
Регистрируем в Telegram новое приложение
Для подключения к Telegram API необходимы api_id и api_hash . Эти параметры выдаются при регистрации приложения в инструментах разработчика (при отсутствии доступа используйте VPN). Для авторизации указываем номер телефона, к которому привязан аккаунт Telegram.
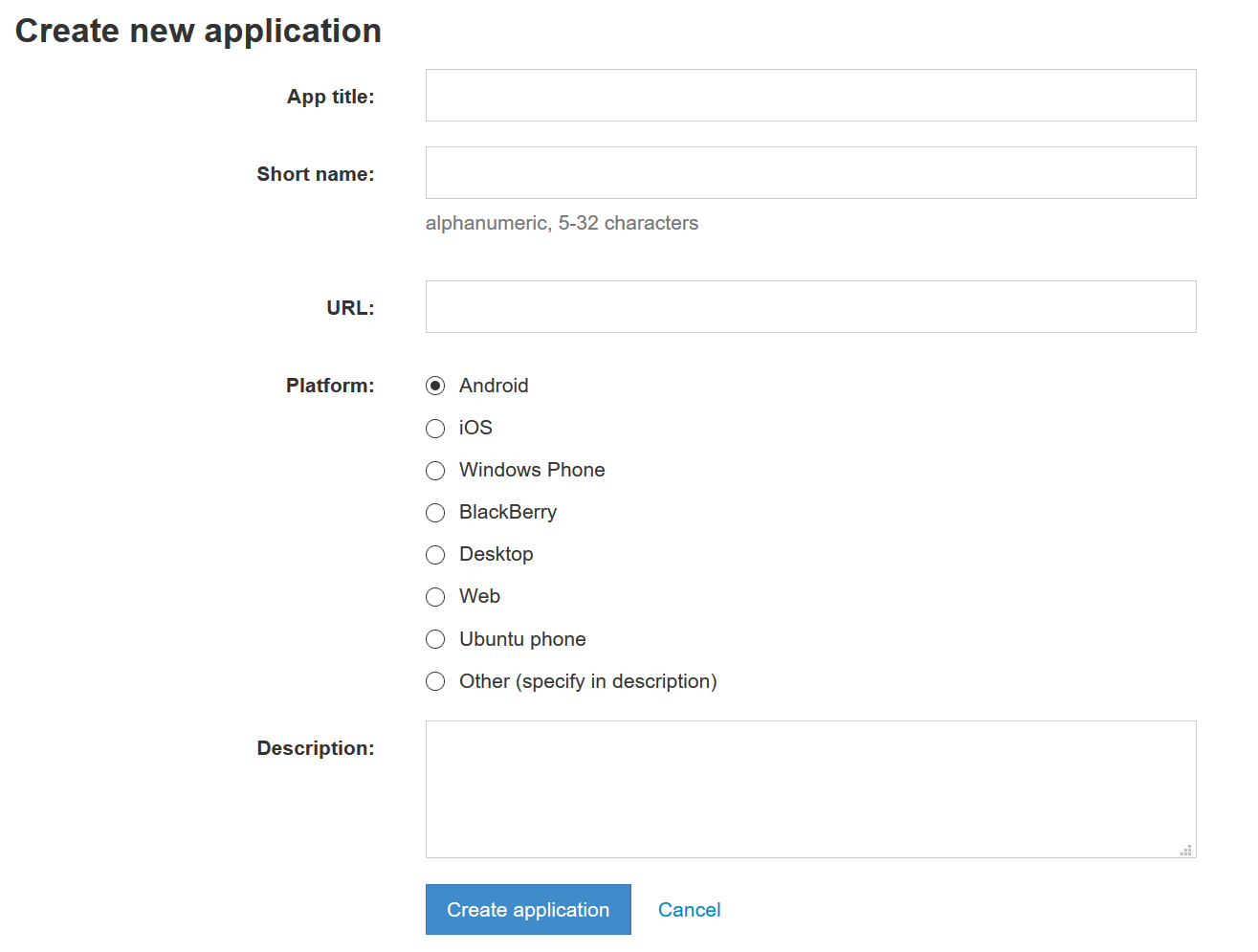
Вводим пришедший в Telegram численно-буквенный код и попадаем на страницу регистрации нового приложения. Заполняем форму, достаточно первых двух граф:
В результате попадаем на страницу конфигурации приложения. Находим оба параметра, а также доступные MTProto-сервера и открытые (публичные) ключи.
Разработка Telegram Bot на Python. (0.1 — Разбираем API Telegram)
Избегая проблем с безопасностью, сохраняем учетные данные в отдельном файле config.ini следующей структуры:
[Telegram] api_id = Telegram-API-ID api_hash = Telegram-API-Hash username = Your-Telegram-Username
Поле username далее будет использоваться лишь для автоматического сохранения сессии под именем username.session . Одному клиенту соответствует одна сессия, учтите это в случае запуска нескольких клиентов.
Создаем клиент Telegram
Начнем с импорта библиотек.
import configparser import json from telethon.sync import TelegramClient from telethon import connection # для корректного переноса времени сообщений в json from datetime import date, datetime # классы для работы с каналами from telethon.tl.functions.channels import GetParticipantsRequest from telethon.tl.types import ChannelParticipantsSearch # класс для работы с сообщениями from telethon.tl.functions.messages import GetHistoryRequest
Встроенные модули configparser и json применяем соответственно для чтения параметров и вывода данных. Из библиотеки Telethon импортируем класс клиента Telegram и класс исключений. Внутренний модуль connection необходим при использовании прокси-сервера. Остальные элементы модуля telethon.tl используются для запросов необходимых нам списков (участников канала/чата и их сообщений).
Теперь считаем учетные данные из config.ini :
# Считываем учетные данные config = configparser.ConfigParser() config.read(«config.ini») # Присваиваем значения внутренним переменным api_id = config[‘Telegram’][‘api_id’] api_hash = config[‘Telegram’][‘api_hash’] username = config[‘Telegram’][‘username’]
Создадим объект клиента Telegram API:
client = TelegramClient(username, api_id, api_hash)
При необходимости прописываем прокси. При использовании протокола MTProxy прокси задается в виде кортежа (сервер, порт, ключ) .
proxy = (proxy_server, proxy_port, proxy_key) client = TelegramClient(username, api_id, api_hash, connection=connection.ConnectionTcpMTProxyRandomizedIntermediate, proxy=proxy)
client.start()
При первом запуске платформа запросит номер телефона, и вслед – код подтверждения. Так же, как если бы вы входили в учетную запись в приложении или браузере.
Для сбора, обработки и сохранения информации мы создадим две функции:
- dump_all_participants(сhannel) заберет данные о пользователях администрируемого нами сообщества channel ;
- dump_all_messages(сhannel) соберет все сообщения. Для этой функции достаточно, чтобы у вас был доступ к сообществу (необязательно быть администратором).
Обе функции будут вызываться в теле функции main , в которой пользователь передаст ссылку на интересующий источник:
url = input(«Введите ссылку на канал или чат: «) channel = await client.get_entity(url)
Касательно написания вызова функций стоит оговориться, что Telethon является асинхронной библиотекой. Поэтому в коде используются операторы async и await. В связи с этим функция main полностью будет выглядеть так:
async def main(): url = input(«Введите ссылку на канал или чат: «) channel = await client.get_entity(url) await dump_all_participants(channel) await dump_all_messages(channel)
Заметим, что из-за асинхронности Telethon может некорректно работать в средах, использующих те же подходы (Anaconda, Spyder, Jupyter).
Рекомендуемым способом управления клиентом является менеджер контекстов with . Его мы запустим в конце скрипта после описания вложенных в main функций.
with client: client.loop.run_until_complete(main())
Собираем данные об участниках
Telegram не выводит все запрашиваемые данные за один раз, а выдает их в пакетном режиме, по 100 записей за каждый запрос.
async def dump_all_participants(channel): «»»Записывает json-файл с информацией о всех участниках канала/чата»»» offset_user = 0 # номер участника, с которого начинается считывание limit_user = 100 # максимальное число записей, передаваемых за один раз all_participants = [] # список всех участников канала filter_user = ChannelParticipantsSearch(») while True: participants = await client(GetParticipantsRequest(channel, filter_user, offset_user, limit_user, hash=0)) if not participants.users: break all_participants.extend(participants.users) offset_user += len(participants.users)
Устанавливаем ограничение в 100, начинаем со смещения 0, создаем список всех участников канала all_participants . Внутри бесконечного цикла передаем запрос GetParticipantsRequest .
Проверяем, есть ли у объекта participants свойство users . Если нет, выходим из цикла. В обратном случае добавляем новых членов в список all_participants , а длину полученного списка добавляем к смещению offset_user . Следующий запрос забирает пользователей, начиная с этого смещения. Цикл продолжается до тех пор, пока не соберет всех фолловеров канала.
Самый простой способ сохранить собранные данные в структурированном виде – воспользоваться форматом JSON. Базы данных, такие как MySQL, MongoDB и т. д., стоит рассматривать лишь для очень популярных каналов и большого количества сохраняемой информации. Либо если вы планируете такое расширение в будущем.
В JSON-файле можно хранить и всю информацию о каждом пользователе, но обычно достаточно лишь нескольких параметров. Покажем на примере, как ограничиться набором определенных данных:
all_users_details = [] # список словарей с интересующими параметрами участников канала for participant in all_participants: all_users_details.append() with open(‘channel_users.json’, ‘w’, encoding=’utf8′) as outfile: json.dump(all_users_details, outfile, ensure_ascii=False)
Итак, для каждого пользователя создается свой словарь данных и добавляется в общий список all_user_details , который записывается в JSON-файл.
Собираем сообщения
Ситуация со сбором сообщений идентична сбору сведений о пользователях. Отличия сводятся к трем пунктам:
- Вместо клиентского запроса GetParticipantsRequest необходимо отправить GetHistoryRequest со своим набором параметров. Так же, как и в случае со списком участников запрос ограничен сотней записей за один раз.
- Для списка сообщений важна их последовательность. Чтобы получать последние сообщения, нужно правильно задать смещение в GetHistoryRequest (с конца).
- Чтобы корректно сохранить данные о времени публикации сообщений в JSON-файле, нужно преобразовать формат времени.
import configparser import json from telethon.sync import TelegramClient from telethon import connection # для корректного переноса времени сообщений в json from datetime import date, datetime # классы для работы с каналами from telethon.tl.functions.channels import GetParticipantsRequest from telethon.tl.types import ChannelParticipantsSearch # класс для работы с сообщениями from telethon.tl.functions.messages import GetHistoryRequest # Считываем учетные данные config = configparser.ConfigParser() config.read(«config.ini») # Присваиваем значения внутренним переменным api_id = config[‘Telegram’][‘api_id’] api_hash = config[‘Telegram’][‘api_hash’] username = config[‘Telegram’][‘username’] proxy = (proxy_server, proxy_port, proxy_key) client = TelegramClient(username, api_id, api_hash, connection=connection.ConnectionTcpMTProxyRandomizedIntermediate, proxy=proxy) client.start() async def dump_all_participants(channel): «»»Записывает json-файл с информацией о всех участниках канала/чата»»» offset_user = 0 # номер участника, с которого начинается считывание limit_user = 100 # максимальное число записей, передаваемых за один раз all_participants = [] # список всех участников канала filter_user = ChannelParticipantsSearch(») while True: participants = await client(GetParticipantsRequest(channel, filter_user, offset_user, limit_user, hash=0)) if not participants.users: break all_participants.extend(participants.users) offset_user += len(participants.users) all_users_details = [] # список словарей с интересующими параметрами участников канала for participant in all_participants: all_users_details.append() with open(‘channel_users.json’, ‘w’, encoding=’utf8′) as outfile: json.dump(all_users_details, outfile, ensure_ascii=False) async def dump_all_messages(channel): «»»Записывает json-файл с информацией о всех сообщениях канала/чата»»» offset_msg = 0 # номер записи, с которой начинается считывание limit_msg = 100 # максимальное число записей, передаваемых за один раз all_messages = [] # список всех сообщений total_messages = 0 total_count_limit = 0 # поменяйте это значение, если вам нужны не все сообщения class DateTimeEncoder(json.JSONEncoder): »’Класс для сериализации записи дат в JSON»’ def default(self, o): if isinstance(o, datetime): return o.isoformat() if isinstance(o, bytes): return list(o) return json.JSONEncoder.default(self, o) while True: history = await client(GetHistoryRequest( peer=channel, offset_id=offset_msg, offset_date=None, add_offset=0, limit=limit_msg, max_id=0, min_id=0, hash=0)) if not history.messages: break messages = history.messages for message in messages: all_messages.append(message.to_dict()) offset_msg = messages[len(messages) — 1].id total_messages = len(all_messages) if total_count_limit != 0 and total_messages >= total_count_limit: break with open(‘channel_messages.json’, ‘w’, encoding=’utf8′) as outfile: json.dump(all_messages, outfile, ensure_ascii=False, cls=DateTimeEncoder) async def main(): url = input(«Введите ссылку на канал или чат: «) channel = await client.get_entity(url) await dump_all_participants(channel) await dump_all_messages(channel) with client: client.loop.run_until_complete(main())
Если для анализа сообщений потребуются не все записи, задайте их число в переменной total_count_limit . Если нужна только сборка сообщений канала, достаточно закомментировать вызов await dump_all_participants(channel) .
Таким образом, с помощью Python и Telethon мы написали скрипт, собирающий и сохраняющий данные и реплики участников сообществ Telegram.
Источник: proglib.tech
Пишем телеграмм бота на Python / Бот по выбору языка программирования

Простая инструкция по созданию легкого и удобного бота по выбору языка программирования.
Для работа с API телеграмма необходимо использовать одну из возможных библиотек. Библиотек много, но давайте сейчас остановимся на pyTelegramBotAPI как на одной из наиболее продвинутых библиотек.
Сперва выполняем её установку в проект. После установки импортируем её, а также устанавливаем API ключ для бота.
Получить ключ для бота можно через другого специального бота в телеграмме. Этот бот называется BotFather. Работать с ботом очень просто и всё что нам нужно сделать, так это обратиться к «папе боту», создать в нём нового бота, придумать название и после этого получить API ключ. Кстати, здесь же вы можете указать описание для бота, фото и прочую инфу. Если захотите, то с этим неплохо можно поиграться.

Вставляем полученный ключ в программу.
Теперь создайте весь необходимый функционал. Весь код представлен ниже:
Наш бот
Сейчас каждый может протестировать нашего бот по этой ссылочке . Как видите, реализация бота это просто и никаких особых усердий не требуется.
Видео на эту тему
Также вы можете просмотреть детальное видео по разработке данного бота:
Дополнительный курс
На нашем сайте также есть углубленный курс по изучению языка Питон . В ходе огромной программы вы изучите не только язык Питон, но также научитесь создавать веб сайты за счёт веб технологий и фреймворка Джанго. За курс вы изучите массу нового и к концу программы будете уметь работать с языком Питон, создавать на нём полноценные ПК приложения на основе библиотеки Kivy, а также создавать веб сайты на основе библиотеки Джанго.
Больше интересных новостей

10 важнейших языков программирования

Введение в регулярные выражения JavaScript

Как написать бота для Telegram за 10 минут?

Новый аналог ChatGPT от Google – что о нем известно?
Комментарии (2)
аскольд 25 декабря 2022 в 18:32
можете пожалуйста весь код.
в том коде только работает (создание игр) и (под мобил устройства)
дайте код пж как на видео
Jin Drew 24 октября 2022 в 14:35
Источник: itproger.com
Как сделать свой личный ChatGPT в Telegram за 5 минут

Бот ChatGPT продолжает стремительно набирать популярность во всём мире и становится наиполезнейшим инструментом для тех, кто ищет быстрый и удобный способ получить нужную информацию.
Однако официально бот доступен только на сайте компании OpenAI и не имеет собственного приложения, что далеко не всегда удобно, особенно для пользователей из России, где доступ к сайту ограничен.
Но выход есть, в начале этого месяца OpenAI выпустила своё API в публичный доступ и теперь ChatGPT можно вывести за пределы своего сайта. В Telegram появилась уже целая куча ботов ChatGPT, однако все они так или иначе требуют свою плату с пользователей.
Поэтому мы решили написать инструкцию о том, как создать своего личного бота ChatGPT в Telegram практически даром. Инструкция рассчитана на рядового пользователя, следуя ей, запустить своего бота сможет даже человек, не имеющий знаний в программировании.
Подготовка
- Для начала вам потребуется аккаунт на сайте OpenAI. Если у вас его до сих пор нет, то в самом конце этой статьи инструкция по его созданию. Для регистрации аккаунта потребуется виртуальный номер, минимальная стоимость которого на текущий момент составляет около 20 рублей.
- Далее включите VPN и перейдите в раздел для разработчиков здесь:

- Создайте API ключ, нажав на копку «Create new secret key». Запишите его, он понадобится позже.
- Затем создайте бота в Telegram. Для этого откройте BotFather и введите команду /newbot.

- Назовите его. Затем пропишите боту ссылку, которая обязательно заканчивается на bot. И сохраните API ключ от бота Telegram. Он также понадобится позже.
- Итого у вас должно быть 2 ключа: OpenAI и Telegram.
Установка
Далее установите Python на свой компьютер. В начале установки обязательно поставьте галочку «Add python.exe to PATH», иначе в консоли не будут работать команды.

- Скачайте готовый код бота на GitHub от пользователя n3d1117. Для этого нажмите на зелёную кнопку Code –> Download ZIP. Распакуйте папку из архива в любое удобное место, но желательно без кириллицы в пути.
- Откройте файл под названием .env.example через любой текстовый редактор (блокнот, notepad++, EmEditor).

- В поле OPENAI_API_KEY=»XXX» вместо XXX вставьте ваш ключ OpenAI
- В поле TELEGRAM_BOT_TOKEN=»XXX» вместо XXX вставьте ваш ключ Telegram-бота.
- В поле ALLOWED_TELEGRAM_USER_IDS=»USER_ID_1,USER_ID_2″ вместо USER_ID_1,USER_ID_2 вставьте символ * – тогда бот будет доступен для всех пользователей. Если вы желаете сделать его доступным только для себя, то введите свой Telegram ID. Узнать его можно здесь.
- После этого переименуйте «.env.example» в «.env».
- Далее кликните на путь папки сверху и введите в нём слово powershell и нажмите Enter. Откроется PowerShell сразу с учётом расположения папки вашего бота.
В открытой консоли пропишите следующие команды по порядку:
python -m pip install —upgrade pip
Установка и/или обновление pip
pip install python-telegram-bot
Установка библиотеки Telegram
pip install openai
Установка библиотеки OpenAI
pip install pydub
Установка аудиобиблиотеки
Также можете скачать FFmpeg для работы с аудио и видео, но это необязательно. Текстовый бот будет работать и без этого дополнения. (Из архива нужно вытащить ffmpeg.exe и поместить в корневую папку).
python -m venv venv
Подготовка к запуску виртуального окружения
venvScriptsactivate
Запуск
pip install -r requirements.txt
Установка подходящих параметров
python bot/main.py
Запуск самого бота
После этого бот должен начать работать. И им уже можно пользоваться. Для отключения бота просто закройте консоль.
Пример успешной работы бота:


Бот будет работать пока запущена консоль. Соответственно, чтобы его выключить, достаточно её закрыть. Чтобы запустить бота повторно, все перечисленные выше команды снова вводить не нужно, достаточно лишь так же открыть PowerShell в папке и прописать всего две команды.
venvScriptsactivate
python bot/main.py
Особенности и ограничения:
- API-версия генерирует текст гораздо быстрее своей бесплатной браузерной версии, примерно на уровне Plus версии.
- API-версия работает всегда, даже в период нагрузок, также вам не требуется VPN для её использования.
- Используйте /help, чтобы получить список доступных команд
- Подобно браузерному ChatGPT, API-версия запоминает информацию в диалоге.
- Чтобы стереть боту память о беседе, используйте команду /reset. Также после этой команды можно ввести уточнение для бота, чтобы направить его в нужное русло. Например, с помощью «/reset Говори только на русском» можно заставить использовать русский язык по умолчанию.
- С помощью команды /image можно генерировать картинки с помощью DALL-E по описанию.
- Через команду /stats можно проверить затраты на использование бота.
- Также вы можете добавить бота в беседу и общаться с ним вместе с друзьями. (для этого нужно разрешить добавление в беседу в настройках BotFather).
А теперь к ограничениям:
Увы, но API не бесплатное, у всех пользователей есть бесплатный пробный период в 3 месяца с момента регистрации. Он также ограничен количеством бонусных долларов, по исчерпанию которых API перестанет работать.

Количество бонусных долларов зависит от даты регистрации вашего аккаунта. На моём аккаунте, который был зарегистрирован в первые дни запуска ChatGPT, было предоставлено бонусов в размере $18. Это очень много, если вы используете бота в одиночку, то вам более чем хватит этого на месяц или два активного использования.
Однако в последнее время новым аккаунтам стали давать более скромный бонус – $5, которого хватит где-то на пару недель активного использования. Статистку использования вы можете отследить на сайте OpenAI или в самом боте по команде /stats.
Также следует отметить ещё пару важных фактов:
- Подключить версию GPT-4 на данный момент нельзя, даже если у вас есть Plus. API GPT-4 на текущий момент находится в закрытом доступе.
- Запущенная через API версия фактически незначительно отличается от браузерной ChatGPT. Браузерная версия была доработана, чтобы быть ассистентом, а также содержит больше уточняющей информации о себе, в то время как API-версия «более обезличенная» и даже не называет себя ChatGPT.
- В этом плане API версия сильно напоминает декабрьский ChatGPT, который даже не мог назвать актуальную дату. Однако всё же знания у ботов общие, поэтому беспокоиться за качество ответов не стоит.
- Для тех кому интересно, по умолчанию в боте используется модель gpt-3.5-turbo. Какие ещё существуют модели можете посмотреть здесь.
Источник: kod.ru