Парсер — программа, которая по заданному алгоритму собирает нужную информацию на сайте. Парсеры часто применяют в маркетинговых целях, чтобы собрать базу для таргетированной рекламы или спам рассылки. Наш парсер будет способен формировать базу участников выбранного сообщества, сохранять базы в txt файле, высчитывать процент пересечения двух баз, объединять две базы в одну без повторов, а также будет доступен ввод сохраненной базы из txt файла.
Подготовка
Для взаимодействия с API Вконтакте мы будем использовать модуль vk. Установить vk можно через pip с помощью команды: pip install vk
Также, чтобы получить сервисный ключ доступа, нам потребуется создать приложение на сайте Вконтакте. Это можно сделать по этой ссылке.
Пишем код
Первым делом давайте импортируем модуль vk, обозначим имена наших будущих функций и напишем авторизацию.
Конструкция if __name__ == «__main__»: нужна чтобы описать, что будет происходить, если запустить эту программу как основную. Другими словами, если импортировать эту программу в другой код как модуль, то все описанные действия в этой конструкции исполняться не будут.
Сделал парсер страниц ВК! «Спарси» своего друга за 10 секунд
Теперь приступим к созданию наших функций. Для того, чтобы собрать данные об участниках группы, мы будем использовать метод API groups.getMembers. Основной параметр этого метода group_id — это id(только цифры) или короткое имя сообщества, эту информацию можно найти в URL сообщества. Параметр v — это версия API, посмотреть актуальную можно тут. Метод возвращает нам данные в виде словаря. “count” — кол-во подписчиков, “items” — список id’шников.
Проблема заключается в том, что этот метод может возвратить нам максимум 1000 id’шников. Но благодаря параметру offset, который отвечает за смещение от начала полного списка участников(по умолчанию 0), и циклу for, мы можем получить список всех участников сообщества.
Теперь напишем функции сохранения базы в файл и чтения базы из файла.
Далее реализуем две функции, использующие множества.
Весь основной функционал готов, осталось лишь дописать в конструкцию if __name__ == «__main__»: какие функции мы хотим применить.
Например, давайте найдем пересечение аудиторий двух групп про кино, объединим их аудиторию без повторов и сохраним в txt файл.
1. https://vk.com/hdkinomania
2. https://vk.com/bobfilm
Код будет выглядеть вот так:
Пересечение аудиторий у этих двух сообществ — 1,65%
На этом все! При желании, немного изменив код, можно собирать больше информации о пользователях.
Парсинг данных через api vk и google sheets api на python
Появилась потребность собирать статистику постов из группы в контакте и затем проанализировать реакции подписчиков на конкретные посты. Если переформулировать на выходе стоит задача с заданной периодичностью снимать показания статистики постов в вк и сохранять их.
Я не профессиональный программист и не претендую, поэтому решил сделать все довольно просто. При помощи api VK забирать посты из группы, собираю нужный мне датафрейм и записываю данные в гугл таблицу, так же через api.
Парсинг групп и пользователей Telegram, VKontakte, Twitter и других соц.сетей в одном видео
Может быть это и не самое оптимальное решение,
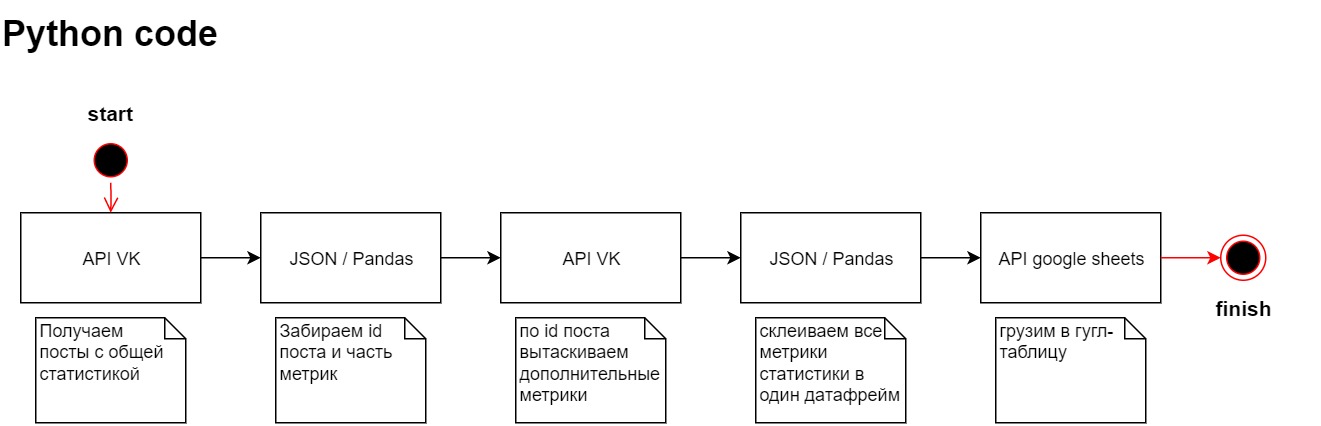
Настраиваем API VK
В этом блоке мы хотим собрать статистику постов из группы vk.
Для начала работы нам нужен user_token из vk. Мне понравилась видеоинструкция здесь, коротко и по делу.
Токен держим в секрете. Переходим в https://dev.vk.com изучаем документацию API.
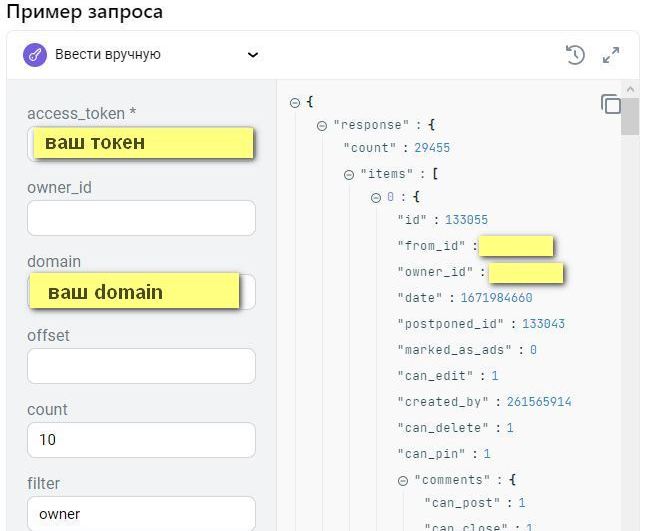
Прямо на сайте документации можем попробовать дернуть запрос.
Для этого нам нужно access_token, domain, count, v, filter.
access_token – получили на прошлом шаге. domain – название группы вы увидите в url название группы например https://vk.com/adminsclub. count – количество постов которые можем дернуть. v – версия api. filter – хотим получить только посты от группы устанавливаем owner.
Прописываем логику сбора
Импортируем библиотеку requests. Дергаем тестовый запрос. Поcле анализа структуры решаю, что мне нужен раздел items
Отдельное поле в статистики количество фотографий для поста, я не нашел.
Через цикл перебираем каждый пост и считаем количество фото, если фотографии нет скрипт ловит ошибку. Обрабатываем ошибку и ставим 0. Собираем новый список с полями id поста и количество фото.
Пишем обработчик. Вызываем pandas
Переводим cловарь в df. Импортируем метод from pandas import json_normalize
Оставляем нужные атрибуты и переводим дату в другой формат.
В переменной post_id запихиваем id наших постов.
Я бы хотел обогатить свою статистику более расширенными измерениями
Из документации по api о которой рассказывал выше подобрал метод status.getPostReach
В методе обнаружил новый аргумент owner_id, его можно найти в настройках группы.
Делаем еще один запрос и новые данные сохраняем в датафрейм df_stat_post
Теперь приступим к сборке объединяем все наши датафреймы, накидываем дополнительные метрики.
Далее наши данные преобразовываем для загрузки в гугл таблицу.
Грузим в google sheet через api
Есть готовые библиотеки для работы с google sheet например pygsheets, но мне было важно поработать с API поэтому легких путей не искал.
Прежде чем загрузить надо настроить наш api прекрасная статья, в который пошагово написано и даст возможность поиграться с листами https://habr.com/ru/post/483302/
После подключения к листу. Находим последнюю заполненную строку.
В моем примере я заполняю последние 10 строк ровно по количеству постов которые я получил из get запроса. Подготавливаем шаблон для запроса, заполняем шаблон данными какие ячейки заполняем и заполняем. Далее выполняем запрос. Готово
После написания этого кода мне требовалось запускать его каждый час и принял решение арендовать сервер, установить туда docker и через crontab запускать.
Name already in use
If nothing happens, download GitHub Desktop and try again.
Launching GitHub Desktop
If nothing happens, download GitHub Desktop and try again.
Launching Xcode
If nothing happens, download Xcode and try again.
Launching Visual Studio Code
Your codespace will open once ready.
There was a problem preparing your codespace, please try again.
Latest commit
Git stats
Files
Failed to load latest commit information.
README.md
Парсер групп Вконтакте
Программа собирает посты и комментарии с социальной сети Вконтакте, отбирает сообщения по ключевым словам нечетким сравнением и проверкой орфографии, сохраняет сообщения в нереляционную базу данных MongoDB. Реализован телеграмм бот для удаленного управления.
Windows 11
Python 3.10.5
MongoDB 5.0.9
В Linux Ubuntu и macOS возникли ошибки с библиотекой pyenchant (для проверки орфографии).
Выполните следующие действия
- Установите MongoDB (MongoDB Community Server, https://www.mongodb.com/try/download)
- Подключитесь к интерфейсу:
- Создайте БД с именем ‘vk’:
- Создайте коллекцию с именем ‘user’:
- Установите все зависимости:
- Добавить словарь для поддержки русского языка в pyenchant
Словари в папке dictionary: ru_RU.aff и ru_RU.dic
Скопировать в папку со словарями:
C:UsersusernameAppDataLocalProgramsPythonPython39Libsite-packagesenchantdatamingw64shareenchanthunspell - Создайте свое приложение (Standalone-приложение): https://vk.com/apps?act=manage
Входные данные для получения токена
client_id — id приложения
scope — права доступа (https://dev.vk.com/reference/access-rights)
Запрос для получения токена:
https://oauth.vk.com/authorize?client_id=111111redirect_uri=https://oauth.vk.com/blank.htmlresponse_type=tokenhttps://gshimki.ru/razgovor/24/kak-parsit-vk-python» target=»_blank»]gshimki.ru[/mask_link]Пишем простой парсер ВК на Python
Парсер — программа, которая по заданному алгоритму собирает нужную информацию на сайте. Парсеры часто применяют в маркетинговых целях, чтобы собрать базу для таргетированной рекламы или спам рассылки. Наш парсер будет способен формировать базу участников выбранного сообщества, сохранять базы в txt файле, высчитывать процент пересечения двух баз, объединять две базы в одну без повторов, а также будет доступен ввод сохраненной базы из txt файла.
Подготовка
Для взаимодействия с API Вконтакте мы будем использовать модуль vk. Установить vk можно через pip с помощью команды: pip install vk
Также, чтобы получить сервисный ключ доступа, нам потребуется создать приложение на сайте Вконтакте. Это можно сделать по этой ссылке.
Пишем код
Первым делом давайте импортируем модуль vk, обозначим имена наших будущих функций и напишем авторизацию.
Проблема заключается в том, что этот метод может возвратить нам максимум 1000 id’шников. Но благодаря параметру offset, который отвечает за смещение от начала полного списка участников(по умолчанию 0), и циклу for, мы можем получить список всех участников сообщества.
На этом все! При желании, немного изменив код, можно собирать больше информации о пользователях.
Источник: medium.com
Парсер лайков из ВКонтакте

В данном уроке по PHP парсерам обойдёмся без PHP. Будем собирать ID пользователей, лайкнувших заданный товар. Для этой цели воспользуемся API социальной сети ВКонтакте.
Можно, конечно, пойти стандартным путём и парсить ВК с помощью PHP и cURL, но когда у сайта есть рабочее API, то удобнее пользоваться им. В частности, в ВК можно получить через встроенное API самые разные данные, но при этом есть ограничение на частоту запросов.
Для успешного старта работы с API VK стоит изучит официальную документацию и скудные примеры. Для себя выбрал вариант работы по Open API. Кстати, запросы к API VK отправляются по технологии AJAX, а ответы приходят в формате JSON, не зря мы ранее знакомились с этой схемой данных.
Чтобы можно было работать с API социальной сети нужно в своём скрипте подключить JS библиотеку //vk.com/js/api/openapi.js и создать Standalone приложение.

Далее в настройках видим ID приложения, а также надо задать домен и адрес сайта с нашим парсером.

Теперь мы готовы к написанию парсера лайков. В качестве подопытного выберем маркет с товарами бренда Кухни Мария.

Парсер лайков во ВКонтакте без PHP
Код файла index.html.
Парсер информации из ВКонтакте .wrapper < max-width: 600px; margin: 0 auto; >h1, p < text-align: center; >.action_form < max-width: 560px; margin: 0 auto; >.action_form input, .action_form textarea < width: 100%; >.action_form textarea < min-height: 100px; >input[type=»text»] < font-size: 1em; min-height: 36px; box-sizing: border-box; >input[type=»submit»], input[type=»button»] < padding: 8px 12px; margin: 12px auto; font-size: 1.2em; font-weight: 400; line-height: 1.2em; text-decoration: none; display: inline-block; cursor: pointer; border: 2px solid #007700; border-radius: 2px; background-color: transparent; color: #007700; >input[type=»submit»]:hover, input[type=»button»]:hover < background-color: #009900; color: #fff; >.result < border: 1px dotted #000; width: 100%; height: auto; overflow-y: auto; margin: 0px auto; padding: 10px; >.copyright < text-align: center; >.copyright a < color: #000; >.copyright a:hover < text-decoration: none; >.red < color: #770000; >.green
Парсер лайков на товары из ВК
Собираем список ID пользователей, которые лайкнули заданный товар.
© Идея и реализация — ПЧ // 28.05.2017 г.
jQuery(document).ready(function($) < $(‘#btn_action_likes’).click(function() < function get_vk_market_likes(vk_owner_id, vk_post_id, vk_post_type) < // Инициализация VK API VK.init(< apiId: ID приложения >); $(‘#result’).html(‘
Загрузка данных .
‘); VK.Api.call(‘likes.getList’, , function(data) < if(data.response) < $(‘#result’).html(»); data.response.items.forEach(function(item, i, arr) < $(‘#result’).html($(‘#result’).html() + «
» + item + «
«).hide().fadeIn(‘slow’); >); > else < $(‘#errors_block’).html($(‘.app_alert’).html() + ‘
‘ + data.error.error_code + ‘// ‘ + data.error.error_msg + ‘
‘); > >); > var vk_url = $(«#vk_url»).val(); if(vk_url) < $(‘#result’).html(»); $(‘#errors_block’).html(»); vk_url = vk_url.slice(vk_url.indexOf(«w=product») + 9).split(‘_’); var vk_owner_id = parseInt(vk_url[0]); var vk_post_id = parseInt(vk_url[1]); var vk_post_type = ‘market’; get_vk_market_likes(vk_owner_id, vk_post_id, vk_post_type); >else < $(‘#errors_block’).html($(‘#errors_block’).html() + «
Введите адрес страницы с товаром
«).hide().fadeIn(‘slow’); > return true; >); >);
При запуске парсера не забудьте в настройке apiId: ID приложения поставить ID своего приложения.
Алгоритм работы парсера лайков следующий. Мы задаём адрес карточки нужного нам товара. Скрипт из URL достаёт ID маркета и товара, далее делает запрос к API ВК с целью получить список ID пользователей, которые поставили лайки заданному проекту кухни. Для получения информации по лайкам используется метод likes.getList.
Затем список ID пользователей выводится на экран. Потом полученную информацию можно использовать для настройки таргетированной рекламы в социальной сети.

Особенности работы с API VK
Запросы к API VK можно делать только с заданного в приложении домена. Если попробовать сделать AJAX запрос с другого сайта, то вывалится ошибка ограничения кроссдоменных запроосов.

В примере приведён очень простой вариант парсера. В более сложных случаях нам бывает нужно, например, вначале спарсить категории (альбомы) магазина, а потом товары и лайки. В таких случаях следует делать запросы последовательно и вложенными друг в друга, чтобы не было проблем с асинхронной подгрузкой данных.
Также обратите внимание на то, что число возращаемых методом API результатов ограничено 1000. Но нередко бывают записи или товары, которые собирают по несколько тысяч лайков или репостов. В этом случае надо пользоваться рекурсией и вызывать методы со смещением, параметр offset.
Парсер лайков из ВК написан без применения PHP, в скрипте использовался только JS и открытое API социальной сети. После небольших доработок этот же парсер можно применять для сбора информации по лайкам для постов, фото, видео и пр.
Ранее планировал, что это статья будет завершающей, но, возможно, позже выйдет ещё одна публикация на тему автоматического постинга информации в CMS, на примере WordPress. Это тоже полезный навык для разработчиков парсеров. Данные не только нужно собирать, но и потом куда-то с пользой применять.
Источник: seorubl.ru