Полноценное использование баз данных (БД) невозможно без систем управления базами данных (СУБД). Таких систем десятки, при этом одни из самых популярных и функциональных в наше время — PostgreSQL и MySQL. В чем их особенности, преимущества и отличия; когда применять ту или иную СУБД — об этом читайте в материале.
Что такое PostgreSQL
PostgreSQL — объектно-реляционная система управления базами данных с открытым исходным кодом, предусматривающая возможность легкого масштабирования и соответствующая стандартам ANSI/ISO.
В PostgreSQL все таблицы представляются в виде объектов, которые могут наследоваться, а все операции с ними выполняются с помощью объектно-ориентированных функций. При этом структура хранимых файлов (и даже записей в них) может сильно отличаться.
Примечание
В качестве сервиса для управления реляционными базами данных PostgreSQL можно использовать RDS for PostgreSQL, имеющий поддержку множества плагинов и типов данных для оперативной обработки информации, высокую надежность и систему комплексного мониторинга.
Базы данных для тестировщика
RDS for MySQL
Профессиональная платформа управления базами данных MySQL

Характеристики и преимущества PostgreSQL
PostgreSQL — одна из самых функциональных реляционных СУБД, направленная, прежде всего, на соответствие стандартам ANSI/ISO и расширяемость.
Главное отличие PostgreSQL от других СУБД — наличие объектно-ориентированных функциональных возможностей, среди которых поддержка концепции ACID (Atomicity, Consistency, Isolation, Durability — атомарность, согласованность, изолированность, долговечность).
PostgreSQL способна справляться с одновременной обработкой нескольких задач, поддерживает большое количество типов данных и вспомогательных инструментов для работы.
- Полная SQL-совместимость.
- Открытый исходный код.
- Расширенные настройки с возможностью создания собственных плагинов и персонализацией параметров.
- Возможность индексирования геометрических (в том числе географических) объектов.
- Наличие расширения PostGIS.
- Функция MVCC для управления параллельным доступом посредством многоверсионности.
- Расширяемость, позволяющая масштабировать PostgreSQL с помощью хранимых процедур.
- Возможность поддерживать некоторые объектно-ориентированные функции.
- Частые обновления.
Примечание
Эта СУБД используется в Apple, Skype, Spotify, Facebook, IMDB и других компаниях.
Что такое MySQL
MySQL — система управления реляционными базами данных (СУРБД), работающая по модели «клиент-сервер» и имеющая открытый исходный код. MySQL предназначена для хранения данных в таблицах, их обработки, структурирования и предоставления незамедлительного доступа к релевантной информации.
Технически MySQL представляет собой механизм для работы со связанными между собой таблицами с данными (например, о товаре или клиентах). При этом работа в MySQL сводится к созданию таблиц с данными и определению связей между ними.MySQL может работать с любыми данными, между которыми можно настроить связи: фото, заметки, задачи, аудио- и текстовые файлы.
Удивительное и невероятное о первичных ключах PostgreSQL: serial, bigserial, UUID v4, ULID, UUID v6
Характеристики и преимущества MySQL
MySQL — самая популярная СУБД в 2020 году, по мнению 53,5% опрошенных профессиональных разработчиков. Популярность обусловлена простотой СУРБД, богатыми функциональными возможностями, встроенными системами безопасности, расширенными возможностями настройки и полной поддержкой SQL-языка. СУРБД не перегружена функциями, поэтому работает быстрее и надежнее многих аналогов.

В MySQL реализована функция разграничения доступа. Например, можно сделать так, чтобы менеджер мог только вносить данные, топ-менеджер — изменять их, а владелец — отслеживать изменения, вносить правки и удалять ненужные сведения.
Примечание
Управление РБД можно осуществлять с помощью сервиса RDS for MySQL. Сервис прост в использовании, но имеет повышенную производительность и надежность, что позволяет применять его в разных сценариях.
- Полная поддержка SQL.
- Открытый исходный код.
- Простота, обеспеченная легкой установкой, понятным интерфейсом и большим количеством сторонних инструментов, упрощающих работу с СУБД.
- Функциональные возможности, включающие большой набор инструментов для разработки проектов разной сложности.
- Безопасность, предопределенная встроенными защитными системами.
- Масштабируемость, позволяющая применять СУРБД для работы с любым объемом данных.
- Повышенная скорость работы.
- Частые обновления.
Примечание
MySQL используется в Google, GitHub, NASA, Tesla, Twitter и других компаниях.
Сравнение функций: в чем разница?
По данным DB-Engines (январь 2022 года), СУБД MySQL занимает второе место в рейтинге популярности СУБД, а PostgreSQL — четвертое.
Несмотря на общее назначение и принцип работы, СУБД имеют отличия.
| Особенность | MySQL | PostgreSQL |
| Open Source | Открытый исходный код, но принадлежащий Oracle | Открытый источник |
| Соответствие требованиям ACID | Частичное соответствие | Полное соответствие |
| Поддержка NoSQL/JSON | Поддержка некоторых функций | Только данных JSON |
| Декларативное секционирование | Поддерживаются | Поддерживаются |
| Логическая репликация | Поддерживаются | Поддерживаются |
| Оконные функции | Поддерживаются | Поддерживаются |
| Вложенные селекты | Да | Да |
| Транзакции | Да | Да |
| Триггеры | Да | Да |
| Возможность хранения только в памяти | Да | Нет |
Когда разработчики выбирают PostgreSQL
PostgreSQL больше подходит для ситуаций, когда:
- нужна поддержка внешних ключей, триггеров и представлений, позволяющих скрывать сложности БД от приложения для отказа от сложных команд SQL;
- важна возможность создания селектов (вложенных подзапросов);
- нужна возможность создания сложных команд SQL (за счет соответствия SQL-стандартам ANSI);
- важна целостность данных;
- требуется поддержка MVCC для предоставления одновременного доступа к базе данных большому количеству пользователей на чтение и запись;
- нужна поддержка NoSQL и разных типов данных;
- предполагается выполнение сложных процедур и расширение БД;
- планируется последующее перемещение БД на другое решение.
Когда разработчики выбирают MySQL
Есть несколько ситуаций, когда MySQL становится приоритетным вариантом для разработчиков. СУРБД выбирают, если:
- важна скорость работы с данными;
- нужно больше функций и возможностей;
- важна безопасность выполняемых операций и надежная защита доступа к данным;
- предполагается работа с сайтами и приложениями;
- нужна гибкость настройки и простота использования.
Что в итоге
PostgreSQL и MySQL — современные системы управления базами данных, которые считаются лидерами по популярности среди разработчиков. Каждая из них имеет сбалансированный набор функций, возможностей и преимуществ. При этом ввиду различий между СУБД их лучше применять для разных целей: PostgreSQL — для обработки сложных запросов и поддержки массивных баз данных, а MySQL — если нужна быстродействующая, понятная и легкая в управлении СУБД.
PostgreSQL и MySQL как самые популярные системы управления базами данных уже несколько лет назад обзавелись своими облачными версиями. При использовании облачной СУБД разработчик получает массу возможностей: большую надежность и отказоустойчивость системы, автоматическое резервное копирование, геораспределенное хранение и дополнительные инструменты безопасности, например, сервис для аудита и защиты баз данных Database Security Service. Сергей Кулаков Cтарший технический писатель SberCloud
Запросите бесплатную консультацию по вашему проекту

Оставить заявку
Подписка
на дайджест
Два раза в месяц присылаем новости сервисов и платформ, кейсы и анонсы мероприятий
Источник: cloud.ru
Изучаем PostgreSQL. Часть 1. Знакомимся с архитектурой

На сегодняшний день существует большое количество различных систем управления базами данных — СУБД, от коммерческих до открытых, от реляционных до новомодных NoSQL и аналогичных.
Одним из лидеров направления СУБД является PostgreSQL и ее различные ответвления, о некоторых из которых мы рассмотрим подробнее.
В этой статье мы начнем говорить о СУБД PostgreSQL, рассмотрим отличия редакций и некоторые особенности архитектуры, а также процесс установки. Но начнем мы с небольшого ликбеза для того, чтобы читатели плохо знакомые с терминологией баз данных могли быстро войти в курс дела.
Итак, схемой мы будем называть логическое объединение таблиц в базе данных, а сама БД это физическое объединение таблиц. Индекс — отношение, которое содержит данные, полученные из таблицы или материализованного представления. Его внутренняя структура поддерживает быстрое извлечение и доступ к исходным данным.
Еще один важный термин, это первичный ключ — частный случай ограничения уникальности, определенной для таблицы или другого отношения, которое также гарантирует, что все атрибуты в первичном ключе не имеют нулевых значений. Как следует из названия, для каждой таблицы может быть только один первичный ключ, хотя возможно иметь несколько уникальных ограничений, которые также не имеют атрибутов, поддерживающих значение null.
Ну и наконец, наверное, самый распространенный термин — транзакция это комбинация команд, которые должны действовать как единая атомарная команда. То есть, все они завершаются успешно или завершаются неудачно как единое целое, и их эффекты не видны другим сеансам до завершения транзакции, и, возможно, даже позже, в зависимости от уровня изоляции. Соответственно, если выполнение хотя бы одной команды внутри транзакции завершилось ошибкой — вся транзакция завершится ошибкой.
Редакции PostgreSQL
В этой статье мы рассмотрим три основные редакции PostgreSQL:
- Классический PostgreSQL;
- Российский Postgres Professional;
- 2nd Quadrant Postgres-XL.
Начнем с классики

Классической редакцией СУБД PostgreSQL является «ванильная» сборка от PGDG, PostgreSQL Global Development Group. PostgreSQL создана на основе некоммерческой СУБД Postgres, разработанной как open-source проект в Калифорнийском университете в Беркли. Название расшифровывалось как «Post Ingres», и при создании Postgres были применены многие ранние наработки БД Ingres.
Именно эту редакцию мы будем рассматривать в конце статьи, когда речь пойдет об установке базы.
Postgres Professional

Сборка Postgres Pro это российская коммерческая СУБД, разработанная компанией Postgres Professional с использованием свободно-распространяемой СУБД PostgreSQL. Но при этом классическая СУБД значительно переработана для соответствия требованиям корпоративных заказчиков и российских регуляторов. Также Postgres Pro входит в реестр российского ПО и имеет действующий сертификат ФСТЭК.
Рассмотрим более подробно основные отличия Postgres Pro Standard от классической PostgreSQL.
Прежде всего, существуют две версии Postgres Pro:
- Postgres Pro Standard
- Postgres Pro Enterprise
Мы сравним редакцию Postgres Pro Standard с актуальной версией PostgreSQL на текущий момент. Прежде всего, стоит отметить, что каждая версия Postgres Pro Standard содержит все функциональные возможности PostgreSQL с дополнительными патчами ядра, одобренными сообществом разработчиков, а также c расширениями и патчами, разработанными непосредственно Postgres Professional. Поэтому Postgres Professional можно считать в определенной степени дополненной версией PostgreSQL.
Автономность и сжатие
Теперь поговорим о технических отличиях. Начнем с автономных транзакций. Как уже упоминалось выше, транзакция это комбинация команд, действующих как единая команда. Технически суть автономной транзакции заключается в том, что эта транзакция, выполненная из основной, родительской транзакции, может фиксироваться или откатываться независимо от фиксации или отката родительской.
То есть, автономная транзакция выполняется в собственном контексте. Если определить не автономную, а обычную транзакцию внутри другой (вложенная транзакция) то внутренняя всегда откатится, если откатится родительская. Такое поведение не всегда устраивает разработчиков приложений.
Посмотрим пример кода на “чистом” SQL.
Insert into temp (msg) values (’init record’); — добавляем запись init record в таблицу temp
3 | 2-nd record:ATX
Как видно из примера, данные, добавленные после отката, с помощью автономной транзакции сохранились, тогда как все остальные были удалены.
Еще одна интересная функция это постраничное сжатие. В PostgreSQL, в отличие от большинства других СУБД, отсутствует сжатие (компрессия) на уровне страниц. В реализации Postgres Pro страницы хранятся сжатыми на диске, но при чтении в буфер распаковываются, поэтому работа с ними в оперативной памяти происходит точно так же, как обычно. Разворачивание сжатых данных и их сжатие происходит быстро и практически не увеличивает загрузку процессора. При этом, операции могут особенно эффективно ускоряться за счет сокращения операций ввода-вывода аналитические запросы, читающие много данных с диска и не слишком часто изменяющие их.
Бег за временем
Важной особенностью PostgreSQL, с которой знаком каждый админ этой БД является необходимость следить за возрастом самой старой транзакции. Дело в том, что если возраст транзакции вплотную приблизится к 2^31 (пол-круга, половина от всех допустимых значений 2^32), то PostgreSQL не сможет больше выдавать номера транзакций и прекратит работу из соображений сохранности данных, требуя ручного вмешательства и проведения очистки (VACUUM). Если же возраст транзакции далек от этого значения, PostgreSQL может гарантировать правильность определения возраста транзакции (с учетом цикличности счетчика). Именно поэтому следует избегать сверхдлинных транзакций, за время которых счетчик успевает увеличиться на 2 миллиарда.

Postgres Pro решает эту проблему за счет использования 64-разрядных счетчиков транзакций. Замена 32-разрядных счетчиков на 64-разрядные отодвигает переполнение практически в бесконечность.
Тяжелый Postgres-XL

Для тяжелых и высоконагруженных систем в семействе PostgreSQL есть версия Postgres-XL (2nd Quadrant Postgres-XL), которая отличается от PostgreSQL иной философией и целями развития, в рамках которых стабильность, корректность и производительность ставятся выше функциональности. Данная редакция направлена на поддержку функций PostgreSQL при распределении рабочей нагрузки по кластеру и нескольких серверов БД. Само название «Postgres-XL» означает «Расширяемая решетка». Для выполнения этих задач Postgres-XL включает в себя дополнительные средства для повышения производительности и безопасности, такие как MPP-параллелизм и расширенная модель разграничения доступа, и охватывает область применения обработки больших объёмов данных, в то время как PostgreSQL в основном нацелен на OLTP (Online Transaction Processing).
Архитектура
В основе работы СУБД PostgreSQL лежит серверный процесс базы данных, выполняемый на одном сервере. Доступ из приложений к данным базы PostgreSQL производится с помощью специального процесса базы данных. То есть клиентские программы не могут получать самостоятельный доступ к данным даже в том случае, если они функционируют на том же ПК, на котором осуществляется серверный процесс.
У каждого серверного процесса есть своя локальная память. В ней находится кэш каталога (часто используемая информация о базе данных), планы запросов, рабочее пространство для выполнения запросов и другое.

Экземпляр СУБД работает с несколькими базами данных. Эти базы данных называются кластером. Хранение данных на диске организовано с помощью табличных пространств. Табличное пространство указывает расположение данных (каталог на файловой системе).
Табличное пространство — позволяет организовать логику размещения файлов объектов базы данных в файловой системе. По умолчанию при установке СУБД создаются два табличных пространства:
- pg_default — используется по умолчанию для баз данных template1 и template0
- pg_global — используется для общих системных каталогов. Для каждой таблицы может быть создано до 3-х файлов:
- файл с данными — OID таблицы
- файл со свободными блоками — OID_fsm
- файл с таблицей видимости — OID_vm.
Рассмотрим подробно те процессы, которые использует PostgreSQL при работе.
Основной процесс это postgres server process. Данный процесс является родителем для всех процессов, связанных с кластером. То есть он порождает все остальные процессы, создает разделяемую память (shared memory). Для каждого клиентского соединения порождается выделенный серверный процесс, который обрабатывает все запросы клиента пока сессия активна.
Максимальное количество пользовательских сессий определяется параметром max_connections (по умолчанию 100). Также, в СУБД существуют различные фоновые процессы, предназначенные для выполнения вспомогательных ролей.
Для сглаживания скорости работы памяти и дисков в PostgreSQL используется буферный кеш. Он состоит из массива буферов, которые содержат страницы (блоки) данных и дополнительную информацию об этих страницах. Размер страницы обычно составляет 8 КБ, хотя может устанавливаться при сборке.
В PostgreSQL используется два уровня представления данных: нижний уровень это страницы и физическое хранение данных в них, и верхний, где используются снимки данных. На нижнем уровне при изменении строки таблицы хранятся несколько версий этой строки, как старые, так и текущая актуальная.
Снимки данных используют информацию о начальном и конечном номере транзакции они отбирают версии строк, дающие согласованную картину на определенный момент времени.
PostgreSQL содержит инструменты анализа и оптимизации разбора текста запроса, по аналогии с тем, как это делается в языках программирования. Сначала анализатор (parser) выполняет первоначальный синтаксический и семантический разбор текста запроса. Результатом работы анализатора является дерево разбора.
Далее запрос перерабатывается с помощью специальных механизмов обработки запросов (правил). В частности, на этом этапе происходит замена представлений на текст запроса, в результате чего дерево разбора существенно изменяется. Планировщик (planner) выбирает для запроса наиболее подходящий в части минимизация стоимости выполнения план.
Итак, мы рассмотрели основные элементы архитектуры СУБД PostgreSQL и в завершении рассмотрим процесс установки данной системы.
Пусть слоники побегают
Процесс установки PostgreSQL достаточно прост и не содержит каких-то особых требований. В качестве примера рассмотрим установку на ОС Ubuntu Linux.
Для начала обновим списки пакетов и установим саму БД.
sudo apt-get update apt-get upgrade apt install postgresql postgresql-contrib
Переключимся на пользователя postgres. Все дальнейшие действия мы будем делать под этой учеткой.
sudo -i -u postgres
И перейдем в командную строку PostgresSQL:
Для выхода из командной строки можно воспользоваться командой:
В результате вы вернетесь в командную строку postgres в Linux.
К настоящему моменту у вас есть только роль postgres, настроенная внутри базы данных. Далее вы можете создать нового пользователя с помощью следующей команды:
sudo -u postgres createuser —interactive
Создадим тестовую базу данных:
CREATE DATABASE otus
equip_id serial PRIMARY KEY,
type varchar (50) NOT NULL,
color varchar (25) NOT NULL,
location varchar(25) check (location in (‘north’, ‘south’, ‘west’, ‘east’, ‘northeast’, ‘southeast’, ‘southwest’, ‘northwest’)),
Мы создали базу Otus в которой есть одна таблица t. Как видно из запроса, у нас есть первичный ключ equip_id, поля type и color типа varchar, а также location – поле может содержать только несколько заданных значений и поле install_date в котором хранится дата. Для того, чтобы получить все данные по базе можно воспользоваться:
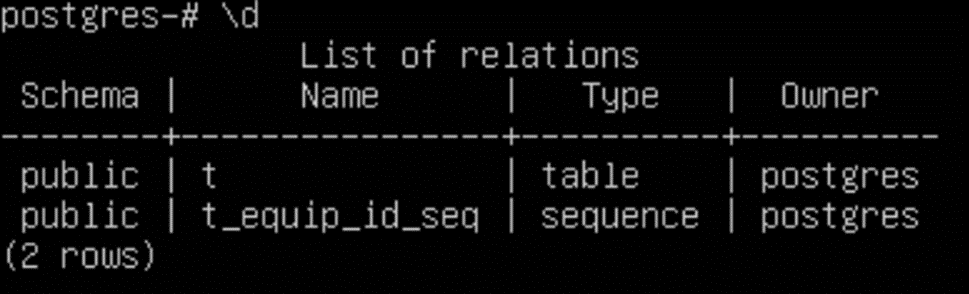
А если нужны данные только по таблице то

Сейчас наша база содержит пустую таблицу t. Добавим в нее одну запись:
INSERT INTO t (type, color, location, install_date) VALUES (‘slide’, ‘blue’, ‘south’, ‘2017-04-28’);
И посмотрим содержимое таблицы:
SELECT pid, query, state, wait_event, wait_event_type, pg_blocking_pids(pid) FROM pg_stat_activity gx

В этой статье мы поговорили об архитектуре PostgreSQL, рассмотрели основные редакции СУБД и выполнили ее установку. Однако для полноценного использования БД этой информации явно недостаточно поэтому в следующих статьях мы подробно рассмотрим резервное копирование, и создание отказоустойчивых конфигураций СУБД PostgreSQL.
P.S.
Тем, кто хотел бы сравнить PostgreSQL с другими СУБД предлагаю воспользоваться следующим ресурсом http://sql-workbench.eu/dbms_comparison.html (Заходить через VPN).
Также приглашаю всех на бесплатный урок курса Postgre SQL: NULL в SQL. Это одна из наиболее неоднозначных концепций, с которыми постоянно сталкиваются разработчики баз данных.
Источник: habr.com
PostgreSQL — объектно-реляционная система управления базами данных
PostgreSQL — это популярная свободная объектно-реляционная система управления базами данных. PostgreSQL базируется на языке SQL и поддерживает многочисленные возможности.
Преимущества PostgreSQL:
- поддержка БД неограниченного размера;
- мощные и надёжные механизмы транзакций и репликации;
- расширяемая система встроенных языков программирования и поддержка загрузки C-совместимых модулей;
- наследование;
- легкая расширяемость.
Текущие ограничения PostgreSQL:
- Нет ограничений на максимальный размер базы данных
- Нет ограничений на количество записей в таблице
- Нет ограничений на количество индексов в таблице
- Максимальный размер таблицы — 32 Тбайт
- Максимальный размер записи — 1,6 Тбайт
- Максимальный размер поля — 1 Гбайт
- Максимум полей в записи250—1600 (в зависимости от типов полей)
Особенности PostgreSQL:
Функции в PostgreSQL являются блоками кода, исполняемыми на сервере, а не на клиенте БД. Хотя они могут писаться на чистом SQL, реализация дополнительной логики, например, условных переходов и циклов, выходит за рамки собственно SQL и требует использования некоторых языковых расширений. Функции могут писаться с использованием различных языков программирования.
PostgreSQL допускает использование функций, возвращающих набор записей, который далее можно использовать так же, как и результат выполнения обычного запроса. Функции могут выполняться как с правами их создателя, так и с правами текущего пользователя. Иногда функции отождествляются с хранимыми процедурами, однако между этими понятиями есть различие.
Триггеры в PostgreSQL определяются как функции, инициируемые DML-операциями. Например, операция INSERT может запускать триггер, проверяющий добавленную запись на соответствия определённым условиям. При написании функций для триггеров могут использоваться различные языки программирования. Триггеры ассоциируются с таблицами. Множественные триггеры выполняются в алфавитном порядке.
Механизм правил в PostgreSQL представляет собой механизм создания пользовательских обработчиков не только DML-операций, но и операции выборки. Основное отличие от механизма триггеров заключается в том, что правила срабатывают на этапе разбора запроса, до выбора оптимального плана выполнения и самого процесса выполнения. Правила позволяют переопределять поведение системы при выполнении SQL-операции к таблице.
Индексы в PostgreSQL следующих типов: B-дерево, хэш, R-дерево, GiST, GIN. При необходимости можно создавать новые типы индексов, хотя это далеко не тривиальный процесс.
Многоверсионность поддерживается в PostgreSQL — возможна одновременнуя модификация БД несколькими пользователями с помощью механизма Multiversion Concurrency Control (MVCC). Благодаря этому соблюдаются требования ACID, и практически отпадает нужда в блокировках чтения.
Расширение PostgreSQL для собственных нужд возможно практически в любом аспекте. Есть возможность добавлять собственные преобразования типов, типы данных, домены (пользовательские типы с изначально наложенными ограничениями), функции (включая агрегатные), индексы, операторы (включая переопределение уже существующих) и процедурные языки.
Наследование в PostgreSQL реализовано на уровне таблиц. Таблицы могут наследовать характеристики и наборы полей от других таблиц (родительских). При этом данные, добавленные в порождённую таблицу, автоматически будут участвовать (если это не указано отдельно) в запросах к родительской таблице.
Использование в веб-проектах
В разработке простых сайтов PostgreSQL используется несколько реже, чем MySQL / MariaDB, но всё же эта пара с заметным отрывом опережает по частоте использования остальные системы управления базами данных. При этом в разработке сложных сайтов и веб-приложений PostgreSQL опережает по использованию MySQL и MariaDB. Большинство фреймворков (например, Ruby on Rails, Yii, Symfony, Django) поддерживают использование PostgreSQL в разработке.
PostgreSQL — надёжная объектно-реляционная свободная СУБД, имеющая широкие возможности и высокую производительность.
Источник: web-creator.ru