Кому не будет приятно, если его мнение, написанное в комментариях к посту, найдёт много согласных? Разумеется, никому. Но кроме поднявшейся самооценки у такого вида активности есть и практическая польза. О том, как накрутить лайки на комментарии в Ютубе и зачем, я вам и расскажу.
На что влияют лайки на комментариях в Ютубе
Начнём с обсуждения практической части. Чем может вам помочь лишний лайк под комментарий? Казалось бы, такая мелочь, а ведь зачем-то их накручивают. Западные социальные сети по механизму работы отличаются от российских. И когда речь идёт о комментах всё также несколько отличается от того же ВКонтакта и Одноклассников.
Здесь в зависимости от популярности вашего мнения определяется место комментария в ветке обсуждений. Именно поэтому, если вы используете эту область для раскрутки, обратите внимание и на отметки пользователей под вашим мнением.
Бесплатные сервисы
Начнём с самого интересного – перечислим сайты, которые позволяют получить желаемое совершенно бесплатно. Бесплатность, правда, условная – чаще всего вам придётся тратить на получение отметок «Мне нравится» кучу времени. честно говоря, из всего множества бесплатных сайтов только один предлагает нужный функционал. Зато среди платных вариантов выбор приличный. Так что, если не устроит бесплатный, просто читайте следующий раздел. Также, раз уж сайт один, здесь я приложу краткую инструкцию по использованию Social gainer.
Как накрутить лайки на комментарии YouTube и попасть в ТОП
- Открываем сайт и авторизуемся через социальную сеть.
- Зарабатываем баллы, выполняя задания из вкладки «Заработать».
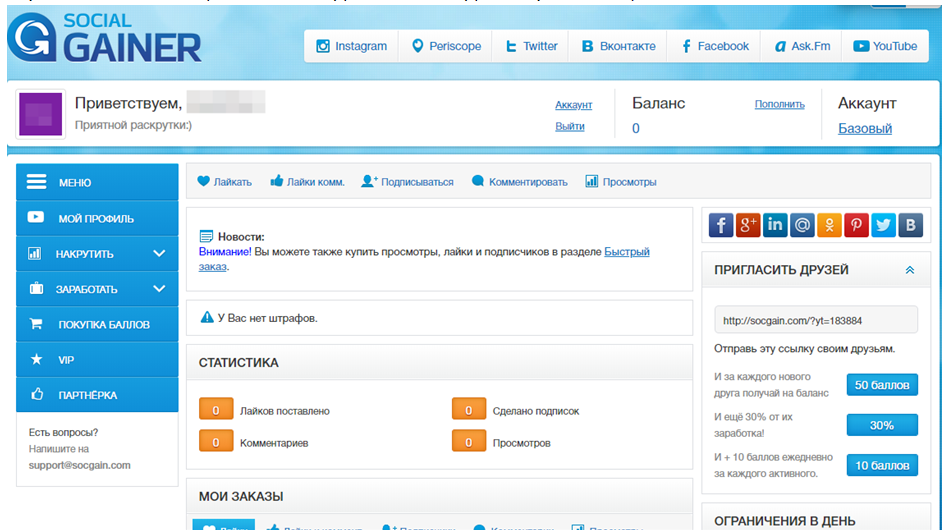
- Переходим на вкладку «Накрутить» и выбираем «Лайки ком».
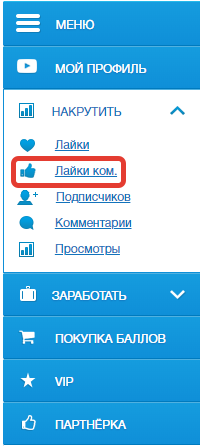
- Выбираем количество нужной активности, вставляем ссылку и запускаем накрутку.
Платные сервисы
А вот и наш «пир» – среди сервисов, предлагающих платный функционал, огромное количество вариантов, которые станут хорошим решением и в плане дизайна, и в плане функционала. Вы можете пойти в интернет и найти что-то получше, а можете воспользоваться моими предложениями. Чуть ниже я вставлю таблицу со сравнением цены за сотню лайков. Так что, если вам плевать на моё мнение об этих сайтах, можете просто прокрутить немного ниже и оценить примерные траты.

- Smmlaba
Неплохой сервис, быстро выполняющий свои обязательства. Позволяет в короткие сроки получить желаемое, потратив всего 80 рублей за сотню;

Накрутка лайков на комментарии Ютуб | Живые и настоящие оценки людей!
- Youliker
Об этом сервисе мне известно немного меньше, но отзывы вполне хорошие. Здесь стоимость будет чуть меньше – 70 рублей.
Используя этот сервис, знайте: я за него не ручаюсь. К тому же, стоимость сотни отметок «Мне нравится» – 99 рублей.
| Сервис | Smmlaba | Youliker | Smmyt |
| Цена за 100 лайков | 80 | 70 | 99 |
Примеры накрученных лайков на комментарии
Вы, возможно, не верите в то, что кто-то действительно накручивает отметки «Мне нравится» на комментарии YouTube. Но есть одна простая хитрость, которая работает со всеми социальными сетями и позволяет обнаружить жуликов – накрученное очень резко выделяется на фоне остальных постов или комментов. Часто такое можно наблюдать, например, под политическими публикациями. Чтобы создать иллюзию действительно весомого и толкового мнения люди прибегают к такой хитрости.
Так поступают не только с политическими комментариями. Тем не менее, именно так и можно определить накрученное мнение – абсолютная глупость с парой сотней отметок «Мне нравится» рядом.
Заключение
Как накрутить лайки на комментарии в Ютубе? Люди привыкли привлекать внимание к своему контенту, а не мнению. Тем не менее, и эта сфера тоже может стать хорошим способом продвинуть свой профиль. Но бесплатного функционала здесь маловато – скорее всего, вам всё же придётся немного раскошелиться, чтобы получить желаемое.
Читайте далее:

Как постоянно получать бесплатные лайки и не заморачиваться

Накрутка зрителей на стрим. Насколько это эффективно?
Преимущества живых лайков в Инстаграм и их роль в продвижении

Сервисы для покупки лайков в Инстаграм: пошаговая инструкция на примере Kwork

Насколько эффективна накрутка лайков в Ютубе?
Источник: smmx.ru
Предсказание количества лайков у комментария в YouTube
Наверняка у каждого хотя бы раз было такое желание, чтоб написать комментарий и получить массу лайков за него. Как никак, человек — существо социальное и одобрение этого самого социума порой очень хочется. Но тут возникает вопрос: а что нужно написать, чтобы получить максимальное количество лайков? И для этого можно использовать машинное обучение! В любой непонятной ситуации применяй машинное обучение.
430 открытий
На самом деле, это довольно непростая задача, требующая не только обработки комментариев, но и определения контекста, в котором он размещён. Но никто же не заставляет нас собирать квантовый суперкомпьютер, верно? Для простого обзора можно обойтись и более простыми инструментами.
Итак, для начала нужно собрать данные для обучения. В качестве источника таковых возьмём площадку YouTube. Уж где где, а на YouTube полно самых различных комментариев. К тому же в сообществах популярных каналов очень распространены локальные мемы, то есть некоторые слова и словосочетания, имеющие некий знаковый символ в этом сообществе. Употребление таких локальных мемов при написании комментариев, теоретически, должно увеличивать количество лайков, а значит несколько упрощать нам задачу.
Ключевым параметром будет выступать, естественно, количество лайков комментария, а признаками будут, во-первых, сам текст комментария, а во-вторых, разница между датой публикацией видео и комментария, так как очевидно, что чем позже от даты выхода видео размещён комментарий, то тем меньше лайков он соберёт. По второму признаку могут быть исключения в виде видео годовалой или более давности, которые по какой-то причине YouTube начал выдавать в рекомендациях у пользователей, после чего в комментариях к оным видео начинается активность, но мы подобные брать не будем.
Для извлечения данных воспользуемся YouTube Data API v3. Первым делом надо получить API ключ. Это сделать просто, однако весьма заковыристо и сходу непонятно, поэтому быстро пробегусь по шагам:
1. Перейти на сайт Console Google Cloud Platform (console.cloud.google.com)
2. Зайти под аккаунтом Google
3. Создать проект
4. Создать новый API
5. Найти YouTube API v3
6. И включить его
Также, чтобы пользоваться этим API, необходимо скачать библиотеку google-api-python-client:
pip install google-api-python-client
После получения ключа API можно начинать парсить комментарии. В качестве цели возьмем ролики популярного в ру сегмент канала “Utopia Show”. Вначале загрузим нужные библиотеки и определим необходимые переменные:
import os import googleapiclient.discovery import csv import tqdm API_KEY = «your_API_key» VIDEO_IDS = [«Ywpd8M6wfHc», «sskg_JguH28», «JDKqXmOX52Q», «k8FIVugHGSg»] COMMENT_COUNT = 1000 MAX_RESULT = 100
Теперь напишем функцию для парсинга комментариев по id видео, под которыми они размещены:
# Функция для скачивания комментариев по id видео def get_comments(video_id, nextPageToken=None): # Disable OAuthlib’s HTTPS verification when running locally. # *DO NOT* leave this option enabled in production. os.environ[«OAUTHLIB_INSECURE_TRANSPORT»] = «1» api_service_name = «youtube» api_version = «v3″ youtube = googleapiclient.discovery.build( api_service_name, api_version, developerKey = API_KEY) request = youtube.commentThreads().list( part=»id,snippet», maxResults=MAX_RESULT, pageToken=nextPageToken, videoId=video_id, order=»relevance» ) response = request.execute() return response
Ещё одну функцию для получения даты публикации видео по её id:
# Функция для скачивания даты выхода видео по id def get_video_date_published(video_id): # Disable OAuthlib’s HTTPS verification when running locally. # *DO NOT* leave this option enabled in production. os.environ[«OAUTHLIB_INSECURE_TRANSPORT»] = «1» api_service_name = «youtube» api_version = «v3″ youtube = googleapiclient.discovery.build( api_service_name, api_version, developerKey = API_KEY) request = youtube.videos().list( part=»snippet,contentDetails,statistics», ) response = request.execute() return response.get(«items»)[0].get(«snippet»).get(«publishedAt»)
Ну и наконец, основную функцию, которая использует две предыдущие для парсинга данных и записи их в csv файл:
После того, как получили данные начинаем их обрабатывать. Поместим данные из ранее полученного файла в дата фрейм:
import pandas as pd df = pd.read_csv(‘comments.csv’)
Сначала посмотрим на гистограмму количества лайков:
df[‘likeCount’].hist(bins=50)
Как видно, число комментариев с нулевым или близким количеством лайков зашкаливает, а это плохо для модели, так как модель будет стараться выдать нулевое значение, угадывая чуть ли не в половине случаев. Поэтому, чтобы исправить это, применим к значениям количества лайков функцию log(x + 1). Прибавление единицы здесь нужно, чтобы не было проблем с нулевыми значениями. Эта функция уже реализована в библиотеке numpy, ею и воспользуемся:
import numpy as np df[‘logLikeCount’] = np.log1p(df[‘likeCount’])
В дальнейшем, чтобы привести подобные значения обратно к числу лайков, нужно использовать функцию np.expm1.
Далее, обрабатываем даты публикаций комментария и видео и находим разницу между ними в секундах, здесь всё просто:
Теперь необходимо обработать текст — в нём нужно убрать знаки препинания, стоп-слова, выделить слова с одной основой и привести всё это в пригодный для машины вид. Чтобы убрать знаки препинания, а заодно и любые другие символы кроме русских букв, можно воспользоваться регулярными выражениями:
import re regex = re.compile(‘[^а-я А-Я]’) text = regex.sub(‘ ‘, text)
Для отбора стоп-слов есть специальная библиотека nltk:
import nltk from nltk.corpus import stopwords from nltk.tokenize import word_tokenize nltk.download(‘stopwords’) nltk.download(‘punkt’) word_tokens = word_tokenize(text) filtered_sentence = [w for w in word_tokens if not w in stop_words]
А для приведения слов к своей основной форме можно пропустить их через стемминг:
from nltk.tokenize import word_tokenize from nltk.stem.snowball import SnowballStemmer word_tokens = word_tokenize(text) filtered_sentence = [stemmer.stem(w) for w in word_tokens]
Объединяя всё вышеуказанное, получаем функцию, обрабатывающую все тексты, поступающие ей на вход:
import nltk from nltk.corpus import stopwords from nltk.tokenize import word_tokenize from nltk.stem.snowball import SnowballStemmer import re import tqdm nltk.download(‘stopwords’) nltk.download(‘punkt’) # Функция обрабатывает тексты для дальнейшего использования def process_text(texts): stemmer = SnowballStemmer(language=’russian’) stop_words = set(stopwords.words(‘russian’)) regex = re.compile(‘[^а-я А-Я]’) process_texts = [] for text in tqdm.tqdm(texts): text = text.lower() # Удаляет любые символы, кроме русских букв text = regex.sub(‘ ‘, text) # Разбивает текст на отдельные слова word_tokens = word_tokenize(text) # Убирает стоп слова и пропускаем через стемминг оставшиеся filtered_sentence = [stemmer.stem(w) for w in word_tokens if not w in stop_words] process_texts.append(‘ ‘.join(filtered_sentence)) return process_texts df[‘textProcessed’] = process_text(df[‘textOriginal’])
Осталось только привести слова в удобоваримый для компьютера вид. С этим нам поможет векторизация, однако здесь есть один нюанс — векторизатор нужно тренировать только на обучающей выборке, поэтому его применим, когда будем делить данные на обучающие и валидационные. Кстати о них:
from sklearn.feature_extraction.text import CountVectorizer from sklearn.model_selection import train_test_split X = df[[‘textProcessed’, ‘publishedDifference’]] y = df[‘logLikeCount’] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) # Векторизация обработанных слов vectorizer = CountVectorizer() X_train_vec = vectorizer.fit_transform(X_train[‘textProcessed’]) X_test_vec = vectorizer.transform(X_test[‘textProcessed’]) # Изменяет размерность массива разности дат публикаций, чтобы соединить с векторизированит текстами X_train_pub = np.array(X_train[‘publishedDifference’]).reshape((-1,1)) X_test_pub = np.array(X_test[‘publishedDifference’]).reshape((-1,1)) # Объединяет вектора слов и разности дат публикаций X_train = np.append(X_train_vec.toarray(), X_train_pub, axis=1) X_test = np.append(X_test_vec.toarray(), X_test_pub, axis=1)
Ну и наконец, ради чего всё это затевалось, обучение модели. Обучать будем на модели градиентного бустинга из библиотеки CatBoost. Модель возьмём без дополнительных параметров, укажем лишь случайное зерно и функцию потерь в виде MAE:
from catboost import CatBoostRegressor catboost = CatBoostRegressor(loss_function=’MAE’, random_seed=0, silent=True) catboost.fit(X_train, y_train) pred = catboost.predict(X_test)
Для оценки качества модели используем MAE. Как мы помним, ключевой параметр — количество лайков — был преобразован с помощью функции np.log1p, поэтому применение MAE сразу к предсказанным данным нам почти ничего не даст. Для наглядности сначала преобразуем данные, а уже потом применим MAE:
from sklearn.metrics import mean_absolute_error pred_int = np.expm1(pred).astype(int) y_test_int = np.array(np.expm1(y_test).astype(int)) mae = mean_absolute_error(pred_int, y_test_int) print(‘MAE =’, mae)
output: MAE = 56.221666666666664
Ещё для полноты картины выведем первые 30 предсказанных значений и реальных:
print(«pred — true») for i in range(30): print(f» — «)
output: pred — true 0 — 5 0 — 0 0 — 0 0 — 0 0 — 0 0 — 0 69 — 10 0 — 0 0 — 1 0 — 20 0 — 1 0 — 0 0 — 0 0 — 1 0 — 0 0 — 0 0 — 0 56 — 104 0 — 0 0 — 23 0 — 0 0 — 0 0 — 0 52 — 5737 0 — 0 0 — 1 0 — 3 0 — 0 0 — 0 0 — 0
Как видно, данная модель хорошо предсказывает те комментарии, которые в принципе не наберут лайки или наберут очень мало. В дальнейшем, чтобы нарастить точность модели на остальных комментариях, можно учитывать контекст, в котором они размещены.
Источник: vc.ru
Статистика Youtube канала — как смотреть + 7 сервисов


Редактор портала Otzyvmarketing.ru. Работаю в сфере интернет-маркетинга с 2010 года.
Поделитесь статьей с друзьями и коллегами
YouTube – самый популярный видеохостинг для создания каналов, распространения личных видео, рекламных кампаний, а также для продвижения товаров и услуг. Чтобы следить за собственным успехом, оценить правильность выбранной стратегии, эффективность работы канала, необходимо анализировать его статистику. Из этой статьи вы узнаете, как смотреть статистику ютуб-канала с помощью встроенных возможностей, а также сторонних сервисов.
Как смотреть статистику канала в Ютуб
Анализ статистики ютуб-канала поможет оценить, насколько эффективны отдельные ваши видео и сам канал.
На какие показатели стоит обращать внимание:
- статистика просмотров ролика
- демографические данные зрителей
- уровень роста подписчиков
- как зрители взаимодействуют с контентом
- каков доход от просмотра роликов
Смотреть статистику можно непосредственно на площадке Youtube, а также на сторонних сервисах. Есть бесплатные и платные сервисы, среди которых можно подобрать те, которые наиболее подходят для ваших целей и задач.
Аналитика внутри самого Youtube
Аналитика самого Ютуб, а именно YouTube Analytics доступна для администратора канала. После того, как вы опубликовали и начали продвигать контент, появляется информация для анализа. Для этого нужно, чтобы прошло некоторое время после создания канала.
В разделе «Творческая студия» есть вкладки, в которых содержится информация о канале и о его контенте. Чтобы зайти туда и увидеть статистику, нажмите вверху справа на аватар.

В столбце слева выберите «Аналитика».

Здесь есть такие разделы, как Обзор, Контент, Аудитория, Исследование.
Во вкладке «Обзор» видны данные по нескольким главным параметрам:
- информация в режиме реального времени, где вы можете увидеть число просмотров всех видео в разные месяцы и дни;
- сколько по времени просматривались ролики;
- количество подписчиков.
Здесь отображается и наиболее популярный контент за конкретное время. Пользователи, которые принимают участие в партнерской программе, могут увидеть отчеты по доходам. В этом разделе отображаются персональные отчеты с информацией об эффективности канала.
Также в разделе «Обзор» можно получить следующую информацию:
- Наиболее востребованный контент за определенный временной период.
- Текущая статистика (в течение последнего часа, либо на протяжении 48 часов).
- Из раздела «Сюжеты» можно узнать об эффективности отдельных сюжетов за 7 дней.

В разделе «Контент» вы можете увидеть данные о просмотрах видео за последние 28 дней, время просмотра и источники, откуда приходят зрители. Также есть аналитика по загруженным видео и прямым эфирам. Все это помогает собрать информацию о том, как зрители ищут те или иные ролики, как взаимодействуют с контентом, что смотрят.
Из раздела «Аудитория» можно узнать:
- количество зрителей (как постоянных, так и уникальных);
- подписчики – их количество и демографические данные;
- видео, которое помогает аудитории расти;
- время, когда зрителей больше всего на канале;
- возраст, а также пол зрителей;
- какие еще каналы смотрят подписчики;
- какие видео наиболее интересны для подписчиков;
- сколько времени просматривалось видео;
- топ регионов;
- наиболее популярные языки субтитров.
В разделе «Исследование» видно, что пользователи ищут на Ютуб и какие запросы наиболее популярны. Это касается не только подписчиков канала, но и других зрителей. Также в этом разделе можно найти отчет о запросах на Ютубе: самые распространенные запросы среди тех, которые были сделаны за последние 28 дней.
Кроме того, есть возможность посмотреть аналитику всех видео по отдельности.

Наиболее важный раздел в «Аналитие» – «Обзор», он предоставляет следующую информацию:
- сколько раз было просмотрено видео
- время просмотра роликов в часах
- сколько человек подписались на канал благодаря ролику
- среднее время просмотра видео
Такой параметр, как «Удержание аудитории» помогает понять, насколько видео является интересным для зрителей. Если процент досматриваемости падает быстро, это означает, что ролик скучный. Возможно, вам стоит сделать больший акцент на самых важных моментах.
В рубрике «Охват» отображается следующая информация:
- показы
- CTR для значков видео
- из каких источников зрители находят это видео
- в каком контенте содержится упоминание о видео
- время просмотра видео
- просмотры
- уникальные пользователи
Раздел «Взаимодействие» содержит в себе следующую информацию:
- сколько по времени просматривалось видео
- средняя продолжительность просмотра
- уровень удержания аудитории с момента загрузки
- процент лайков
В разделе «Аудитория» видно количество зрителей (постоянных, уникальных и новых), сколько подписчиков пришли с конкретного видеоролика.
Источник: otzyvmarketing.ru