Здравствуйте уважаемый посетитель!
При создании и развитии сайта не обойтись без графического редактора. Этот инструмент необходим для формирования и обработки различных графических элементов, без которых сайт попросту не сможет существовать. Поэтому в наборе инструментов вебмастера графический редактор занимает важнейшее место.
В статье Устанавливаем бесплатный графический редактор GIMP речь пойдет о бесплатной программе GIMP, которая позволяет в полной мере решать вопросы по созданию элементов дизайна веб-страниц. И будет показано, как ее установить на локальный компьютер.
Кроме того здесь можно будет посмотреть, как в этот редактор добавить встроенное «Руководство пользователя», а также приведен бесплатный видеокурс, где можно поближе с ним познакомиться.
Для тех же, кто хочет заниматься дизайном на платном Adobe Photoshop (фотошоп), здесь также упомянут и такой вариант, основанный на использовании продления льготного бесплатного периода фотошопа на неопределенное время.
Лучшая база данных (объективно)
Cайт на практическом примере

Здесь можно посмотреть текущее состояние сайта, создаваемого в рамках цикла статей Самописный сайт с нуля своими руками.
Исходные файлы данного сайта можно скачать из прилагаемых к статьям дополнительных материалов.
| Вы здесь: Главная → Сборник статей → Работа с базой данных MySQL |
Перечень статей раздела Работа с БД MySQL:
Создаем базу данных MySQL
- Зачем нужна база данных
- Что из себя представляет база данных MySQL
- Создаем базу данных на локальном веб-сервере Denwer
- Создаем базу данных на хостинге
Здравствуйте уважаемый посетитель!
Прежде чем приступить к очередной теме создания сайта, хочу извиниться за задержку в написании статей. Но, как говорится, причина уважительная, так как связанно это было с работой по другим важным проектам. Надеюсь, в дальнейшем, дела насущные позволят мне рассмотреть все основные заявленные вопросы по развитию сайта в штатном режиме, с периодичностью 1-2 статьи в неделю.
Этой статьей начинается следующая часть сборника «Сделай сайт с нуля своими руками», которая в основном будет направлена на развитие и оптимизацию сайта, наполнение его контентом и необходимым функционалом.
А для того, чтобы в дальнейшем иметь возможность полноценно развивать сайт нам будет не обойтись без рассмотрения такого важного вопроса, как работа с базой данных MySQL (в дальнейшем для обозначения базы данных MySQL будет также встречаться аббревиатура «БД»).
В данной статье мы создадим базу данных на локальном веб-сервере Denwer и на хостинге, на котором размещен наш сайт.
Дальше, по ходу работ, будем формировать необходимые таблицы и скрипты, которые будут выполнять функцию хранения и обработки данных, получаемых при работе определенных блоков сайта.
Что такое базы данных? ДЛЯ НОВИЧКОВ / Про IT / Geekbrains
Подключаем базу данных MySQL с использованием процедурного и объектно-ориентированного стиля MySQLi
- Общие вопросы по подключению к БД
- Отличие в подключении к БД на локальном веб-сервере и на хостинге
- Подключение к базе данных с использованием процедурного интерфейса
- Подключение к базе данных объектно-ориентированным стилем
- Исходные файлы сайта
Здравствуйте уважаемый посетитель!
Сегодня будем заниматься подключением базы данных MySQL, которую создали в прошлой статье, через PHP с помощью современного модуля MySQLi. Особенность этого расширения в том, что в отличие от устаревшего MySQL, оно поддерживается всеми актуальными версиями PHP, включая последнюю 7.0.
Причем делать это будем двумя вариантами, используя, как привычной процедурный интерфейс (наподобие функций, которые использовались в старом расширении MySQL), так и объектно-ориентированный стиль взаимодействия с MySQL.
Оба эти варината рабочие, а каким пользоваться, может каждый выбрать для себя самостоятельно, кому какой будет удобнее.
Создаем таблицы MySQL c помощью phpMyAdmin, SQL-команд и в PHP
- Определение основных параметров создаваемой таблицы
- Создание таблицы с помощью интерфейса phpMyAdmin
- Создание таблицы с помощью SQL-запросов
- Создание таблицы MySQL в PHP
- Исходные файлы сайта
Здравствуйте уважаемый посетитель!
В прошлых статьях мы создали и подключили базу данных MySQL. Но для того чтобы с ней можно было реально работать, необходимо создать таблицы для записи, извлечения и обновления хранящейся в них информации.
В данной статье будут рассмотрены три возможных способа создания таблиц MySQL, а именно: с использованием интерфейса phpMyAdmin, c помощью SQL-запросов, а также используя модуль MySQLi PHP.
Конечно, нет необходимости постоянно использовать все спосбы, каждый сможет выбирать для себя то, что ему удобнее. Но, данная информация о разных возможностях, думаю, для многих будет интересна.
В связи с чем, я и решил более полно отразить данную тему. Тем более, что сейчас в интернете по этому вопросу часто можно встретить много устаревшей информации, либо большое количество перепечаток из разной справочной литературы.
При этом следует отметить, что наиболее часто из перечисленных способов используется первые два — с использованием интерфейса phpMyAdmin и c помощью SQL-запросов. Причем первый из них, на мой взгляд, более удобен для небольших таблиц. А использование SQL-запросов, наверное, можно оставить для создания более сложных, с большим количеством полей.
Третий способ — через PHP, встречается значительно реже, в основном, при необходимости создания таблиц программно, при выполнении каких-либо алгоритмов.
Также следует учесть, что порядок создания таблиц MySQL на локальном веб-сервере Denwer аналогичен и, практически, ничем не отличается от тех процедур, которые выполняются на хостинге. Поэтому, все выполняемые здесь действия будут проводиться на локальном веб-сервере. Повторения же подобных операций на хостинге рассматриваться не будет.
Наверное, такой значительный объем материала следовало бы разбить на три отдельных статьи. Но, собранная информация по этой теме в одном месте, думаю, будет более удобна для ее использования.
Вводим и копируем данные в БД MySQL с помощью phpMyAdmin
- Ввод данных в таблицу с помощью интерфейса phpMyAdmin
- Создание копии таблицы MySQL на локальном веб-сервера
- Импорт таблицы MySQL в БД хостинга
- Исходные файлы сайта
Здравствуйте уважаемый посетитель!
Сегодня будем вводить данные в таблицы MySQL с использованием интерфейса phpMyAdmin на локальном веб-сервере Denwer самым простым способом, в ручную, выбирая с помощью клавиатуры необходимые поля и записывая в них нужную информацию.
Что же касается ввода данных на хостинге, то в этом случае все действия аналогичны. Поэтому отдельного такого рассмотрения для хостинга не имеет смысла и в статье не предусмотрено.
Вместо этого, мы выполним довольно полезную операцию копирования таблиц MySQL из БД локального веб-сервера в БД хостинга и наоборот. Причем сделаем это наиболее простым способом, используя все то же приложение phpMyAdmin.
Такая процедура довольно удобна для сохранения данных MySQL, так как этим способом можно копировать не только определенные таблицы, но всю базу данных. А при наличии копии сайта на локальном веб-сервере, такая возможность существенно упрощает отладку и техническую поддержку действующего сайта.
Записываем данные MySQL с использованием SQL-запросов
- Формирование SQL-запроса
- Выполнение SQL-запроса в phpMyAdmin
- Исходные файлы сайта
Здравствуйте уважаемый посетитель!
Сегодня, в отличие от предыдущей статьи, будем записывать на локальном веб-сервере аналогичную информацию в таблицу MySQL не в ручную в веб-приложении phpMyAdmin, а с помощью специальных команд на языке SQL (SQL-запросы).
Что же касается записи данных в БД на хостинге, то в этом случае все действия аналогичны. Поэтому отдельного рассмотрения этих вопросов для хостинга здесь приводиться не будет.
Следует отметить, что все способы по записи данных, которые рассматриваются в этом цикле статей востребованы и применяются в зависимости от требуемых задач.
Так, например, если нужно создать незначительное количество записей, или сделать небольшие изменения в них, то вполне возможно это сделать в ручную через интерфейс phpMyAdmin, записывая значения в соответствующие поля таблицы.
А, если потребуется ввести большое количество данных, составляющее десятки и сотни строк таблицы, то, конечно удобнее будет это сделать не перебирая в ручную все ячейки строк, а выполнить соответствующую команду SQL с предварительно заполненными парамерами.
Ну, а вариант с использованием PHP, который будет рассмотрен в следующей статье незаменим, если необходимо сохранять данные, полученные в результате работы каких-либо программ. Например, при регистрации пользователя запись аккаунта должна выполняться программно, без какого-то ручного вмешательства.
Поэтому, все рассматриваемые здесь способы записи данных хороши каждый по-своему, и каждый способ в какой-то момент может быть использован при работе с базой данных MySQL.
В связи с чем и было решено этим вопросам уделить значительное внимание, чтобы можно было поближе познакомиться с каждым из этих способов на живых примерах.
Учитывая, что объем материала при таком довольно подробном рассмотрении не позволяет изложить его в одной статье, то данную тему по записи данных в таблицы MySQL пришлось разбить на три отдельные статьи.
Записываем данные MySQL с использованием PHP
- Записываем данные одной строки в таблицу MySQL
- Составляем PHP-скрипт для записи всех строк таблицы
- Составляем отдельную функцию записи данных в таблицу url_php
- Исходные файлы сайта
Здравствуйте уважаемый посетитель!
В предыдущих статьях мы рассмотрели возможность ввода данных MySQL в веб-интефейсе phpMyAdmin двумя способами — в ручную, записывая информацию в каждую ячейку таблицы и с помощью подготовленного SQL-запроса. Сегодня же рассмотрим еще один вариант, используя для этого PHP.
Как отмечалось ранее, такой способ не заменим при сохранении результатов работы каких-либо программ. Обычно в таких случаях в каждом запросе производится добавление одной новой записи или изменение или удаление существующей.
Но, так как в нашем случае требуется записать сразу несколько строк, то здесь для демонстрации такой возможности мы сначала проверим запись в таблицу всего лишь одной строки, а затем составим PHP-скрипт, который поочередно, обращаясь к соответствующей функции сделает это со всеми остальными строками.
Таким образом мы проверим с помощью PHP запись как одиночной строки, так и сразу нескольких за один раз выполнения скрипта.
А в завершении, преобразуем полученный PHP-скрипт, выделив из него фрагмент запроса к базе данных в отдельную функцию.
Такое подробное рассмотрение обусловлено тем, что при практической реализации составления различных программ, связанных с работой сайта, нередко приходится использовать подобные решения.
Надеюсь, что показанные здесь методы записи данных MySQL будут полезны особенно тем, кто делает только первые шаги в освоении этой довольно важной темы. Ведь умение записывать данные в таблицы MySQL с использованием PHP значительно расширяет возможности работы с сайтом.
Выводим данные из БД MySQL с помощью SQL-запросов
- Выборка одиночной уникальной строки с заданным условием
- Получение набора нескольких строк с сортировкой по заданному полю
Здравствуйте уважаемый посетитель!
В предыдущих статьях мы рассмотрели возможность записи данных в БД MySQL тремя разными способами:
- в веб-интефейсе phpMyAdmin, записывая в ручную информацию в каждую ячейку таблицы;
- с помощью подготовленных SQL-запросов;
- программно, используя функции модуля MySQLi PHP, составив для этого соответствующий скрипт.
А, теперь выполним обратные действия, посмотрим, как можно вывести данные из таблицы MySQL с помощью SQL-запросов.
Задачей данного материала является знакомство с основными моментами при работе с базой данных MySQL для того, чтобы в дальнейшем можно было практически использовать возможности этой информационной системы для добавления функциональности нашему сайту.
Поэтому, здесь мы более подробно остановимся всего лишь на двух, наиболее часто встречающихся в веб-прогаммировании вариантах извлечения данных, а именно: с начала выполним запрос выборки одиночной уникальной строки по заданному условию, а затем получим набор нескольких строк и отсортируем их по одному из полей.
Как ранее отмечалось, работа с базой данных MySQL в phpMyAdmin на хостинге, практически, ничем не отличается от действий на локальном веб-сервере, за исключением порядка входа в веб-приложение с соответствующим аккаунтом.
В связи с чем, вывод данных из БД MySQL здесь будет рассматриваться только для варианта с локальным веб-сервером «Denwer», который используется в нашем случае при создании сайта. Для хостинга будет все аналогично.
Выводим данные из БД MySQL в PHP
- Вывод одиночной строки (использование одномерного массива)
- Вывод набора строк по заданному условию (использование двумерного массива)
- Проверка наличия записи в таблице
- Исходные файлы сайта
Здравствуйте уважаемый посетитель!
В предыдущей статье мы рассмотрели возможность вывода записей MySQL с помощью SQL-запросов. При этом, результаты отображались на странице веб-приложения phpMyAdmin.
Такой способ получения данных полезен для просмотра содержимого БД MySQL, но явно недостаточен для того, чтобы можно было их использовать для работы сайта. В этом случае, вместо приложения phpMyAdmin, требуются другие инструменты.
В сайтостроении для этих целей обычно используют язык программирования PHP, где с помощью модуля MySQLi данные можно извлекать непосредственно в PHP. А, далее с ними работать как с обычными переменными.
Следует отметить, что наиболее часто встречающиеся PHP-функции, предназначенные для вывода данных из таблиц MySQL, по виду возвращаемого результата можно разделить на три варианта:
- когда результатом выполнения SQL-запроса может быть лишь только одна строка;
- в случае, если результатом выборки может быть множество строк.
- при выполнении запроса на проверку наличия записи в таблице по заданному условию.
В первом случае PHP-функцией возвращается одномерный ассоциативный массив, ключами которого будут являться наименования полей таблицы.
В варианте со множеством строк на выходе получается двумерный массив, в котором первый ключ определяет порядковый номер строки из набора, а второй — наименования полей.
В случае поверки наличия записи в таблице, функция возвращает значение переменной типа «bool», где «TRUE» — запись существует, «FALSE» — отсутствует.
При этом, на основе приведенных здесь вариантов PHP-кода можно получать различные функции под конкретные задачи, меняя для этого лишь текст SQL-запроса и соответствующие параметры.
Следует отметить, что для того, чтобы в создаваемых функциях более наглядно была показана связка языков PHP и SQL, во всех рассматриваемых здесь вариантах будут сознательно использованы те же самые SQL-запросы, которые применялись в предыдущей статье.
Таким образом, мы рассмотрим наиболее часто используемые варианты PHP-функций, предназначенных для вывода данных MySQL, и с помощью соответствующих PHP-скриптов перенесем полученные результаты на на экран браузера.
Источник: sayt-sozdat.ru
Поддельные пиратские фильмы штурм базы данных YouTube
FLAT EARTH: To The Edge And Back (Official Movie) (Сентябрь 2023)

Создание базы данных Access 2010 из шаблона является надежным вариантом, но шаблоны не всегда доступны. Вот как создавать базы данных с нуля.
База данных и экземпляр базы данных

Экземпляр базы данных представляет собой всю среду базы данных, но поставщики могут использовать этот термин определенным образом.
Как провести мозговой штурм — мозговой штурм идей — муза

Нужно придумать чертовски хорошие идеи?
Источник: ru.go-travels.com
Анализ данных Youtube в реальном времени с Apache NiFi, Kafka и Spark Streaming

В этой статье для дата-инженеров рассмотрим пример конвейера анализа потокового видео с Youtube-каналов на Kafka, Spark Streaming и Elasticsearch c Kibana, связанных через процессоры Apache NiFi.
Постановка задачи: ETL-конвейер анализа потоковых данных с Youtube
Потоковые данные непрерывно генерируются тысячами источников, которые отправляют записи одновременно и в небольших размерах (порядка килобайт). Чаще всего такими данными являются лог-файлы от клиентов мобильных или веб-приложений, покупки в электронной торговле, события пользовательского поведения на сайтах, действия онлайн-игроков, информация из соцсетей, финансовых торговых площадок или геопространственных сервисов, а также телеметрия с IoT-устройств или оборудования в дата-центрах. Чтобы проанализировать эти данные, можно составить конвейер потокового маршрутизатора Apache NiFi из следующих шагов:
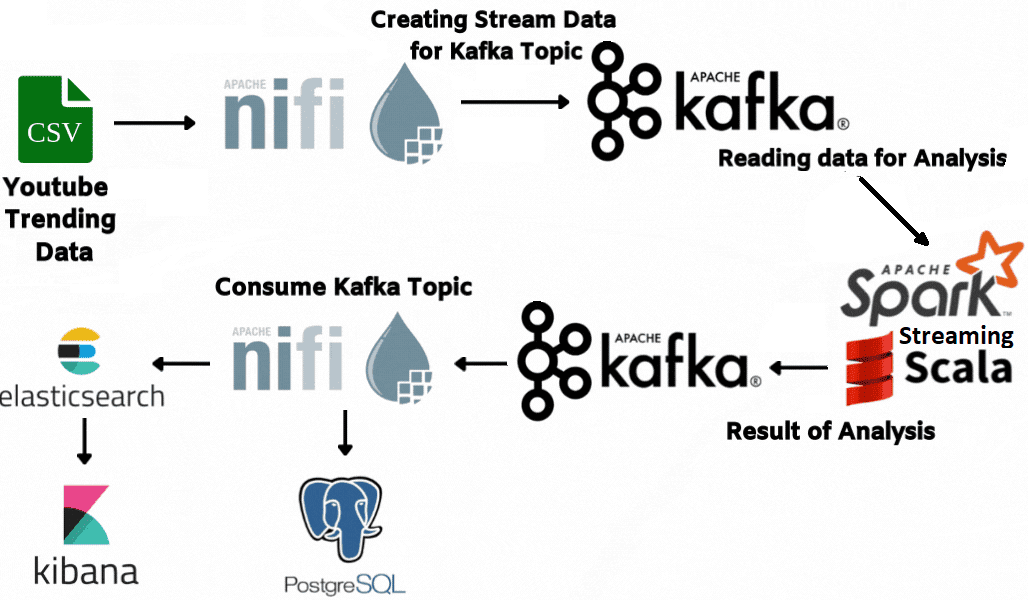
- генерация потоковых данных;
- анализ потоковых данных с помощью Spark Streaming;
- запись проанализированных данных в топики Apache Kafka;
- визуализация результатов анализа на наглядном дэшборде Kibana в реальном времени.
Для примера возьмем в качестве источника исходных данных о CSV-файл с трендами видеохостинга Youtube. Конвейер генерации потоковых данных из этого файла можно представить последовательностью нескольких обработчиков-процессоров Apache NiFi.

Сперва воспользуемся NiFi-процессором под названием GetFile. Он получает файлы из локальной файловой системы и создает потоковый файл (FlowFile), который далее будет обрабатываться другими процессорами. При этом NiFi будет игнорировать файлы, для которых отсутствуют права хотя бы на чтение.
Далее преобразуем каждую запись из этого CSV-файла в JSON и создадим топик Kafka. Для этого воспользуемся процессором ConvertRecord. Он преобразует записи из одного формата данных в другой с помощью настроенных сервисов чтения (Reader) и записи (Writer) данных. Reader и Writer должны быть настроены так, чтобы схемы данных имели одинаковые имена полей.
Типы полей не обязательно должны быть одинаковыми, если значение поля можно преобразовать из одного типа в другой. Например, если во входной схеме данных есть поле «баланс» типа double, то в выходной схеме оно может быть типа string, double или float. Если во входных данных есть какое-либо поле, которого нет в выходных данных, это поле будет исключено в выходе. Если какое-либо поле указано в выходной схеме, но отсутствует во входных данных или их схеме, то это поле не появится в выходных данных или будет иметь нулевое значение, в зависимости от модуля записи.
Эксплуатация Apache NIFI
Код курса
NIFI3
Ближайшая дата курса
20 декабря, 2023
Длительность обучения
24 ак.часов
Стоимость обучения
66 000 руб.
После преобразования данных в JSON разделим каждую на запись перед публикацией в топики Kafka, чтобы отправлять в них фрагментированные небольшие записи вместо одного большого сообщения. Для этого воспользуемся NiFi-процессором SplitJson, который разбивает JSON-файл на несколько отдельных потоковых файлов для элемента массива, заданного выражением JsonPath. Каждый сгенерированный FlowFile состоит из элемента указанного массива и передается в отношение «разделение» (relationship ‘split’), а исходный файл передается в исходное отношение (‘original’ relationship). Если указанный JsonPath не найден или не оценивается как элемент массива, исходный файл перенаправляется на «сбой», и потоковые файлы не создаются.
Наконец, опубликуем каждую из записей JSON в топике Kafka с помощью процессора PublishKafka_2_0. Он отправляет содержимое FlowFile в виде сообщения в Apache Kafka с помощью Kafka 2.0 Producer API. Отправляемые сообщения могут быть отдельными FlowFile или могут быть разделены с помощью заданного пользователем разделителя, например новой строки. Содержимое FlowFile становится содержимым сообщения Kafka, которому дополнительно назначается ключ с помощью свойства .
Процессор позволяет пользователю настроить необязательный демаркатор сообщений, который можно использовать для отправки множества сообщений в потоковый файл. Например, с помощью разделителя n можно указать, что содержимое FlowFile должно использоваться для отправки одного сообщения на строку текста. Он также поддерживает многосимвольные разделители.
Если свойство разделителя не установлено, все содержимое FlowFile будет отправлено как одно сообщение. При использовании разделителя, если некоторые сообщения успешно отправлены, а другие – нет, результирующий FlowFile будет считаться неудачным и помечен соответствующими атрибутами.
Одним из таких атрибутов является failed.last.idx, указывающий индекс последнего сообщения, которое было успешно подтверждено Kafka. Если разделитель не используется, значение этого индекса равно -1. Это позволит процессору PublishKafka повторно отправлять неподтвержденные сообщения только при следующей повторной попытке. Также этот процессор NiFi имеет свойство Security Protocol, чтобы пользователь мог указать протокол для связи с брокером Kafka.
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
8 ноября, 2023
Длительность обучения
24 ак.часов
Стоимость обучения
66 000 руб.
Далее можно анализировать потоковые данные, считывая из из топика Kafka в реальном времени с помощью приложения, поддерживающего Streaming-обработку. Как это сделать с помощью Spark Streaming, мы рассмотрим далее.
Анализ потоковых данных с помощью Spark Streaming
Когда подходящая среда для обработки потоковых данных в виде топика Kafka готова, можно приступить к их анализу в режиме реального времени. Цель анализа в нашем примере с Youtube-каналами – это ответить на следующие вопросы:
- какие самые просматриваемые каналы?
- какие категории больше всего нравятся?
- какие самые просматриваемые категории?
- какие самые больше всего нравятся?
В нашем примере Spark Scala для анализа данных. После запуска сеанса Spark следует подключиться к топику Kafka, где находятся потоковые данные.
// to start spark streaming ./spark-shell —packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.1 . // Connecting Kafka val UsYoutubeDf = spark.readStream.format(«kafka») .option(«kafka.bootstrap.servers», «localhost:9092») .option(«subscribe», «usyoutube»).load
Далее следует определить соответствующую схему данных:
// import StructType for Schema such as StringType, IntegerType, BooleanType import org.apache.spark.sql.types._ // Defining Schema val activationSchema = StructType(List( StructField(«video_id», StringType, true), StructField(«title», StringType, true), StructField(«published_at», StringType, true), StructField(«channel_id», StringType, true), StructField(«channel_title», StringType, true), StructField(«category_id», IntegerType, true), StructField(«trending_date», StringType, true), StructField(«view_count», IntegerType, true), StructField(«likes», IntegerType, true), StructField(«dislikes», IntegerType, true), StructField(«comment_count», IntegerType, true), StructField(«comments_disabled», BooleanType, true), StructField(«ratings_disabled», BooleanType, true), StructField(«category_title», StringType, true))) // JSON to df val youTubeSchemaDf = UsYoutubeDf .select(from_json($»value».cast(«string»), activationSchema) .alias(«usYoutube»)) .select(«usYoutube.*») youTubeSchemaDf.printSchema /* root |— video_id: string (nullable = true) |— title: string (nullable = true) |— published_at: string (nullable = true) |— channel_id: string (nullable = true) |— channel_title: string (nullable = true) |— category_id: integer (nullable = true) |— trending_date: string (nullable = true) |— view_count: integer (nullable = true) |— likes: integer (nullable = true) |— dislikes: integer (nullable = true) |— comment_count: integer (nullable = true) |— comments_disabled: boolean (nullable = true) |— ratings_disabled: boolean (nullable = true) |— category_title: string (nullable = true) */
Если нужно ответить на 4 вышепоставленных вопроса, то следует публиковать результаты в 4 разных топиках Kafka:
- Каналы с наибольшим числом просмотров;
- Каналы с наибольшим числом лайков;
- Категории каналов с наибольшим числом просмотров;
- Категории каналов с наибольшим числом лайков.
К примеру, следующий код на Spark Scala позволит выявить каналы с наибольшим числом просмотров:
//mostviewedchannel val mostviewedchannelDf = youTubeSchemaDf .groupBy(«trending_date»,»channel_title») .agg(sum(«view_count»).as(«total_view_count_by_channel»)) .sort($»total_view_count_by_channel».desc) import org.apache.spark.sql.streaming.Trigger.ProcessingTime val mostviewedchannelDfQuery = mostviewedchannelDf .selectExpr(«CAST(trending_date as STRING)»,»CAST(channel_title AS STRING)», «CAST(total_view_count_by_channel AS INTEGER)», «to_json(struct(*)) AS value») .writeStream.format(«kafka») .option(«checkpointLocation», «/home/tugrulgkccc/consumermostviewedchannel») .option(«failOnDataLoss», «false») .outputMode(«complete») .option(«kafka.bootstrap.servers», «localhost:9092») .option(«topic», «mostviewedchannel»).start()
Источник: bigdataschool.ru