Корпоративные хранилища и витрины данных были рассмотрены здесь, в материале про ETL-процессы. Сегодня проанализируем еще один важный элемент современной ИТ-инфраструктуры для хранения больших данных (Big Data). Читайте в этой статье, что такое озеро данных (Data Lake), зачем оно нужно, как используется, на каких технологиях основано и чем чревато его некорректное применение.
Что такое озеро данных и кому оно нужно
Одно из отличительных свойств Big Data – это разный формат представления информации: посты в соцсетях, файлы мультимедиа, логи с технологического оборудования, записи из корпоративных баз данных и пр. Чтобы извлечь из всех этих данных полезные для бизнеса сведения, их прежде всего необходимо собрать. Как раз для этого и используется озеро данных – хранилище большого объема неструктурированных данных, собранных или генерированных одной компанией [1].
В отличие от корпоративных хранилищ данных (КХД) или Data Warehouse (DWH), в озере данных хранится неструктурированная, т.н. сырая (raw) информация. Например, видеозаписи с беспилотников и камер наружного наблюдения, транспортная телеметрия, фотографии, логи пользовательского поведения, метрики сайтов, показатели нагрузки информационных систем и пр. Такие данные пока непригодны для типового использования в ежедневной аналитике в рамках BI-систем, но могут использоваться для быстрой отработки новых бизнес-гипотез с помощью ML-алгоритмов. Таким образом, именно Data Scientist – это типичный пользователь озера данных, тогда как с DWH работает гораздо больше сотрудников: аналитики, профильные специалисты и руководители. Однако, это не единственная разница между Data Lake и КХД.
Discover a beautiful lake on my way #youtube #travel #lake
Чтобы лучше понять, что общего между этими элементами корпоративной ИТ-инфраструктуры и чем они отличаются, проанализируем их по следующим критериям [2]:
- полезность содержимого;
- структуры (типы) данных;
- гибкость;
- доступность;
- стоимость.
Data Warehouse
Хранятся только полезные данные, актуальные в текущем периоде времени
Хранятся все данные, в т.ч. и «бесполезные», которые могут пригодиться в будущем или же не понадобиться никогда
Четко структурированные данные одного формата
Структурированные, полуструктурированные и неструктурированные разнородные данных любых форматов: от мультимедиа файлов до текстовых и бинарных из разных источников
Низкая гибкость: структура и типы данных продумываются заранее и не подлежат изменению в процессе эксплуатации
Высокая гибкость, которая позволяет в процессе эксплуатации добавлять новые типы и структуры данных
Доступность
Благодаря четкой структуре данных процесс их извлечения и обработки происходит быстро
Из-за отсутствия четкой структуры необходима дополнительная обработка данных для их практического использования
Высокая стоимость из-за сложности проектирования и модернизации, а также цены оборудования для быстрой и эффективной работы
Озеро данных намного дешевле DWH, т.к. основная статья затрат – это хранение гигабайт информации
Таким образом, озера данных дают практическому применению Data Science (DS) в бизнесе следующие преимущества [3]:

- масштабируемость – распределенная файловая система позволяет по мере необходимости подключить новые машины или узлы без изменения структуры хранилища или сложной перенастройки;
- экономичность – Data Lake можно построить на базе свободного ПО Apache Hadoop, без дорогостоящих лицензий и дорогих серверов, используя нужное количество сравнительно бюджетных машин;
- универсальность – большие объемы разнородным данных могут использоваться практически для любой исследовательской DS-задачи – от прогнозирования спроса до выявления пользовательских предпочтений или влияния погоды на качество продукции;
- быстрота запуска – накопленные объемы Data Lake позволяют быстро проверить очередную ML-модель, не тратя время и инженерные ресурсы на сбор информации из разных источников.
На чем стоит озеро данных
Как было отмечено выше, в большинстве случаев озера данных строятся на основе коммерческих дистрибутивов Apache Hadoop (Cloudera/HortonWorks, MapR, Arenadata) или облачных решений от Amazon Web Services, Microsoft Azure, Mail.ru, Яндекса и других Cloud-провайдеров. Существуют также готовые продукты от специализированных вендоров корпоративного сектора Big Data: Teradata, Zaloni, HVR, Podium Data, Snowflake и т.д. [4]
В любом случае, независимо от выбранной базы, организация Data Lake включает следующие компоненты [5]:
- средства загрузки данных в пакетном (batch) или потоковом (streaming) режимах. Например, непрерывный сбор данных может быть организован с помощью Apache Kafka или NiFi, а пакетный – с использованием Apache Airflow.
- файловое хранилище, которое должно быть масштабируемым, отказоустойчивым и достаточно дешевым. Например, HDFS (распределенная файловая система Apache Hadoop) или Amazon S3.
- инструменты каталогизации и поиска, чтобы быстро искать необходимую информацию с помощью метаданных и дополнительных решений, например, Apache Solr или Amazon ElasticSearch.
- средства обработки данных для их трансформации, очистки и других преобразований с целью последующего использования. Например, Apache Spark – Big Data фреймворк для работы с данными в режиме near real time, включая ML-моделирование (Spark MLLib).
- компоненты обеспечения информационной безопасности – организация защищенного периметра сети (Apache Knox Gateway), резервного копирования, репликации и восстановления, шифрование SSL, безопасные протоколы (Kerberos), политики ограничения доступа с помощью Apache Ranger и Atlas.
Хотя Data Lake позиционируется, в первую очередь, как хранилище сырой информации, оно может содержать также и обработанные данные. При корректном использовании Data Lake предоставляет пользователям возможность быстро запрашивать меньшие, более актуальные и гибкие наборы данных по сравнению с DWH при аналогичном времени выполнения запросов. Это возможно благодаря вычисляемой на лету схеме данных (ad hoc), которая не предопределяется заранее, а формируется в момент доступа. Таким образом, на практике озеро данных может использоваться вместе с КХД, обеспечивая бизнес-инфраструктуру на основе информации (data-driven) [6].

Как не превратить Data Lake в информационное болото
При всех своих достоинствах, озера данных чреваты следующими рисками [7]:
- низкое качество данных ввиду их отсутствия контроля при их загрузке, а также простоты этого процесса и дешевизны хранения информации;
- сложность определения ценности данных. С одной стороны, философия Big Data предполагает важность любой информации. Но, с другой стороны, если бизнесу быстро нужны какие-то данные, об этом, как правило, известно заранее. А потому такую информацию логично сразу загружать в DWH или витрину BI-системы.
- превращение озера данных в болото, что является последствием двух предыдущих рисков.
Чтобы озеро данных не превратилось в болото, необходимо отладить процесс управления данными — data governance, определяя качество информации еще до загрузки в data lake. Это можно сделать следующими способами [2]:
- отсекать источники с заведомо недостоверными данными; настроить ролевые политики прав доступа на загрузку информации для определенных категорий сотрудников;
- проверять некоторые параметры файлов, например, размер изображений или видео/аудиозаписей.
В дополнение к этим рекомендациям, компания Teradata, один из ведущих поставщиков Big Data решений для аналитики, приводит еще 5 советов по эффективному развертыванию озер данных [7]:
- интегрируйте озеро данных с другими элементами корпоративной ИТ-инфраструктуры: DWH, базами данных информационных систем, облачными сервисами, устройствами интернета вещей и прочими источниками потенциально нужных данных. При этом помните о балансе между емкостью хранилища, его быстротой и разумной стоимостью этого решения.
- не засоряйтеDataLake – вместо одного глобального хранилища имеет смысл организовывать несколько пространств и сразу размещать данные по категориям. Эта мера также улучшит функциональное свойство, важнейшее с точки зрения пользователя – скорость считывания информации.
- поддерживайте доверие к данным, фиксируя их происхождение (data provenance) и проверяя качества метаданных.
- дайтеDataScientist’ам и аналитикам инструменты для исследования, профилирования и получения ответов на свои запросы из озера данных, организовав их в кроссфункциональные команды с data инженерами, разработчиками и бизнес-экспертами.
- обеспечьте безопасность, предупреждая возможные утечки и потери данных с помощью политик управления доступом, средств организации защищенного периметра, резервного копирования, репликации и восстановления.
Интересна также корреляция чистоты озера данных со степенью управленческой зрелости предприятия по модели CMMI. В частности, когда ведется непрерывный мониторинг отлаженных бизнес-процессов, современные Big Data инструменты с интегрированными средствами машинного обучения позволяют обеспечить самоорганизацию Data Lake, выполняя непрерывный сбор, агрегацию и мета-разметку информации с помощью так называемых конвейеров данных (data pipeline) [8].
Уровень зрелости управления
Состояние и характер данных
Состояние Data Lake
Данные дублируются или частично отсутствуют, представлены в разных форматах и системах, не связаны между собой, велика доля ручной обработки данных
Локальное хранилище данных без определенного порядка автоматизированной обработки
Информация достаточно успешно обрабатывается автоматически в пределах одного подразделения, но не интегрирована с другими корпоративными процессами и структурами (отделами, филиалами и пр.)
Лужа или болото данных
Обмен данными между различными процессами, системами и структурами предприятия частично автоматизирован, имеется единый каталог корпоративных данных
4. Управляемый на основе количественных данных
Синхронизация данных между различными процессами, системами и структурами предприятия автоматизирована не полностью, часть процедур запускается по требованию или вручную
Управляемое озеро данных
Процедуры автоматизированного появления, обновления, обмена и синхронизации данных между различными процессами, системами и структурами предприятия отлажены и успешно работают
Вместо заключения
По прогнозу Marketshttps://www.chernobrovov.ru/articles/kuda-slit-big-data-ili-zachem-vam-ozero-dannyh.html» target=»_blank»]www.chernobrovov.ru[/mask_link]
Что такое Intel Ice Lake и чем она отличается от Kaby Lake?
Ожидается, что Intel начнет выпуск процессоров Core 8-го поколения 21 августа. Эта серия, получившая название Coffee Lake, будет основана на 14-нм технологическом процессе Intel третьего поколения (14 нм ++) и будет использовать тот же сокет LGA1151, что и линейки текущего поколения Kaby Lake (14 нм +) и Skylake последнего поколения (14 нм). Ожидается, что модельный ряд модернизируется в начале следующего года. Ожидается, что первые 10-нм чипы под кодовым названием Cannon Lake будут выпущены для настольных компьютеров и ноутбуков. Тем не менее, еще до того, как Coffee Lake или Cannon Lake были официально объявлены, Intel обнародовала планы относительно того, что, как ожидается, станет архитектурой Core 9-го поколения компании под кодовым названием Ice Lake.
Что такое микроархитектура Intel ‘Ice Lake’?
Как уже упоминалось, «Ice Lake» — это кодовое название Intel для того, что широко распространено в линейке процессоров Core 9-го поколения . Официально названный «преемником семейства процессоров 8-го поколения Core», Ice Lake будет использовать процесс изготовления чипов 10nm + компании, что делает его линейкой Intel второго поколения 10nm после Cannon Lake. Ранее компания объявила, что планирует запустить три поколения своей 10-нм технологии: 10-нм, 10-нм + и 10-нм ++, как это происходит с 14-нм чипами.

Изображение: любезно Intel
Intel Ice Lake против Kaby Lake?
Поскольку ожидается, что линейка Ice Lake не будет запущена до следующего года, подробности о предполагаемых чипах Intel 9-го поколения трудно найти. При этом самым существенным отличием между двумя поколениями процессоров будет производственный процесс, когда новая заявленная линия будет производиться на 10-нм узле Intel (10 нм +) второго поколения, который, как ожидается, заменит Cannon Lake в следующем году. Также ожидается, что процессоры Ice Lake будут работать с чипсетами Intel серии 500, что также будет изменением по сравнению с процессорами Kaby Lake текущего поколения, которые используются в сочетании с чипсетами серии 200. Говорят также, что процессоры Ice Lake будут поставляться с интегрированными графическими процессорами Intel 11-го поколения, но пока нет официального подтверждения в этом отношении.
10 нм против 14 нм чипов: повышение энергоэффективности и производительности
Согласно плану, выпущенному Intel ранее в этом году, производительность ее 10-нм чипов первого поколения, которые будут выпущены в следующем году, будет значительно ниже, чем у 14-нм чипов третьего поколения (Coffee Lake), которые должны быть запущены в этом месяце., Ожидается, что разрыв в производительности между 10-нм и 14-нм микросхемами компании только в следующем году начнет совсем незначительно уменьшаться с чипами Ice Lake, но он все равно будет ниже, чем 14-нм ++-чипы с точки зрения производительности транзисторов, что означает пиковые частоты из этих фишек примет определенный удар. Между тем, наибольшим преимуществом 10-нм чипов будет меньшая емкость, что приведет к снижению энергопотребления.
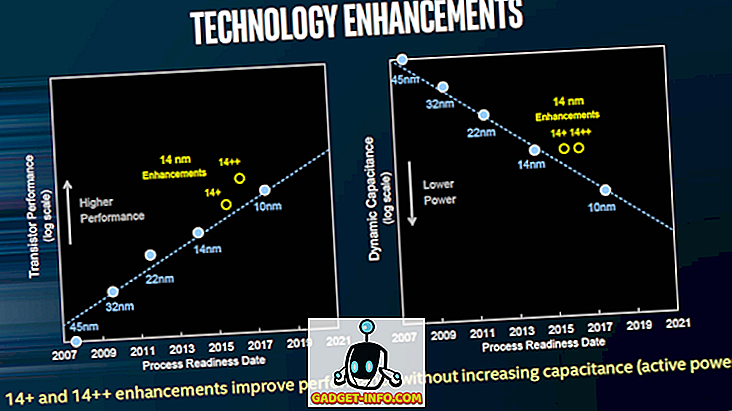
Изображение: любезно Intel
Хотя производительность транзисторов 10-нм чипов будет ниже, чем у 14-нм компонентов, более мелкие транзисторы должны позволять Intel вводить большее количество из них в каждый чип, тем самым улучшая производительность, сохраняя при этом расходы. Приведенный ниже график показывает, что при переходе от 14 нм к 10 нм плотность логических транзисторов, вероятно, возрастет почти в 3 раза.
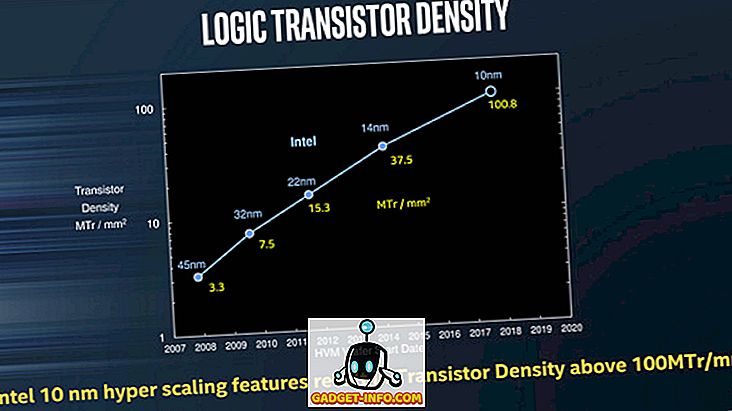
Изображение: любезно Intel
Когда чипсы Ice Lake могут попасть на рынок?
Intel не знает, когда ее чипы 9-го поколения появятся на рынке, но если график последних выпусков продукции компании будет чем-то соответствовать, процессоры Ice Lake могут быть анонсированы в конце 2018 или даже в начале 2019 года . В любом случае, вам, скорее всего, придется подождать, по крайней мере, до середины конца 2019 года, чтобы заполучить их.
| Микроархитектура | Ядро поколения | Узел процесса | Год выпуска |
| Песчаный Мост | второй | 32нм | 2011 |
| Ivy Bridge | третий | 22 нм | 2012 |
| Haswell | четвёртая | 22 нм | 2013 |
| Бродуэлла | пятые | 14nm | 2014 |
| Skylake | шестые | 14nm | 2015 |
| Kaby Lake | седьмые | 14nm + | 2016 |
| Кофейное озеро | восьмых | 14nm ++ | 2017 |
| Cannon Lake | Восьмому / девятым | 10нм | 2018 |
| Ледяное озеро | Девятую / десятые | 10нм + | 2018/2019 |
Здесь стоит упомянуть, что 10-нм чипы первого поколения (Cannon Lake) изначально должны были появиться на рынке в прошлом году, но этот план был сорван, поскольку компания столкнулась с многочисленными проблемами, связанными с 14-нм процессом. Теперь, когда третье и последнее поколение чипов по 14 нм (Coffee Lake, 14 нм ++) уже готово к выходу на рынок, ожидается, что 10 нм запчасти начнут появляться в следующем году.
Ледяное озеро и будущее Intel
Поскольку новая линейка AMD Ryzen доминирует в новостных циклах, Intel слишком хорошо знает, что ей нужно улучшить свою игру, если она не хочет, чтобы ее старый противник стал доминирующим производителем чипов x86. Будет интересно посмотреть, что 10 нм процессоры Intel принесут на стол, но компания вполне могла бы обойтись без разногласий вокруг чипов Ice Lake, которые мы наблюдаем сейчас вокруг Coffee Lake. В случае, если вы не знаете, последние отчеты, кажется, предполагают, что люди, желающие перейти на будущую платформу Intel 8-го поколения Intel, должны будут покупать новые материнские платы 300-й серии, потому что процессоры Coffee Lake, очевидно, не будут совместимы с более старой 200-й серией. чипсеты. Теперь, будь то циничная маркетинговая уловка от Intel или есть подлинная проблема с совместимостью, еще неизвестно, но новости не могли бы прийти в худшее время для Intel, учитывая, что компания практически находится в осаде от Ryzen и Threadripper от AMD ЦП.
Итак, теперь, когда у вас есть обзор процессоров Intel Ice Lake, что вы думаете о них? Планируете ли вы перейти на грядущее Кофейное озеро или собираетесь подождать с дополнительной информацией о Ледяном озере, прежде чем принять решение? Не стесняйтесь, дайте нам знать в разделе комментариев ниже.
Источник: ru.gadget-info.com
Разработчики Alan Wake 2 рассказали об источниках вдохновения

На канале IGN вышло видео, в котором разработчики Alan Wake 2, среди которых есть и Сэм Лейк, рассказали, чем вдохновлялись при создании тайтла и его атмосферы.
На разработчиков игры очень сильно повлияли сериалы «Твин Пикс» и «Настоящий детектив», а также триллер «Семь». Команде очень понравилось, как в шоу показывали взаимодействие детективов во время их расследования.
А Нью-Йорк, в котором будет бродить Алан Уэйк, вдохновлен «Таксистом» Мартина Скорсезе. Remedy оценила мрачную атмосферу в ленте Скорсезе и захотела добавить нечто подобное в тайтл,.
Alan Wake 2 выйдет 27 октября на PC, PS5 и Xbox Series X/S.
Больше статей на Shazoo
- Разработчики Alan Wake 2 хотели поэкспериментировать с музыкой в игре
- Microsoft отказалась от концепта Alan Wake 2 с сериальными вставками ради Quantum Break
- Отказ от дисков поможет разработчикам Alan Wake 2 отполировать игру
Источник: shazoo.ru