Наши пользователи пишут друг другу сообщения, не зная усталости.
Это довольно много. Если бы Вы задались целью прочитать все сообщения всех пользователей, это бы заняло больше 150 тысяч лет. При условии, что Вы довольно прокачанный чтец и тратите на каждое сообщение не больше секунды.
При таком объёме данных критически важно, чтобы логика хранения и доступа к ним была построена оптимально. Иначе в один не такой уж и прекрасный момент может выясниться, что скоро всё пойдёт не так.
Для нас этот момент наступил полтора года назад. Как мы к этому пришли и что получилось в итоге — рассказываем по порядку.
История вопроса
В самой первой реализации сообщения ВКонтакте работали на связке PHP-бэкенда и MySQL. Это вполне нормальное решение для небольшого студенческого сайта. Однако этот сайт безудержно рос и начал требовать оптимизировать структуры данных под себя.
В конце 2009 года было написано первое хранилище text-engine, а в 2010 на него перевели сообщения.
Что такое базы данных? ДЛЯ НОВИЧКОВ / Про IT / Geekbrains
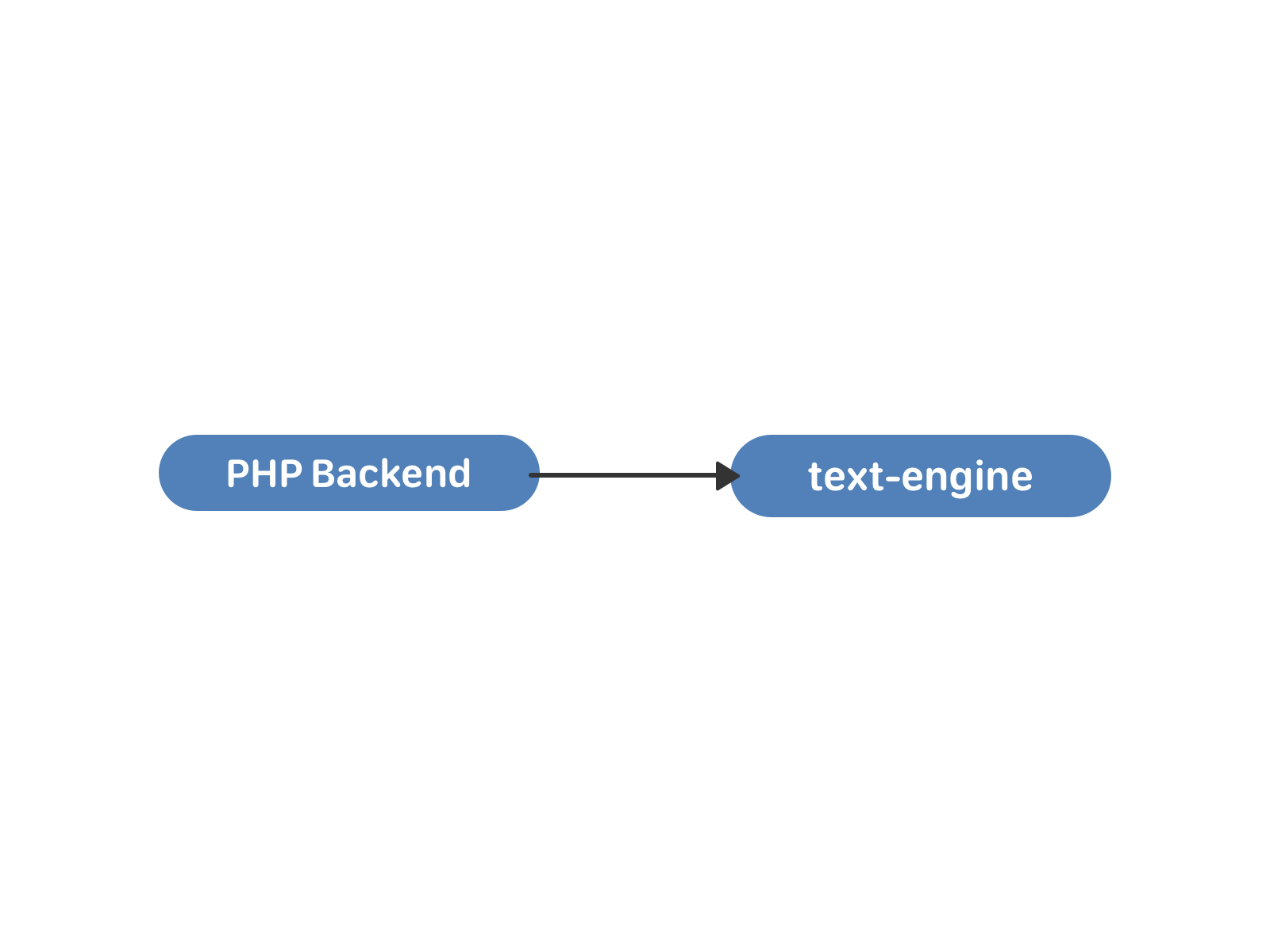
В text-engine сообщения хранились списками — своего рода «почтовыми ящиками». Каждый такой список определяется uid’ом — пользователем-владельцем всех этих сообщений. У сообщения есть набор атрибутов: идентификатор собеседника, текст, вложения и так далее. Идентификатор сообщения внутри «ящика» — local_id, он никогда не изменяется и назначается последовательно для новых сообщений. «Ящики» независимы и друг с другом внутри движка никак не синхронизируются, связь между ними происходит уже на уровне PHP. Посмотреть на структуру данных и возможности text-engine изнутри можно здесь.
Этого было вполне достаточно для переписки двух пользователей. Угадайте, что случилось потом?
В мае 2011 года ВКонтакте появились беседы с несколькими участниками — мультичаты. Для работы с ними мы подняли два новых кластера — member-chats и chat-members. Первый хранит данные о чатах по пользователям, второй — данные о пользователях по чатам. Кроме самих списков это, например, пригласивший пользователь и время добавления в чат.
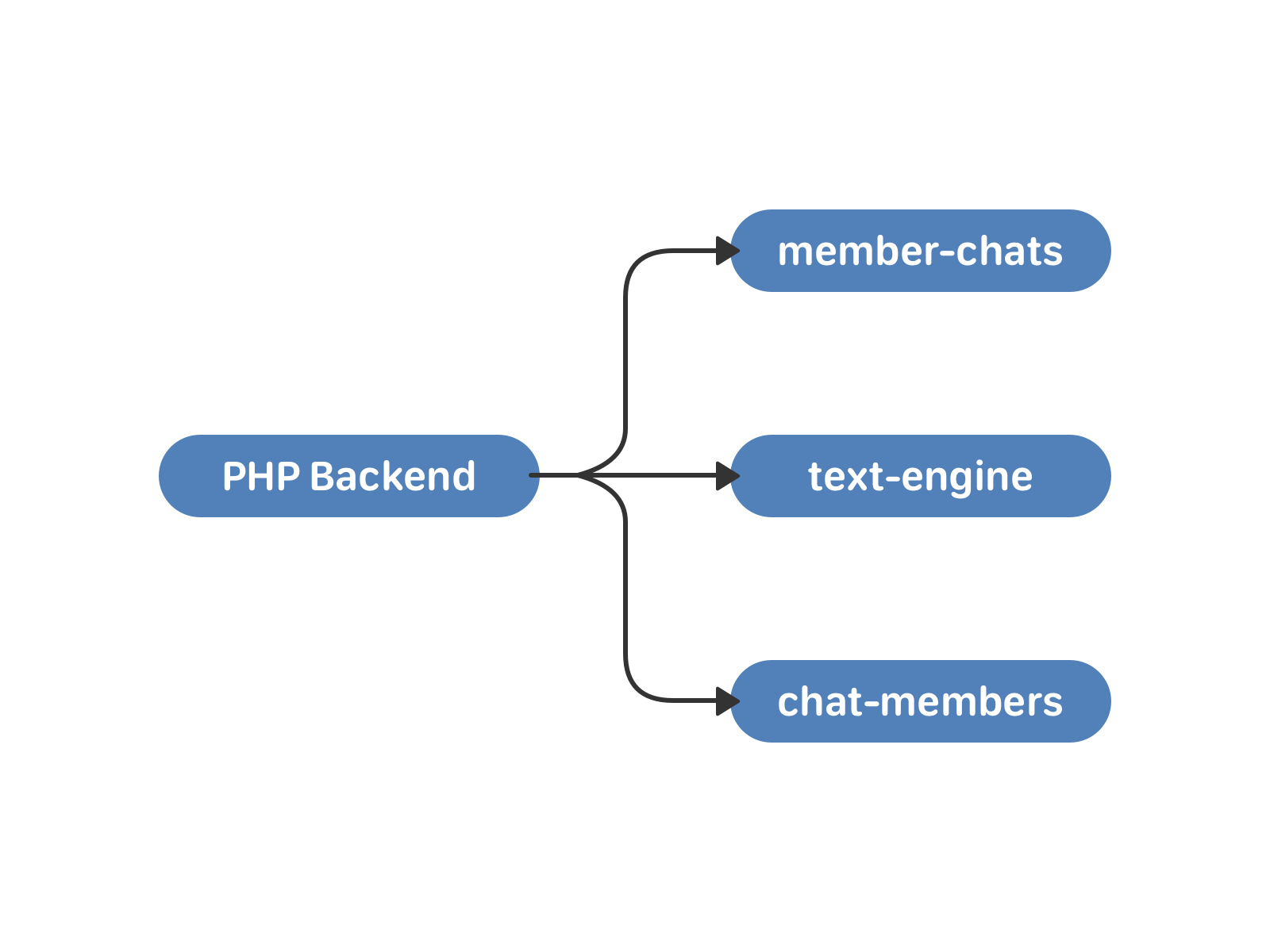
— PHP, давай отправим сообщение в чат, — говорит пользователь.
— Ну давай, , — говорит PHP.
В этой схеме есть минусы. Синхронизация по-прежнему возложена на PHP. Большие чаты и пользователи, которые одновременно отправляют сообщения в них — опасная история. Поскольку экземпляр text-engine зависит от uid, участники чата могли получать одно и то же сообщение с разницей во времени. С этим можно было жить, если бы прогресс стоял на месте.
Но не бывать такому.
В конце 2015 года мы запустили сообщения сообществ, а в начале 2016 — API для них. С появлением крупных чат-ботов в сообществах о равномерности распределения нагрузки можно было забыть.
Годный бот генерирует несколько миллионов сообщений в сутки — даже самые словоохотливые пользователи таким похвастаться не могут. А это значит, что некоторым экземплярам text-engine, на которых жили такие вот боты, стало доставаться по полной.
Слив базы данных Вконтакте [Описание]
Движки сообщений в 2016 году — это по 100 экземпляров chat-members и member-chats, и 8000 text-engine. Они размещались на тысяче серверов, каждый с 64 Гб памяти. В качестве первой экстренной меры мы увеличили память ещё на 32 Гб. Прикинули прогнозы. Без кардинальных изменений этого хватило бы ещё примерно на год.
Нужно либо разживаться железом, либо оптимизировать сами БД.
В силу особенностей архитектуры наращивать железо имеет смысл только кратно. То есть, как минимум удвоить количество машин — очевидно, это довольно дорогой путь. Будем оптимизировать.
Новая концепция
Центральная сущность нового подхода — чат. У чата есть список сообщений, которые относятся к нему. У пользователя есть список чатов.
Необходимый минимум — это две новые базы данных:

- chat-engine. Это хранилище векторов чатов. У каждого чата есть вектор сообщений, которые к нему относятся. У каждого сообщения есть текст и уникальный идентификатор сообщения внутри чата — chat_local_id.
- user-engine. Это хранилище векторов users — ссылок на пользователей. У каждого пользователя есть вектор peer_id (собеседников — других пользователей, мультичатов или сообществ) и вектор сообщений. У каждого peer_id есть вектор сообщений, которые к нему относятся. У каждого сообщения есть chat_local_id и уникальный идентификатор сообщения для этого пользователя — user_local_id.
Новые кластеры общаются между собой с помощью TCP — это гарантирует, что порядок запросов не изменится. Сами запросы и подтверждения для них записываются на жёсткий диск — поэтому мы можем восстановить состояние очереди в любой момент времени после сбоя или перезапуска движка. Поскольку user-engine и chat-engine это 4 тысячи шардов каждый, очередь запросов между кластерами будет распределяться равномерно (а в реальности её нет вообще — и это работает очень быстро).
При этом данные на самом жёстком диске изменяются только раз в сутки — глубокой ночью по Москве, когда нагрузка минимальна. Благодаря этому (зная, что структура на диске в течение суток постоянная) мы можем позволить себе заменить векторы на массивы фиксированного размера — и за счёт этого выиграть в памяти.
Отправка сообщения в новой схеме выглядит так:
- PHP backend обращается к user-engine с запросом на отправку сообщения.
- user-engine проксирует запрос в нужный экземпляр chat-engine, который возвращает в user-engine chat_local_id — уникальный идентификатор нового сообщения внутри этого чата. Затем chat_engine рассылает сообщение всем получателям в чате.
- user-engine принимает от chat-engine chat_local_id и возвращает в PHP user_local_id — уникальный идентификатор сообщения для этого пользователя. Этот идентификатор затем используется, например, для работы с сообщениями через API.
Но помимо собственно рассылки сообщений нужно реализовать ещё несколько важных вещей:
- Подсписки — это например, самые свежие сообщения, которые Вы видите, открывая список диалогов. Непрочитанные сообщения, сообщения с метками («Важные», «Спам» и т.д.).
- Сжатие сообщений в chat-engine
- Кэширование сообщений в user-engine
- Поиск (по всем диалогам и внутри конкретного).
- Обновление в реальном времени (Longpolling).
- Сохранение истории для реализации кэширования на мобильных клиентах.
Сообщения подразумевают большой объём информации, в основном текстовой, которую полезно уметь сжимать. При этом важно, чтобы мы могли точно разархивировать даже одно отдельное сообщение. Для сжатия сообщений используется алгоритм Хаффмана с собственными эвристиками — например, мы знаем, что в сообщениях слова чередуются с «не словами» — пробелами, знаками пунктуации, — а также помним о некоторых особенностях использования символов для русского языка.
Поскольку пользователей гораздо меньше, чем чатов, для экономии random-access запросов к диску в chat-engine мы кэшируем сообщения в user-engine.
Поиск по сообщениям реализован как диагональный запрос из user-engine ко всем экземплярам chat-engine, которые содержат чаты этого пользователя. Результаты объединяются уже в самом user-engine.
Что ж, все детали учтены, осталось перейти на новую схему — и желательно так, чтобы пользователи этого не заметили.
Миграция данных
Итак, у нас есть text-engine, который хранит сообщения по пользователям, и два кластера chat-members и member-chats, которые хранят данные о мультичатах и пользователях в них. Как от этого перейти к новым user-engine и chat-engine?
member-chats в старой схеме использовался преимущественно для оптимизации. Мы довольно быстро перенесли нужные данные из него в chat-members, и далее в процесе миграции он уже не участвовал.
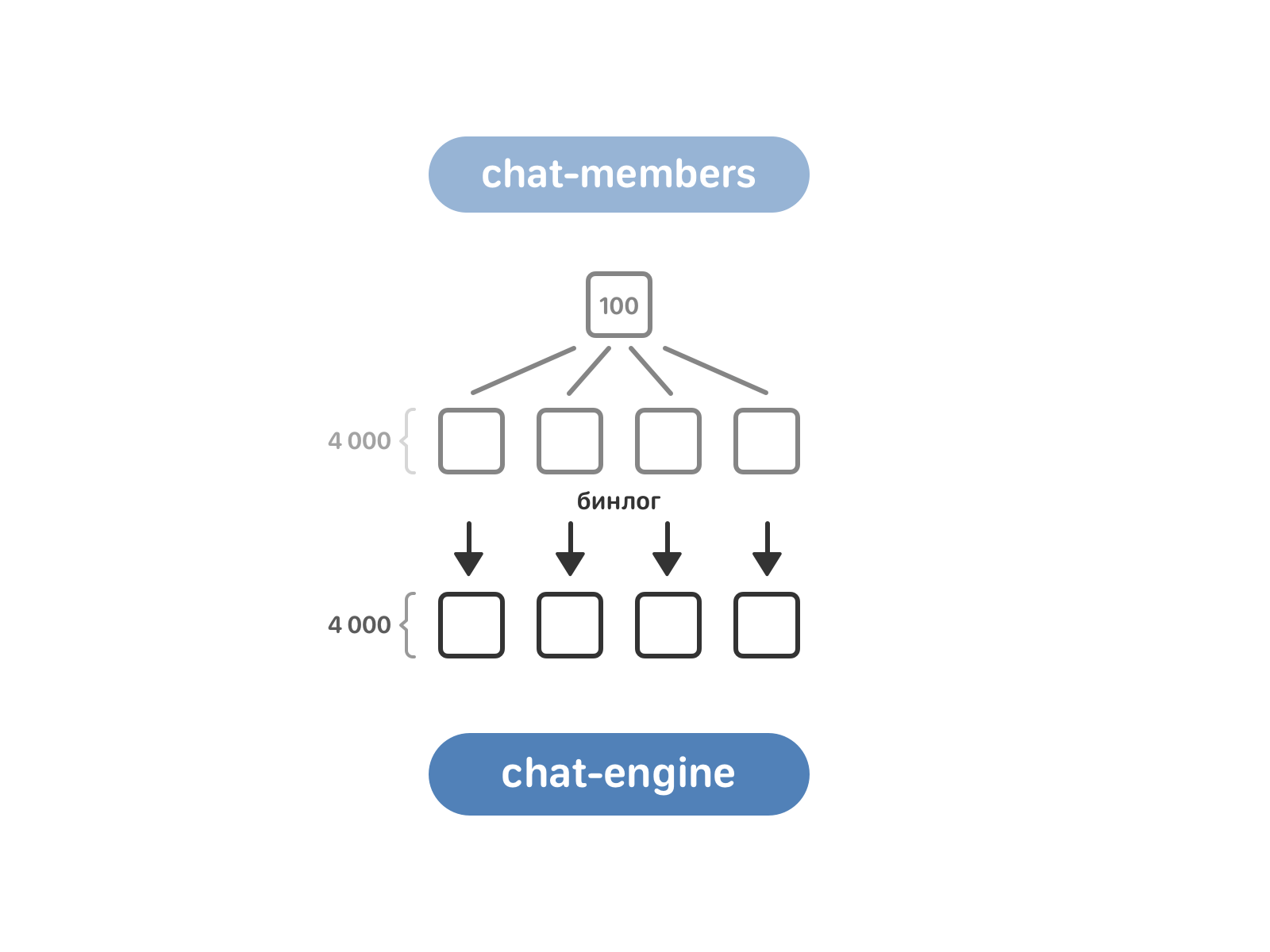
Очередь за chat-members. Он включает 100 экземпляров, в то время как chat-engine — 4 тысячи. Для переливки данных нужно привести их в соответствие — для этого chat-members разбили на те же 4 тысячи экземпляров, а после включили чтение бинлога chat-members в chat-engine.
Теперь chat-engine знает о мультичатах из chat-members, но ему пока ничего не известно о диалогах с двумя собеседниками. Такие диалоги лежат в text-engine с привязкой к пользователям. Здесь мы забирали данные «в лоб»: каждый экземпляр chat-engine запрашивал у всех экземпляров text-engine, есть ли у них нужный ему диалог.
Отлично — chat-engine знает, какие есть мультичаты, и знает, какие есть диалоги.
Нужно объединить сообщения в мультичатах — так, чтобы в итоге для каждого чата получить список сообщений в нём. Сначала chat-engine забирает из text-engine все сообщения пользователей из этого чата. В некоторых случаях их довольно много (до сотни миллионов), но за очень редким исключением чат полностью помещается в оперативную память. Мы имеем неупорядоченные сообщения, каждое в нескольких копиях — ведь вытаскиваются они все из разных экземпляров text-engine, соответствующих пользователям. Задача в том, чтобы отсортировать сообщения и избавиться от копий, которые занимают лишнее место.
У каждого сообщения есть timestamp, содержащий время отправки, и текст. Используем время для сортировки — помещаем указатели на самые старые сообщения участников мультичата и сравниваем хэши от текста предполагаемых копий, двигаясь в сторону увеличения timestamp. Логично, что у копий будут совпадать и хэш, и timestamp, но на практике это не всегда так.
Как Вы помните, синхронизация в старой схеме осуществлялась силами PHP — и в редких случаях время отправки одного и того же сообщения отличалось у разных пользователей. В этих случаях мы позволяли себе редактировать timestamp — обычно, в пределах секунды. Вторая проблема — разный порядок сообщений для разных получателей. В таких случаях мы допускали создание лишней копии, с разными вариантами порядка для разных пользователей.
После этого данные о сообщениях в мультичатах направляются в user-engine. И здесь возникает неприятная особенность импортированных сообщений. В нормальном режиме работы сообщения, которые приходят в движок, упорядочены строго по возрастанию user_local_id. Импортированные из старого движка в user-engine сообщения теряли это полезное свойство. При этом для удобства тестирования нужно уметь быстро к ним обращаться, что-то в них искать и добавлять новые.
Для хранения импортированных сообщений мы используем особенную структуру данных.
Она представляет собой вектор размера , где все — различны и упорядочены по убыванию, с особым порядком элементов. В каждом отрезке с индексами элементы отсортированы. Поиск элемента в такой структуре выполняется за время через бинарных поисков. Добавление элемента выполняется амортизированно за .
Итак, мы разобрались с тем, как переливать данные из старых движков в новые. Но этот процесс занимает несколько дней — и вряд ли на эти дни наши пользователи бросят привычку писать друг другу. Чтобы не потерять сообщения за это время, мы переключаемся на схему работы, которая задействует и старые, и новые кластеры.
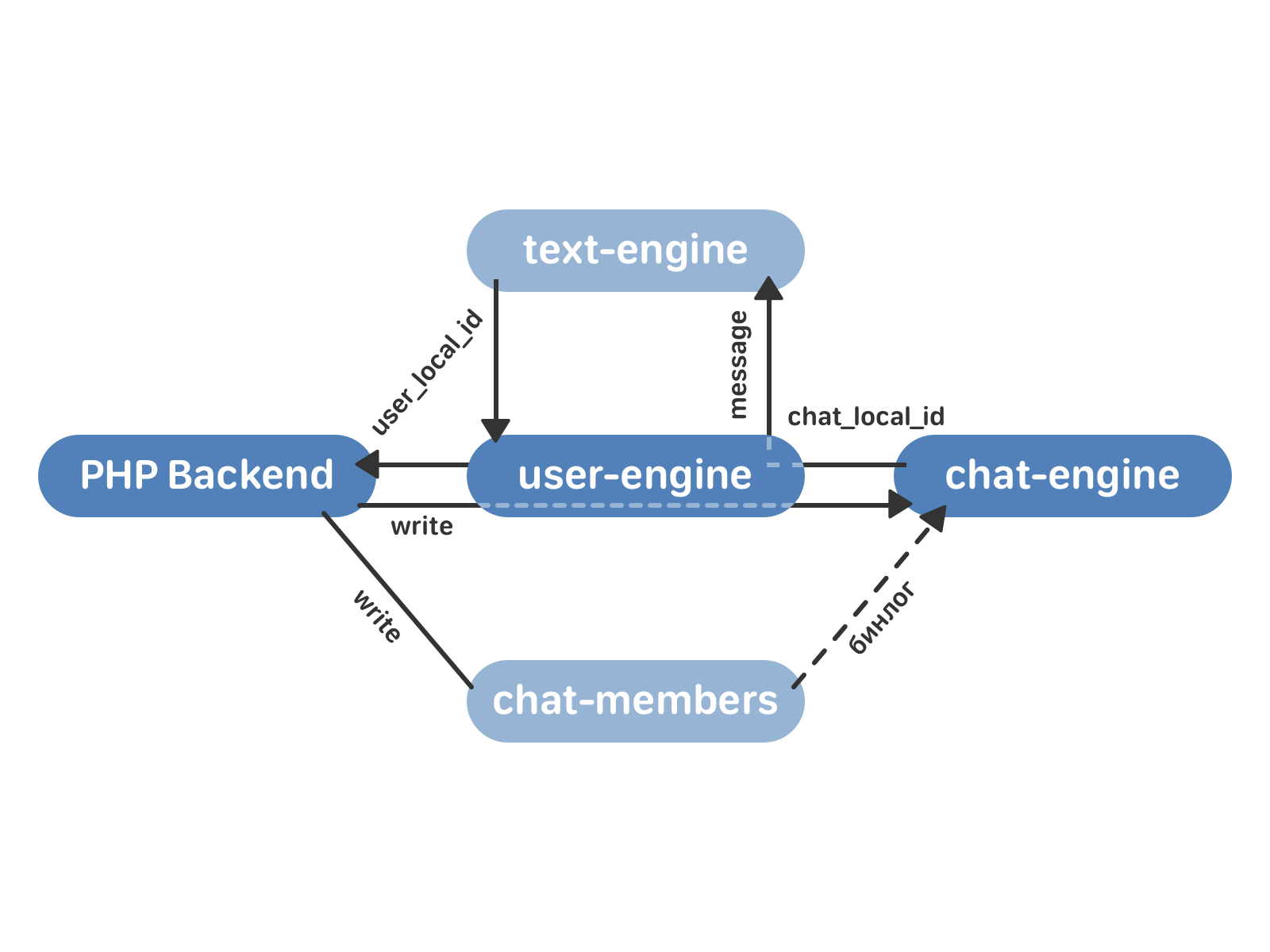
Запись данных идёт в chat-members и user-engine (а не в text-engine, как при нормальной работе по старой схеме). user-engine проксирует запрос к chat-engine — и здесь поведение зависит от того, смержен уже этот чат или еще нет. Если чат еще не смержен, chat-engine не записывает сообщение к себе, и его обработка происходит только в text-engine. Если чат уже смержен в chat-engine, он возвращает в user-engine chat_local_id и рассылает сообщение всем получателям. user-engine проксирует все данные в text-engine — чтобы в случае чего мы всегда могли откатиться назад, имея все актуальные данные в старом движке. text-engine возвращает user_local_id, который user-engine сохраняет у себя и возвращает в бэкенд.
В итоге процесс перехода выглядит так: подключаем пустые кластеры user-engine и chat-engine. chat-engine читает весь бинлог chat-members, затем запускается проксирование по схеме, описанной выше. Переливаем старые данные, получаем два синхронизированных кластера (старый и новый). Остается только переключить чтение с text-engine на user-engine и отключить проксирование.
Результаты
Благодаря новому подходу улучшились все метрики качества работы движков, решены проблемы с консистентностью данных. Теперь мы можем быстрее внедрять новые фичи в сообщениях (и уже начали это делать — увеличили максимальное число участников чата, реализовали поиск по пересланным сообщениям, запустили закреплённые сообщения и подняли лимит на общее число сообщений у одного пользователя).
Изменения в логике действительно грандиозные. И хочется отметить, что это не всегда означает целые годы разработки огромной командой и мириады строк кода. chat-engine и user-engine вместе со всеми дополнительными историями вроде Хаффмана для сжатия сообщений, Splay-деревьев и структуры для импортированных сообщений — это менее 20 тысяч строк кода. И написали их 3 разработчика всего за 10 месяцев (впрочем, стоит иметь в виду, что все три разработчика — чемпионы мира по спортивному программированию).
Более того, вместо удвоения числа серверов мы пришли к уменьшению их числа наполовину — сейчас user-engine и chat-engine живут на 500 физических машинах, при этом у новой схемы есть большой запас по нагрузке. Мы сэкономили кучу денег на оборудовании — это около $5 млн + $750 тысяч в год за счёт операционных расходов.
Мы стремимся находить лучшие решения для самых сложных и масштабных задач. У нас их предостаточно — и поэтому мы ищем талантливых разработчиков в отдел баз данных. Если Вы любите и умеете решать такие задачи, отлично знаете алгоритмы и структуры данных, приглашаем Вас присоединиться к команде. Свяжитесь с нашим HR, чтобы узнать подробности.
Даже если эта история не про Вас, обратите внимание, что мы ценим рекомендации. Расскажите другу о вакансии разработчика, и, если он успешно пройдёт испытательный срок, Вы получите бонус в размере 100 тысяч рублей.
- Блог компании VK
- Высокая производительность
- Алгоритмы
- Хранение данных
- Хранилища данных
Источник: habr.com
Можно ли регистрировать группу во Вконтакте как базу данных? Мнение эксперта
Не так давно предпринимателям пришлось осваивать новые способы продвижения и рекламы товаров в интернете. Одним из них стала социальная сеть «Вконтакте», которая предлагает различные инструменты для ведения бизнеса и продвижения своих товаров и услуг (подробную информацию можно найти на их официальной странице), среди которых — создание групп, объединяющих пользователей и позволяющих доносить информацию сразу до значительного количества людей.
Социальная сеть «Вконтакте» хорошо знакома юристам по делу Вконтакте против ООО «Дабл Дата»( дело A40-18827-2017) — спор, который длится уже более пяти лет и заключается в возможности признать саму группу социальной сети базой данных и извлекать из нее составную часть – информацию о пользователях.
Социальная сеть «Вконтакте» обвинила компанию «Дабл Дата» в нарушении исключительных прав на базу данных, состоящую из данных о зарегистрированных пользователях. Фирма утверждала, что разработанное ею программное обеспечение (программы Double Search и Social Link) собирает и анализирует данные о гражданах, не осуществляя при этом извлечение и использование материалов из базы данных с точки зрения Гражданского Кодекса (ГК РФ). И если вопрос, является ли сама социальная сеть базой данных, вызвал столько разногласий, то факт признания группы базой данных подвергается куда меньшей критике. Сделать такой вывод можно уже даже на том основании, что с 2014 года судами не было вынесено ни одного решения, в которых бы выносился на обсуждение этот вопрос.
Для начала укажем, что на основании ст. 1334 ГК РФ изготовителю базы данных принадлежит исключительное право на извлечение и использование материала в том случае, если ее создание (включая обработку или представление соответствующих материалов) требует существенных финансовых, материальных, организационных или иных затрат. Что касается базы данных группы во Вконтакте как объекта авторского права по смыслу ст. 1260 ГК РФ, то такое определение, по мнению некоторых авторов, более спорное — шаблон, предлагаемый социальной сетью, не дает особо много простора для экспериментов.
Почему же группу можно считать базой данных? Прежде всего, ввиду, действительно, необходимости приложить значительные усилия для того, чтобы сделать ее удобной для подписчиков и отличной от других — даже с учетом того, что доступный функционал весьма ограничен. Таким образом, основная нагрузка приходится действительно на поиск и подборку данных — и, в том числе, их расположению с учетом всех указанных факторов.
Такой же вывод следует из уже упомянутого спора (Постановление Суда по интеллектуальным правам (СИП) от 07.03.2014 № С01-114/2013 по делу № А56-58781/2012), который касался, по сути, «кражи» группы в социальной сети. Общественная организация культурных, образовательных и обменных программ для молодежи «Мир тесен» обнаружила, что в группе организации «Чемодан добрых дел — волонтерские лагеря» появляются записи с аналогичным информационным наполнением.
Суд первой инстанции согласился с истцом, однако апелляционная инстанция посчитала, что никаких затрат тут в не было ввиду следующих факторов:
- Для создания группы в социальной сети «Вконтакте» не требуется вложения существенных финансовых, материальных, организационных или иных затрат: сам процесс состоит из элементарных, заранее известных пользователям социальной сети www.vk.com шагов по осуществлению действий, направленных на создание группы, который занимает не более 10 минут.
- Создание группы в данной социальной сети — бесплатное.
- Созданием контента (тем в обсуждениях, загрузка фотографий, аудиозаписей, видеозаписей, добавление комментариев, отзывов) может заниматься любой пользователь социальной сети, поэтому для наполнения контента группы новыми материалами не требовалось вложения существенных затрат — истец указывал, в том числе, затраты на аренду офиса и оборудования, необходимых для ведения группы на должном уровне.
Суды обеих инстанций, делая вывод об отсутствии существенных финансовых, материальных, организационных или иных затрат, необходимых для создания базы данных, ошибочно связывали создание базы данных с процессом регистрации группы в социальной сети.
А таких элементов может быть достаточно много, и они, разумеется, могут представлять собой самостоятельные объекты права интеллектуальной собственности — ведь для наполнения группы материалом мы пишем тексты, делаем фотографии, снимаем видео, которые, помимо того. что являются объектами авторского права, требуют существенных затрат на их производство. Таким образом, уже даже для создания данного контента средства должны пойти на оплату работы и решения вопроса с исключительными правами, что подразумевается достаточно существенные затраты.
Следовательно, нельзя не согласиться с выводом о том, что при наличии достаточных затрат группа в социальной сети «Вконтакте» может считаться базой данных с соответствующим режимом охраны. Таким образом, в случае обнаружения незаконного «копирования» содержимого вашей группы вы можете воспользоваться еще одним инструментом для защиты прав. Но, конечно, для того, чтобы сделать это, рекомендуем вам сохранять всю документацию (договоры, счета и так далее) для подтверждения затраченных средств и усилий на создание базы данных.
Источник: onlinepatent.ru
Подключение к базе данных MySQL и работа с ней. Используем ее для ботов VK

В этой статье Вас ждет курс по подключению и работе с базой данных SQL, хранение и получение данных, все это мы будем использовать при создании бота Вконтакте
Если Вы читаете эту статью, значит Вы уже более менее разбираетесь в работе сервера. Для начала давайте рассмотрим то, что требуется для работы с базой данных.
Сервер с PHP не ниже 5.6
MySQL 5.5.х и выше
А теперь я отвечу на несколько вопросов
Что такое MySQL — Это система управления базами данных (СУБД), простым языком, с помощью MySQL мы можем сохранять, получать и удалять данные из таблиц.
Почему лучше выбирать SQL? Хранение данных в файлах при большом объеме информации будет с каждым разом нагружать работу вашего скрипта, дело может дойти до того, что данные просто не будут сохранятся. При использовании MySQL это проблема пропадает из за высокой скорости работы и структурированного хранения данных, что идеально подходит для работы с большим объемом данных.
Операторы SQL делятся на:
операторы определения данных:
CREATE создаёт объект БД (саму базу, таблицу, представление, пользователя и т. д.),
ALTER изменяет объект,
DROP удаляет объект;
операторы манипуляции данными:
SELECT выбирает данные, удовлетворяющие заданным условиям,
INSERT добавляет новые данные,
UPDATE изменяет существующие данные,
DELETE удаляет данные;
Для нашего проекта мы будем использовать операторы манипуляции данными, давайте уже начнем. В связи с тем что мы используем PHP для создания бота, то сами разработчики PHP рекомендуют использовать MySQLi, а начиная с версии PHP 7.x работает только MySQLi
MySQLi (от англ. MySQL improved) — расширение драйвера реляционных баз данных, используемого в языке программирования PHP для предоставления доступа к базам данных MySQL. MySQLi является обновлённой версией драйвера PHP MySQL, и даёт различные улучшения в работе с базами данных.
Перед тем как мы приступим к подключению, я рекомендую скачать среду разработки PHPStorm. Данная среда помогает в разработке, указывая на ошибки и подсказки при написании кода.
Что бы упростить работу с подключением и дальнейшей работой с базами данных, нужно скачать библиотеку и распаковать ее на сервер. Используя данную библиотеку, нам будет проще обращаться и получать данные с базы данных (далее БД).
vendor.rar
Теперь создаем файл нашего будущего проекта, давайте сделаем бота для Вконтакте, который будет сохранять информацию о пользователе в БД, для примера можем написать админку для нашего прошлого кода, о котором я писал здесь
Берем готовый код с прошлой статьи
type == ‘confirmation’) < //Если vk запрашивает ключ exit(ACCESS_KEY); //Завершаем скрипт отправкой ключа >$vk->sendOK(); //Говорим vk, что мы приняли callback // Создаем необходимые переменные $peer_id = $data->object->peer_id; // Узнаем ИД беседы 2000000. $id = $data->object->from_id; // Узнаем ид пользователя который отправляет команду $message = $data->object->text; // Текст самого сообщения $is_admin = [87444494, 183657]; // создаем массив с ID’s наших будущих админов через запятую $chat_id = $peer_id — 2000000000; if ($data->type == ‘message_new’) < // Если это новое сообщение то выполняем код указанный в условии if (mb_substr($message,0,5) == ‘/kick’)< // Обрезаем сообщение и сравниваем что получилось if (in_array($id, $is_admin)) < // С помощью in_array проверяем схожесть переменной $id с массивом с ID’s $kick_id = mb_substr($message ,6); // еще раз обрезаем и получаем все что написано после /kick_ $kick_id = explode(«|», mb_substr($kick_id, 3))[0]; if($kick_id == «»)< $vk->sendMessage($peer_id, «Вы забыли указать аргумент»); > else < $vk->request(‘messages.removeChatUser’, [‘chat_id’ => $chat_id, ‘member_id’ => $kick_id]); $vk->sendMessage($peer_id, «id — был исключен :-)»); > > else < $vk->sendMessage($peer_id, «У Вас нет доступа к этой команде!»); > > >
Админ права нужно было прописывать постоянно в скрипте, в строке
$is_admin = [87444494, 183657]; // создаем массив с ID’s наших будущих админов через запятую
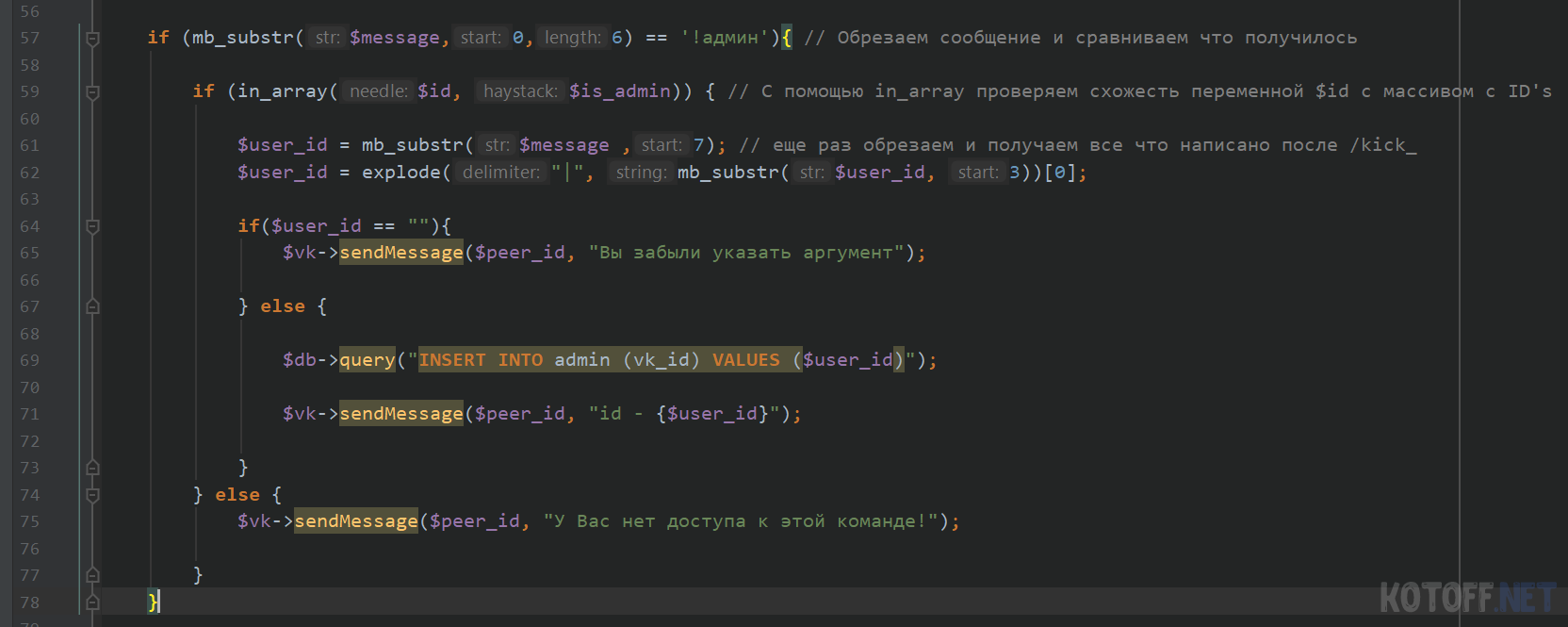
Это не совсем удобно, давайте создадим команду !админ, которая будет принимать 1 аргумент, это ID пользователя, его мы уже научились принимать в той же статье про исключение пользователя.
if (mb_substr($message,0,6) == ‘!админ’)< // Обрезаем сообщение и сравниваем что получилось if (in_array($id, $is_admin)) < // С помощью in_array проверяем схожесть переменной $id с массивом с ID’s $user_id = mb_substr($message ,7); // еще раз обрезаем и получаем все что написано после !админ_ $user_id = explode(«|», mb_substr($user_id, 3))[0]; if($user_id == «»)< $vk->sendMessage($peer_id, «Вы забыли указать аргумент»); > else < $vk->sendMessage($peer_id, «id — «); > > else < $vk->sendMessage($peer_id, «У Вас нет доступа к этой команде!»); > >

Такой командой мы получаем ID пользователя
Этот ID мы будем сохранять в базу данных, потом получать его и сверять, есть ли этот ID в БД, если да, то даем доступ к команде.
Теперь создаем базу данных. Сделать это можно используя панель управления ISPManager, она предоставляется практически всегда, заходим и выбираем Базы данных и создаем новую БД, название bot, пользователь и пароль придумайте свои, сохраняем.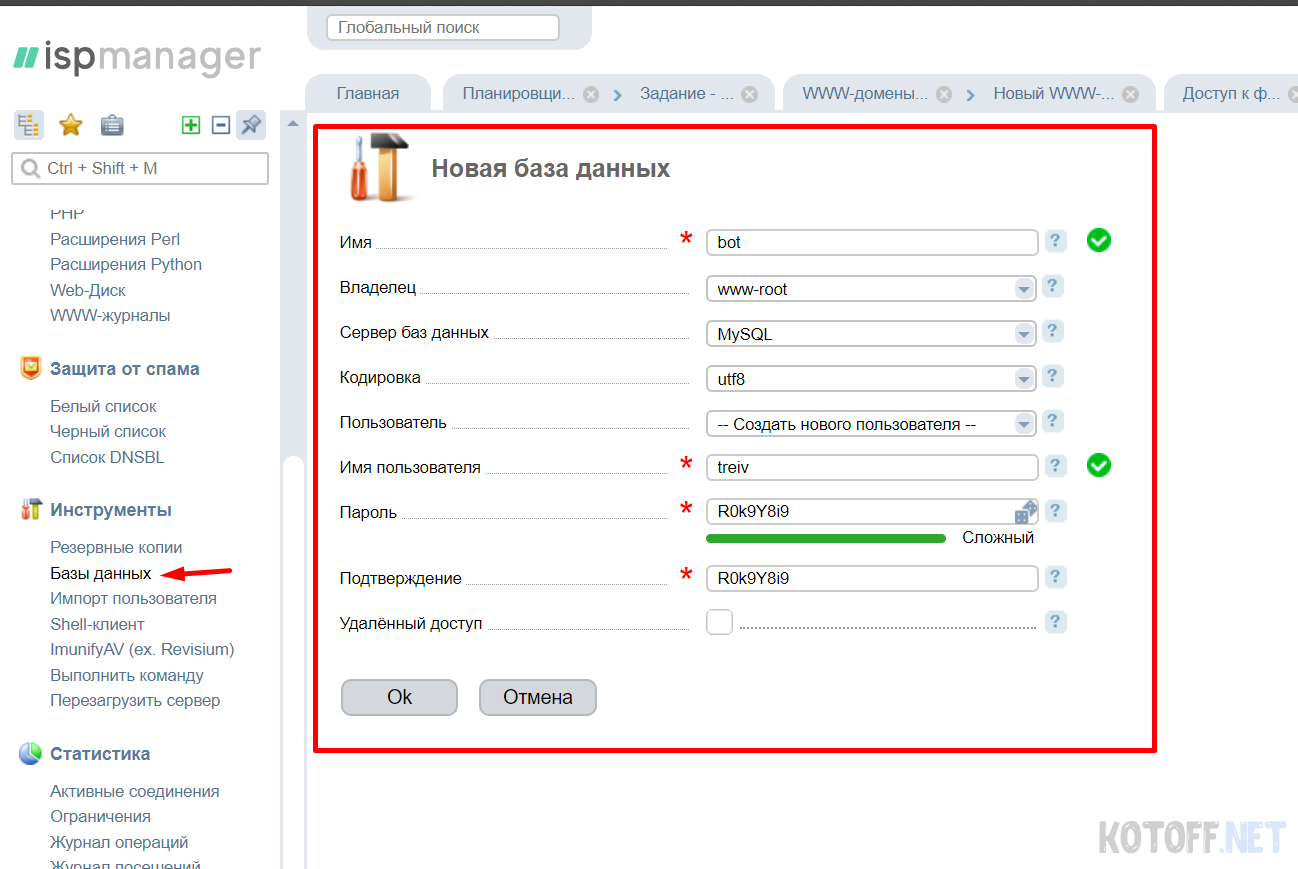
Теперь ниже переходим в phpMyAdmin
Или просто перейти с раздела Базы данных, если такая кнопка есть
После того как зашли в phpMyAdmin, нам нужно создать таблицу в БД, выбираем сверху в меню SQL и вставляем туда запрос, не забудьте выбрать название БД, где мы будем создавать саму таблицу
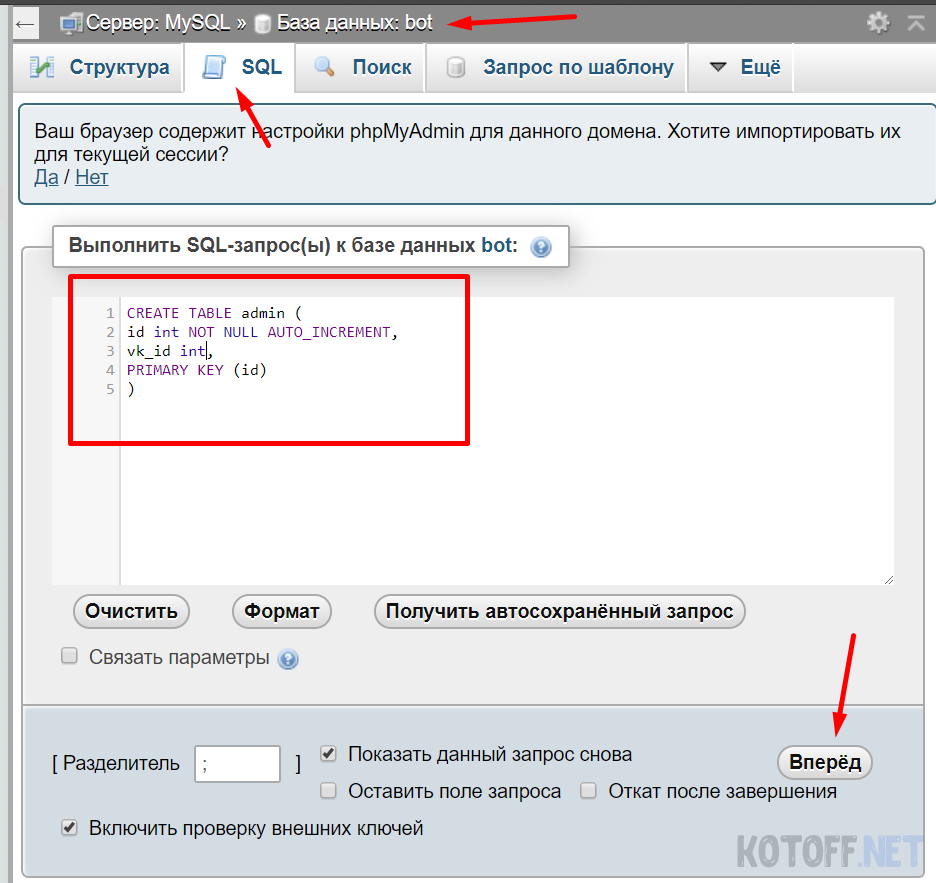
CREATE TABLE admin ( id int NOT NULL AUTO_INCREMENT, vk_id int, PRIMARY KEY (id) )
Наша таблица готова, теперь мы можем сохранять туда наши данные, это будет ID пользователя. Переходим к нашему коду и делаем подключение к БД, выше мы скачали библиотеку для работы с БД, распакуем ее в корень, где лежит наш бот
и делаем подключение в самом скрипте 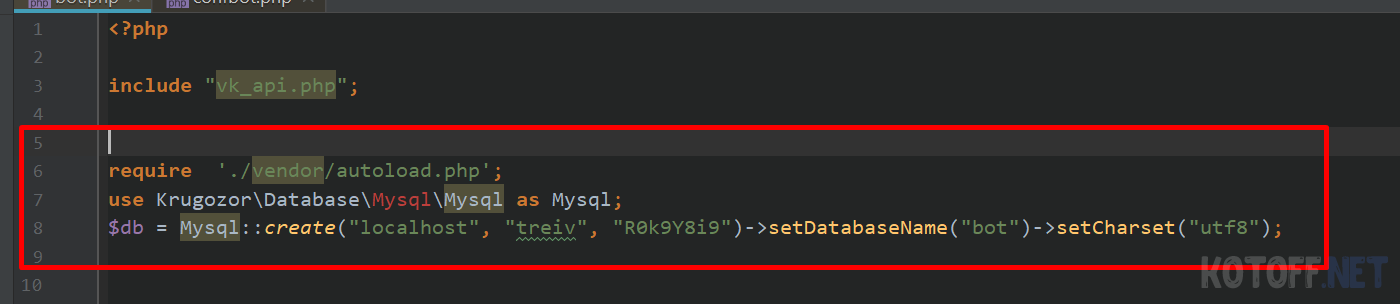
require ‘./vendor/autoload.php’; use KrugozorDatabaseMysqlMysql as Mysql; $db = Mysql::create(«localhost», «login», «password»)->setDatabaseName(«nameBD»)->setCharset(«utf8»);
Таким простым способом мы подключились к БД, все это благодаря библиотеке. Давайте теперь сохраним наши первые записи в БД, переходим снова к админке и создаем запрос используя оператор INSERT
$db->query(«INSERT INTO admin (vk_id) VALUES ($user_id)»);
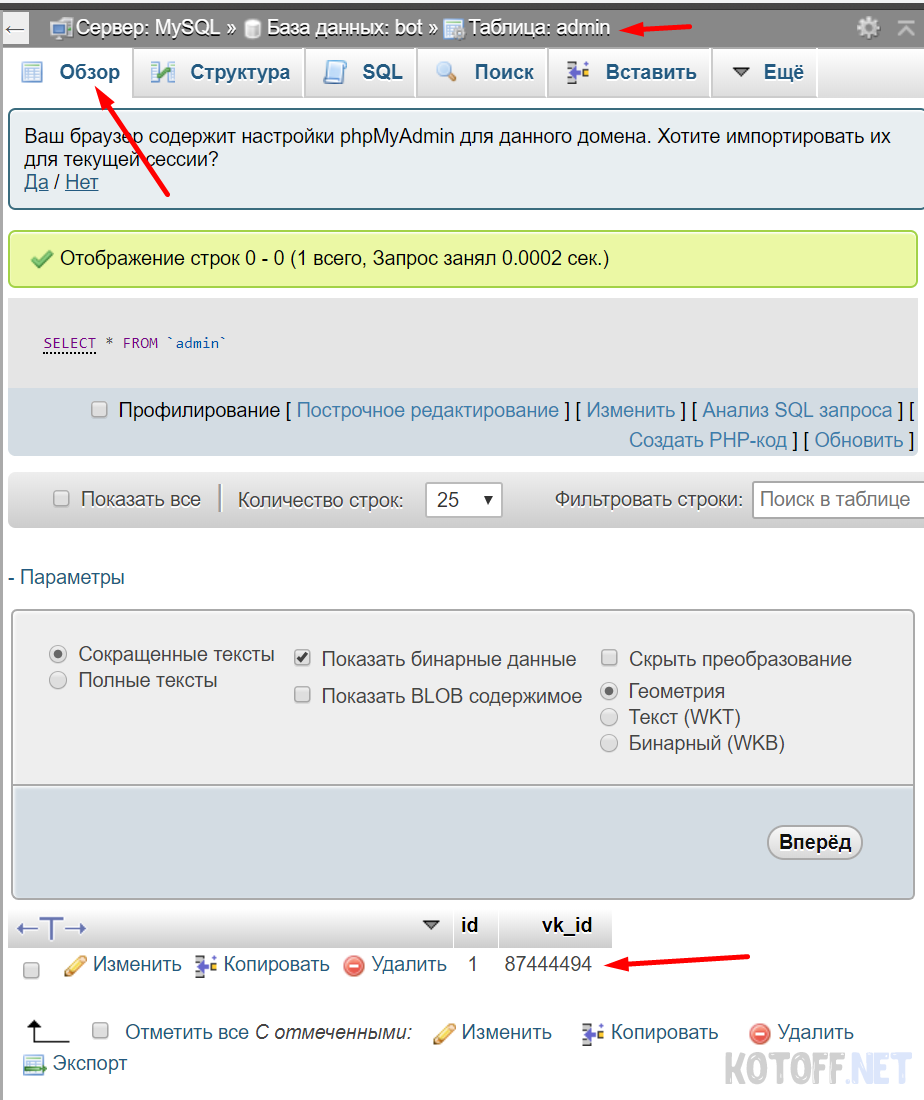
Давайте напишем команду и посмотрим что произойдет
Данные сохранились в таблицу, но если мы повторно отправим команду с этим же ID, будет создана еще 1 запись, а это нам не нужно, давайте сделаем проверку, если запись уже есть, то ничего предупредим об этом, иначе создадим запись в БД
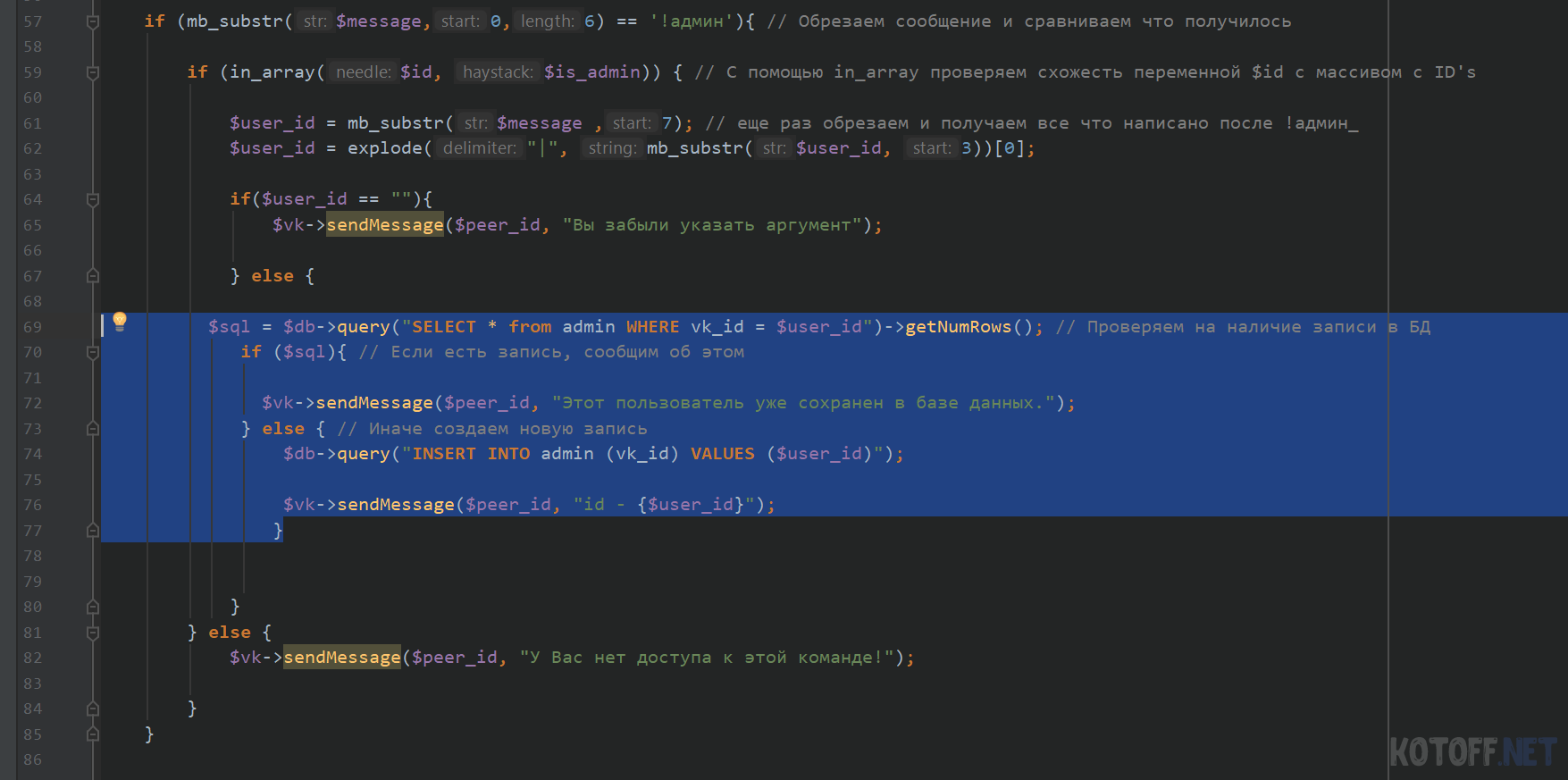
Что бы проверить наличие записи, нужен оператор SELECT, им будем проверять наличие записей в БД. Давайте сделаем проверку на наличие записи в БД. Пишем следующий код:
$sql = $db->query(«SELECT * from admin WHERE vk_id = $user_id»)->getNumRows(); // Проверяем на наличие записи в БД if ($sql)< // Если есть запись, сообщим об этом $vk->sendMessage($peer_id, «Этот пользователь уже сохранен в базе данных.»); > else < // Иначе создаем новую запись $db->query(«INSERT INTO admin (vk_id) VALUES ($user_id)»); $vk->sendMessage($peer_id, «id — «); >

Как вы уже догадались из комментариев к коду, мы сделали проверку на запись, иначе создаем новую запись, давайте проверим.
Таким образом делается проверка на наличие записи.

Теперь рассмотрим вариант получения данных с базы данных, это делается так же легко и просто. Используем все тот же оператор SELECT
if (mb_substr($message,0,8) == ‘!адмлист’)< // Обрезаем сообщение и сравниваем что получилось $is_admins = $db->query(«SELECT * FROM admin»)->fetch_assoc()[‘vk_id’]; // Получаем данные из колонки vk_id $vk->sendMessage($peer_id, «Данные с БД — $is_admins»); >

Таким образом мы получили данные с БД и вывели их с помощью бота. Такой способ выводит только 1 запись, для вывода нескольких записей нужно использовать цикл WHILE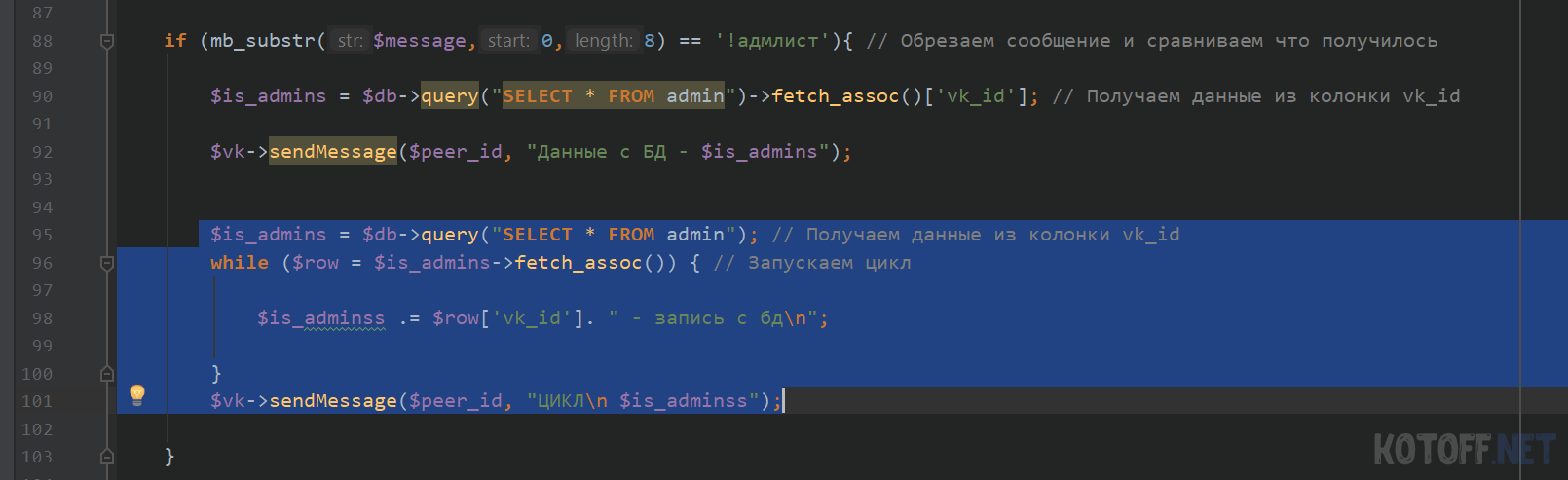
$is_admins = $db->query(«SELECT * FROM admin»); // Получаем данные из колонки vk_id while ($row = $is_admins->fetch_assoc()) < // Запускаем цикл $is_adminss .= $row[‘vk_id’]. » — запись с бдn»; >$vk->sendMessage($peer_id, «ЦИКЛn $is_adminss»);
Создаем еще 1 запись в БД и проверим получения данных из БД:

С получением данных разобрались, теперь рассмотрим последний пример на сегодня, это UPDATE, для обновления записей в БД.
if (mb_substr($message,0,9) == ‘!обновить’)< // Обрезаем сообщение и сравниваем что получилось $db->query(«UPDATE admin SET vk_id = 777777 WHERE vk_id = 87444494 LIMIT 1»); // WHERE — Поиск записей в которые нужно внести изменения, перечесляются через AND, LIMIT 1 — Найти 1 запись, другие похожие не трогать $vk->sendMessage($peer_id, «Данные обновлены»); >
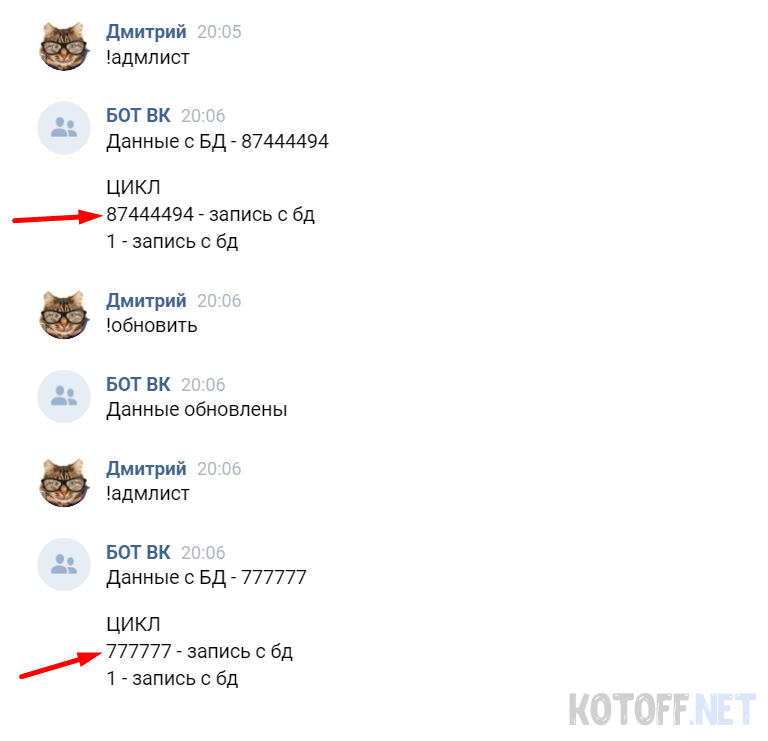
В SET указываем то, что нужно обновить, если в строке несколько записей, указывайте их через запятую. Таким образом мы обновилиID пользователя. Используя статьи с нашего сайта, вы уже можете создать полноценного бота, или обратиться в нашу группу за разработкой.

- TREiV
- 05.04.2019
- 18 611
- 41
- 16
Источник: kotoff.net