Бан список слов youtube. Когда мы говорим о черном списке для «youtube» — что это вообще означает и о чем идет речь!? Один из вариантов — это запрещенные для использования слова в видео, в тексте на youtube.
И второй вариант(который называется «Фильтр мата»)- это создание черного списка, чтобы особо одаренных, чтобы они не использовали слова, которые не принято применять в цивилизованном обществе!
Фильтр мата, Бан список слов на youtube
- Фильтр мата в новой версии творческой студии
- Фильтр мата в старой версии творческой студии
- Список запрещённых слов на youtube
- Зацените прикол.
Фильтр мата в новой версии творческой студии
Второй способ -= если вы попали в творческую студию и у вас новый дизайн, то здесь тоже есть эти настройки фильтра мата youtube.
Панель управления — настройки – сообщество – черный список. И поступаем аналогично, как и в первом случае. Поле ведет себя аналогично, как заполнение тегов — если вы загружали видео.
Как собрать целевую аудиторию ВКонтакте по конкурентам c помощью сервиса Target Hunter.
Можно открыть в отдельном окне!
Фильтр мата в старой версии творческой студии
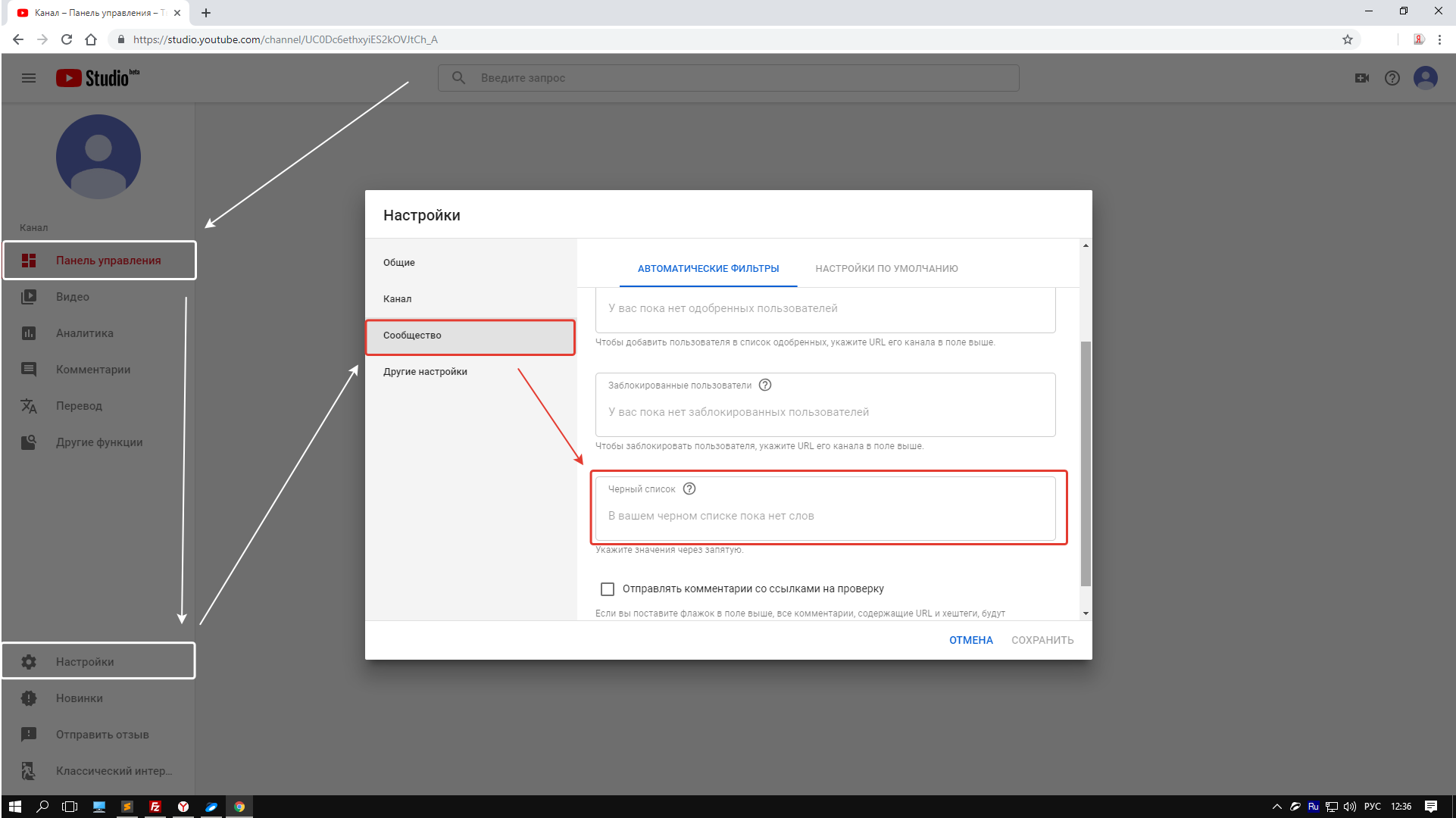
Первыми делом нам нужно попасть в творческую студию. Можно в неё попасть, как показано на скрине. Это не единственный способ.
Далее ищем строку – сообщество – настройки сообщества и опускаемся до поля — черный список.
Добавляем в это поле все те слова, либо словосочетания через запятую и нажимаем сохранить!
Можно открыть в отдельном окне!
Список запрещённых слов на youtube на английском
Добавлен реальный список слов, которые запрещены на
youtube — это официальная страница с youtube с перечнем запрещенных слов.
Некоторые слова, кроме удивления у меня ничего не вызывают.
Такой толерантный запад запрещают такие слова, которые и обзывательством не являются.
Деградирующая цивилизация, что с них возьмешь!
Список запрещённых слов на youtube на русском
К сожалению, весь интернет облазил — нигде не видел список запрещенных слов на русском для youtube. Если есть ссылка, пожалуйста поделитесь в комментариях!
Рекомендую ознакомиться с видео о словах, бане и демонетизации.
Вот нашел на просторах youtube — занимательное видео о «запрещенных словах, бане и демонетизации»!
Вообще тема не была про «Список запрещённых слов на youtube», но люди, валом валят именно по этому поисковому запросу! Иногда меня, некоторые вопросы просто удивляют!
Вы не знаете «Список запрещённых слов на youtube» — все те слова, которые вы бы не смогли сказать «маме» — это и есть «запрещённые слова на youtube».
А если вы разговариваете матом с мамой, то вперед!
И попробуйте поговорить с ним в таком же ключе!
Youtube — это не твоя мама, он тебе быстро покажет, кто здесь кто!
Итак. все же по многочисленным просьбам.
Список запрещённых слов на youtube
Зацените прикол.
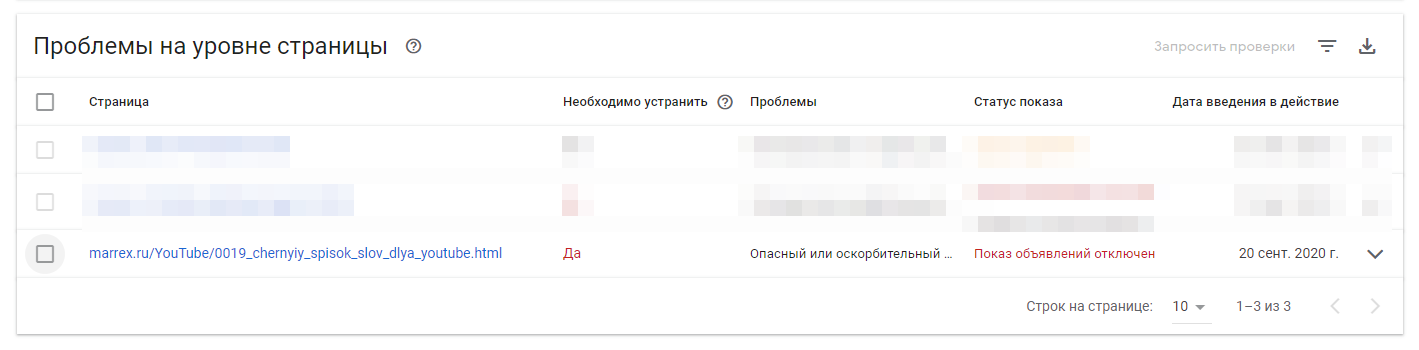
Гугл запретил показывать здесь свои объявления — это означает отключение от монетизации. да и хрен с вами.
Вообще ищу другие способы монетизации, а то такие копейки, что п Ь якать хочется.
Можно открыть в отдельном окне!
Помоги проекту : Marrex.ru
Marrex.ru + фильмы: Marrex.ru сайт:
Источник: marrex.ru
фильтр нецензурных выражений вк список
«ВКонтакте» реализовал автоудаление сообщений по ключевым словам
«ВКонтакте» порадовал владельцев пабликов долгожданной функцией: автоматическое удаление нежелательных комментариев.
Если подключить соответствующие фильтры, то будут автоматически удаляться сообщения с нецензурной лексикой, спамом и любыми произвольными словами, которые вы не хотите видеть в своём сообществе.
Фильтр нецензурных выражений удаляет комментарии с ненормативной лексикой на четырёх языках — русском, английском, украинском и казахском.
Для управления фильтрами в меню «Управление сообществом» добавлена специальная вкладка «Журнал действий». Там можно просмотреть список удалённых комментариев и восстановить удалённые случайно. Или добавить автора в чёрный список.
Работа фильтра по ключевым словам полностью зависит от установок модераторов. Например, сайты узкой тематики могут добавить сюда слова, неприятные именно своей аудитории. Скажем, в сообществе любителей Apple будут автоматически удалять все комментарии со словом «Samsung». Естественно, любые фильтры подобного типа легко обходятся заменой букв.
Популярный новостной паблик «Лентач» вчера внёс в стоп-фильтр такие слова:
Пикчер
Рашка
Русня
Колидор
Беларусь
Обамка
Фрустрация
Экспрессо
Извени
Ну, а модераторы сообществ «Тематических медиа» сказали, что новые фильтры не особенно пригодятся, потому что в комментариях и раньше было чисто.
Фильтр нежелательных комментариев Вконтакте
Одной из основных функций социальных сетей является объединение людей, увлеченных одним и тем же хобби или интересующихся одной темой в специальные сообщества. В них можно читать интересный материал, обсуждать предмет группы, писать комментарии и многое другое. И, безусловно, сообщения могут содержать недопустимую информацию, в том числе и матерную лексику. Чтобы сообщество качественно и постоянно функционировало, модераторам необходимо избавляться от недопустимой информации. И сделать это можно двумя способами — поиском и удалением вручную или с помощью использования фильтра комментариев.

Комментарии в меню управления
Что такое фильтр комментариев?
Фильтр — специальный инструмент, созданный для облегчения модераторам и администраторам работу с сообществом.Он автоматически удаляет сообщения по ключевым словам, которые могут изначально находится в базе социальной сети (словарь матерных выражений) или же по введенным вручную. То есть, чтобы ограничить паблик от мата, достаточно просто включить соответствующий фильтр.
Он будет искать на стене и в комментариях нецензурную речь и удалять ее. Словарь матерных выражений создавался профессиональными лингвистами на нескольких языках, в числе которых содержатся украинский и английский. Факт об удалении будет зафиксирован в истории. Однако в данном случае завуалированный мат (с заменой некоторых букв на точки или другие знаки) удален не будет.
Чтобы избавить свое сообщество от мата и от спама полностью, необходимо ввести ключевые слова вручную. Тогда уровень защиты будет увеличен.
Как подключить данный инструмент?
Подключение данного инструмента доступно только пользователю, который обладает правами администратора. Для этого необходимо открыть в управлении сообществом раздел “Комментарии”, в котором и доступно меню редактирования. Чтобы подключить использование фильтра по словарю матерных слов, достаточно просто поставить галочку в верхней графе. Для подключения ключевых слов, вводимых вручную, необходимо поставить галочку во второй графе и вписать слова через запятую. Слово может быть совершенно любым набором символов, количество которых больше одного знака.
В заключении важно сказать, что данный фильтр является очень важным инструментом для контролирования пабликов с открытыми комментариями и большим количеством подписчиков. Отсутствие недопустимых выражений качественно улучшает сообщество. Оно будет гораздо лучше выглядеть со стороны и его будет приятнее использовать подписчикам.
«ВКонтакте» запустила фильтр для удаления нежелательных комментариев
Социальная сеть «ВКонтакте» запустила специальные фильтры для автоматического удаления нежелательных комментариев. Информацию об этом на своей странице разместил пресс-секретарь «ВКонтакте» Георгий Лобушкин.
«В меню «Управление сообществом» — «Информация» Вы можете подключить специальные фильтры для автоматического удаления нежелательных комментариев. Фильтр нецензурных выражений будет удалять комментарии с ненормативной лексикой на четырех языках — русском, английском, украинском и казахском», — пояснили представители соцсети.
Фильтр по ключевым словам поможет избавиться от более широкого спектра комментариев, содержащих заданные администраторами стоп-слова. «Также можно «натравить» его на определенный сорт спама, характерного для Вашего сообщества», — подчеркнули во «ВКонтакте».
Для того чтобы контролировать работу фильтров, разработчики добавили специальную вкладку «Журнал действий» в меню «Управление сообществом»: там можно будет просмотреть удаленные фильтрами комментарии и восстановить те, которые попали под фильтр случайно, или, наоборот, — мгновенно добавить автора в черный список.
Летом 2015 года «ВКонтакте» запустила собственное приложение для работы с фото — Snapster. Как ранее рассказывал РБК представитель «ВКонтакте», у фотоприложения соцсети будут функции, отличающие его от конкурентов (главный игрок на этом рынке Instagram). Основная функция приложения соцсети — это полная синхронизация с соцсетью «ВКонтакте». В частности, в мобильном приложении пользователя будут видны все фотографии, которые загрузили друзья.
Фильтр мата: эволюция
Для поиска и удаления нецензурных выражений в комментариях и сообщениях в соцсетях используются глубокие нейронные сети. Их обучение и применение требует серьезных вычислительных затрат.
Как вариант, мы можем использовать JavaScript на клиентской стороне, чтобы процессор пользователя брал на себя часть нагрузки. Но сложный алгоритм сильно загрузит браузер, он зависнет или даже упадет. Надо искать баланс.
По интернету бродит пара-тройка JS и PHP скриптов с регулярными выражениями. Они частично решают проблему, но являются статичными алгоритмами. Русские пользователи, как известно, очень креативны в «этом вопросе». Каждый раз менять алгоритм не каждый осилит, да и временные затраты будут серьезные.
Читать такие комментарии по многу раз при формировании фильтра и думать о них не очень приятно. Попробуем воспользоваться data science.
За основу возьмем очень простую идею – фильтр мата в виде массива строк длиной от 2х до 7ми символов. Применение фильтра по принципу text.contains определяет с некоторой точностью (70 – 80%), что текст сообщения токсичен.
Именно токсичен, а не с матом, потому что в данный фильтр можно внести слова вроде «лох» или «чмо» (надеюсь, что меня не забанят за них) и другие неугодные нам слова. Например, фамилии президентов и названия национальностей (особенно разговорные) с высокой долей вероятности удалят политические комментарии.
Как вы понимаете, текстовые паттерны «плохих» слов, могут отфильтровать и «хорошие». Поэтому нам надо сформировать фильтр так, чтобы максимально уменьшить фильтрацию обычных слов.
Рецепт
Для генерации подобного фильтра нам понадобятся 2 текстовых файла: bad_words.txt и good_words.txt. Базовые знаний Python и генетический алгоритм – библиотека deap.
Список bad_words формируйте под вашу задачу. В интернете существует значительное количество различных баз слов с классификацией. Я не выкладывал свой bad_words.txt по причине политкорректности.
Устанавливаем deap: pip install deap.
Создаем файл toxic_filter_create.py или jupyter notebook. На ваш выбор.
Загрузка данных
При загрузке убираем строки длиной менее 2х символов, так как длина паттерна начинается с 2х. Этот параметр можно изменить.
После загрузки получаем два списка good_words и bad_words.
Код загрузки данных
with open(file, encoding=’utf-8-sig’) as input_file:
«ВКонтакте» разработал фильтр нежелательных комментариев

Сайт «ВКонтакте» запустил новый инструмент модерации для групп и публичных страниц — фильтр комментариев. Об этом «Ленте.ру» сообщил глава пресс-службы соцсети Георгий Лобушкин.
«Это значительный шаг, облегчающий ведение крупных страниц СМИ и брендов, для которых чистота дискуссий в комментариях на их страницах «ВКонтакте» имеет решающее значение. Некоторые сообщества получают тысячи комментариев от своих подписчиков каждый день. Этот инструмент позволит снизить издержки на модерацию страниц и минимизирует репутационные риски для компаний», — рассказал Лобушкин.
Фильтр позволит в автоматическом режиме удалять нежелательные записи, содержащие нецензурные выражения или любые другие ключевые слова, по выбору администратора страницы.
По словам Лобушкина, нововведение уже сейчас доступно первым 50 миллионам групп, пабликов и страниц, посвященным мероприятиям. Для администраторов будет доступно два варианта модерации — с использованием нецензурных выражений на основе словаря, составленного при участии профессиональных филологов и лингвистов, а также появится возможность составлять свой список стоп-слов. Любые комментарии, попавшие под фильтр, будут автоматически удалены сразу после их публикации.
Фильтр нецензурных слов будет доступен на нескольких языках — русском, украинском, казахском и английском.
«ВКонтакте» — крупнейшая социальная российская сеть с более 300 миллионов зарегистрированных страниц. Каждый день в сеть заходят 80 миллионов пользователей по всему миру, которые ежедневно оставляют на страницах сайта более 20 миллионов комментариев.
Источник: folkmap.ru
ненормативная лексика, ненормативная лексика и ненормативная лексика
После быстрого рытья profanity хранилище, я нашел файл с именем wordlist.txt:

Целиком profanity библиотека — это просто обертка над этим списком из 32 слов! profanity обнаруживает ненормативную лексику, просто ища одно из этих слов.
К моему ужасу, better-profanity а также profanityfilter оба выбрали один и тот же подход:
- better-profanity использования список из 140 слов
- profanityfilter использования список из 418 слов
Это плохо, потому чтоБиблиотеки обнаружения ненормативной лексики, основанные на списках слов, чрезвычайно субъективны.Например, better-profanity Список слов включает в себя слово «сосать». Готовы ли вы сказать, что любое предложение, содержащее слово «сосать», является оскорбительным? Кроме того, любой жестко запрограммированный список плохих слов неизбежно будет неполным — как вы думаете, profanity 32 плохие слова единственные там?

Уже исключив 3 библиотеки, я возлагаю надежды на 4-ю и последнюю: profanity-filter ,
сквернословие-фильтр
profanity-filter использует машинное обучение! Милая!
Оказывается, этодействительномедленный. Вот тест, который я провел в декабре 2018 года, сравнивая (1) profanity-filter (2) моя библиотека profanity-check и (3) profanity (тот, что в списке из 32 слов):

Мне нужно было иметь возможность выполнять много прогнозов в режиме реального времени, и profanity-filter даже близко не был достаточно быстрым. Но, может быть, это классический компромисс между точностью и скоростью, верно?

Ни одна из библиотек, которые я нашел в PyPI, не отвечала моим потребностям, поэтому я создал свою собственную.
Проверка ненормативной лексики здания, часть 1: данные
Я знал, что я хотел profanity-check основывать свои классификации на данных, чтобы избежать субъективности(читай: чтобы можно было сказать, что я использовал машинное обучение), Я собрал объединенный набор данных из двух общедоступных источников:
- набор данных «Твиттер» из т-Дэвидсон / ненависти речи и наступление языка, который содержит твиты соскобленные с Twitter.
- набор данных «Wikipedia» из это соревнование Kaggle опубликовано по алфавиту ИИ разговора команда, которая содержит комментарии от правок страницы обсуждения Википедии.
Каждый из этих наборов данных содержит образцы текста, помеченные людьми вручную через краудсорсинговые сайты, такие как Восьмерка,
Вот как выглядит мой набор данных:

В наборе данных Twitter есть столбец с именем class это 0, если твит содержит ненавистнические высказывания, 1, если он содержит оскорбительные выражения, и 2, если он не содержит ни того, ни другого. Я классифицировал любой твит с class из 2 как «Не оскорбительный» и все другие твиты как «Наступательный»
Набор данных Википедии имеет несколько двоичных столбцов (например, toxic или threat ), которые представляют, содержит ли этот текст такой тип токсичности. Я классифицировал любой текст, который содержаллюбойтипов токсичности как «оскорбительные» и все другие тексты как «не оскорбительные».
Проверка ненормативной лексики здания, часть 2: обучение
Теперь вооружен очищенным, комбинированным набором данных (который вы можете Скачать здесь) Я был готов тренировать модель!
Я пропускаю то, как я очистил набор данных, потому что, честно говоря, это довольно скучно — если вам интересно узнать больше о предварительной обработке наборов текстовых данных, посмотрите это или это,

. представляет любое неизвестное слово, которое для этого предложения in , Любое предложение может быть представлено таким образом как количество the , cat , sat , hat , а также . !

Конечно, в английском языке гораздо больше слов, поэтому в приведенном выше коде я использую fit_transform() метод, который делает 2 вещи:
- Поместиться:изучает словарный запас, просматривая все слова, которые появляются в наборе данных.
- преобразование: превращает каждую текстовую строку в наборе данных в векторную форму.
Обучение: линейный SVM
Модель, которую я решил использовать было линейной опорных векторов (SVM), которая осуществляется scikit-learn «s LinearSVC учебный класс. это а также это являются хорошим введением, если вы не знаете, что такое SVM.
CalibratedClassifierCV в приведенном выше коде существует как оболочка, чтобы дать мне predict_proba() метод, который возвращает вероятность для каждого класса, а не просто классификацию. Вы можете просто проигнорировать это, если последнее предложение не имеет для вас смысла.
Вот один (упрощенный) способ, которым вы можете подумать о том, как работает линейный SVM: в процессе обучения модель узнает, какие слова «плохие» и насколько «плохими» они являются, потому что эти слова чаще встречаются в оскорбительных текстах.Как будто учебный процесс выбирает для меня «плохие» слова, что гораздо лучше, чем с помощью словаря я пишу сам!
Линейный SVM сочетает в себе лучшие аспекты других библиотек обнаружения ненормативной лексики: он достаточно быстрый, чтобы работать в режиме реального времени, и в то же время достаточно надежный, чтобы справляться со многими различными видами ненормативной лексики.
Предостережения
Что, как говорится, profanity-check далеко от совершенства. Позвольте мне быть ясным: принимать прогнозы от profanity-check с зерном соли, потому чтоэто делает ошибки.Например, не очень хорошо подбирать менее распространенные варианты ненормативной лексики, такие как «f4ck you» или «you b1tch», потому что они не появляются достаточно часто в данных обучения. Вы никогда не сможете обнаружитьвсененормативная лексика (люди придумают новые способы уклониться от фильтров), но profanity-check делает хорошую работу по поиску большинства.
профанация проверка
profanity-check является открытым исходным кодом и доступен на PyPI! Чтобы использовать это, просто
$ pip install profanity-check
Как мог profanity-check быть еще лучше? Не стесняйтесь обращаться или комментировать любые мысли или предложения!
Источник: machinelearningmastery.ru