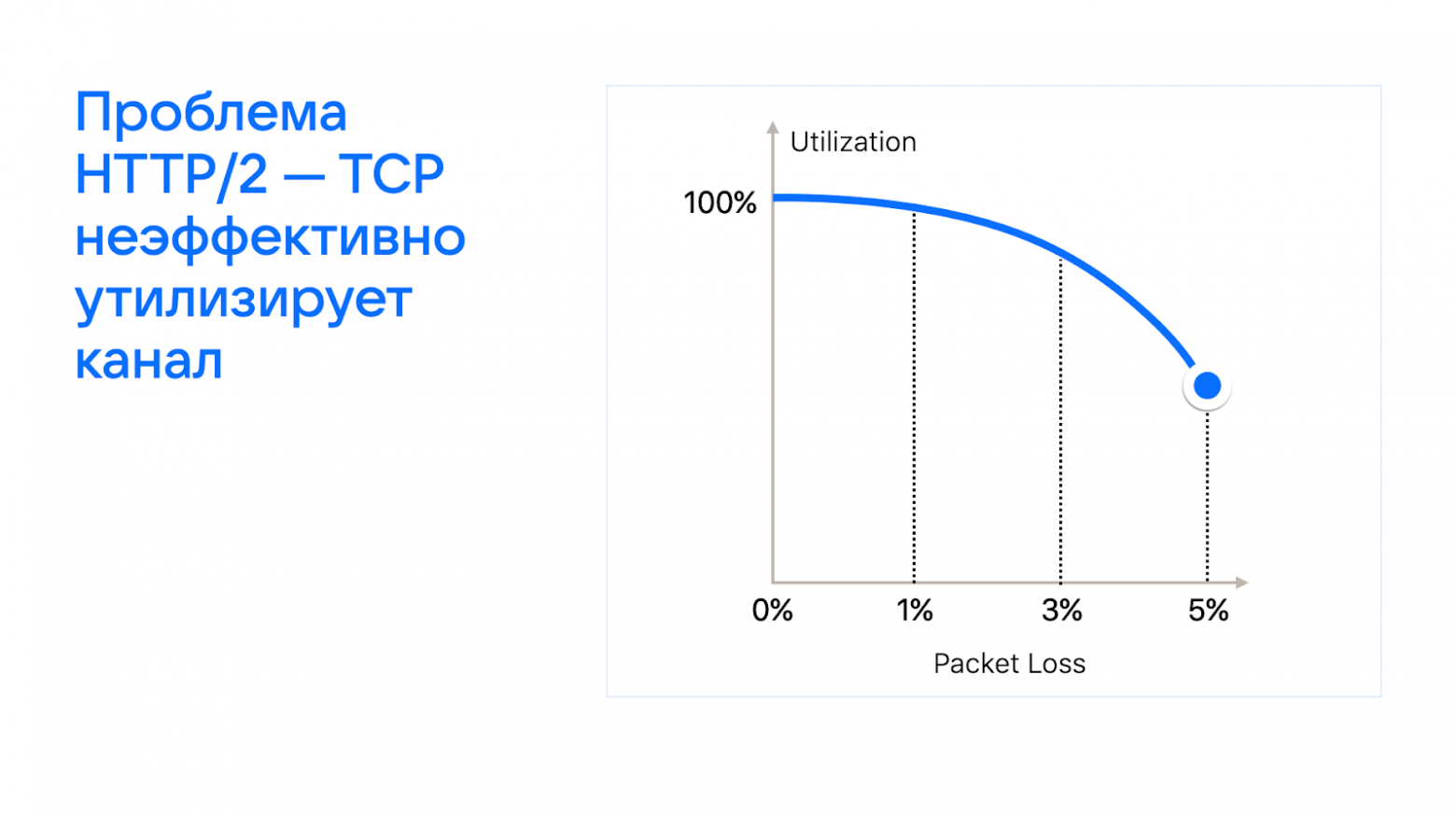
Проблема HTTP/2 в том, что, чем больше потеря пакетов, тем сильнее снижается эффективность утилизации сетевого канала (подробнее в статье о сетевом стеке).
HTTP 1.1 и параллельная загрузка
Проведя замеры, мы пришли к выводу, что лучшим вариантом для ускорения будет параллельная загрузка. То есть открывать столько соединений до сервера, сколько позволяет браузер или приложение, и в 4–6 потоков по частям загружать файл.

Причём такой способ как минимум не проигрывает относительно HTTP/3. Скорость загрузки будет либо такой же, либо даже выше — за счёт большего количества подключений и «не fair» распределения канала связи. К тому же TCP всё равно всегда нужен для фолбэка.
Если нет времени и ресурсов делать свой загрузчик, то можно использовать открытую библиотеку tus в связке с S3-хранилищем. Возможно, это будет не так эффективно и потребуется много доработок для обеспечения качества сервиса, но настройки для параллельной загрузки там тоже есть.
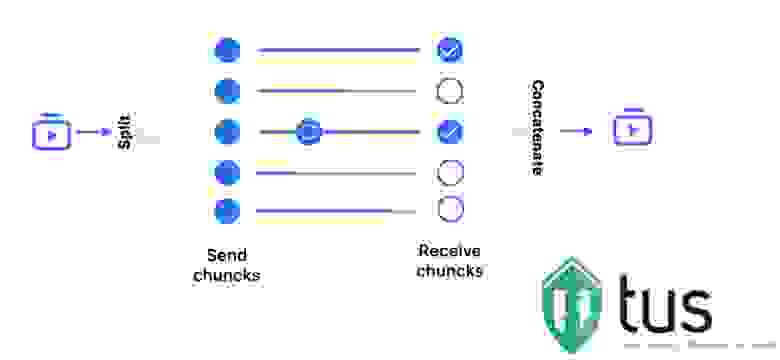
Что может пойти не так на этапе загрузки?
На объёмах до 14 млн новых роликов в сутки всё, что может пойти не так, рано или поздно стрельнёт. Для примера допустим, что мы в параллельной загрузке раздаём чанки потокам по одному, как игральные карты. То есть первый поток грузит первый, пятый, девятый чанки и так далее, второй — второй, шестой. Тогда, если один из потоков устанет и перестанет работать, получится слишком много дыр, список которых для ретрая просто переполнит HTTP header.

Максимальный размер HTTP header зависит от того, что вы используете — nginx или Apache. Но он в любом случае ограничен и может переполниться. Поэтому мы раздаём чанки потокам, по сути, последовательно — то есть ближайшие неотправленные.
Другая проблема возникает с DNS-запросами — она редкая, но коварная. Оказывается, что два DNS-запроса, отправленные подряд, могут зарезолвиться на разные IP и в разные дата-центры из-за TTL. Тогда, даже с учётом распределённого хранения состояния, загрузка становится медленнее — и в принципе возможно, что одни и те же чанки будут грузиться в разные дата-центры. При построении отказоустойчивой высоконагруженной системы нужно предусматривать и такие ситуации и уметь их разрешать.
В комплексе все меры, повышающие надёжность и ускоряющие загрузку, увеличили QoE нашего сервиса. Мы получили +7% успешных загрузок, то есть существенно повысили вовлечённость аудитории.
Специфика видеофайлов
Видео состоит из кадров. Если передавать его просто как набор полных кадров, то для 4К-видео в 60 FPS потребуется сеть с пропускной способностью на 18 Гбит/с. Это может обеспечить HDMI-кабель длиной несколько метров, но не обычная пользовательская интернет-сеть. Поэтому видео кодируется так, чтобы только часть кадров передавать в полном разрешении, а остальные кодировать через изменения относительно предыдущих. Так для 4К-видео становится достаточно 50 Мбит/с.
Каждые несколько лет появляется новый кодек, который примерно в два раза эффективнее предыдущего по степени сжатия, но и вычислительно затратнее. VP8, VP9 — открытые стандарты, которые разрабатываются в основном в Google. H.264, H.265, H.266 — лицензируемые форматы. AV1 разрабатывается «Альянсом за открытые медиа», в который входят AMD, Nvidia, Apple, Google, Microsoft и многие другие компании.
Кодек
Год
Эффективность относительно предыдущего
Аппаратная поддержка на сервере
Android
iOS
decoder
encoder
decoder
encoder
Источник: temofeev.ru