А еще лучший двигатель прогресса — кооперация. Всегда можно улучшить уже существующее опен-сурс решение и закинуть пулл-реквест, чтобы всем пользователям сразу стало лучше 🙂 На этих ботах все равно никак не заработать — смысл обременять себя ненужными серверными тратами, когда другие люди уже берут их на себя?
Чьорт, сам забыл уже свои урлы репозиториев, спасибо, что поправили!
Честь Вам и хвала за войсибота!
Автор поста банально не изучил существующие решения. Это грубое упущение.
А вообще, у меня давно была идея (ещё до появления Telegram) сделать что-то похожее для телефонных звонков. Но сделалось вот что. И да, я тебе рассказывал как-то про свой проект. Жду всех в гости :).
Сделал share аудиозаписи из whatsapp — не сработало 🙁
Алсо, недавно вышел гугл дуплекс 🙂 у меня все входящие автоматически теперь говорят с гуглоассистентом, а поднимаю трубку я только когда что-то важное вижу.
Никита, а как преобразовать звуковые файлы из записей АТС менеджеров отдела продаж для дальнейшего анализа?
как переделать аудио файл в голосовое сообщение в телеграм /// telegram лайфхак
Комментарий удален по просьбе пользователя
А на базе чего распознаёт? Амазон, Яндекс? Дорого выходит? За распознавание голоса довольно кусачие тарифы на сколько помню:/
Wit бесплатный, Google Speech можно настроить и платить по $0.006 за 15 секунд, Nanosemantics ребята недавно написали и я их добавил — пока не просят денег 🙂
А у wit разве нет лимита 15-20 сек за одно обращение? Он умеет длинные аудио распознавать?
Войси автоматически бьёт на интервалы в 15-20 секунд 🙂
Я просто в доке нашёл только метод POST/speech и GET/speech которые принимают по 20 сек файлы:) Ещё есть Streaming audio, но как я понял сам он не умеет на куски резать и надо ему по 10 сек скармливать файлы, и подумал что такое не пойдёт:/ или там ещё как то можно?
Войси автоматически бьёт на интервалы в 15-20 секунд 🙂
А если обрежет на середине слова? Тогда ж криво распознает по идее, нет?
Лучшп, чем без распознавания вовсе :3
Там ещё есть Streaming audio, по идее он как раз позволяет избежать этих склеек, отправляя по 10 сек кусочки файла и в режиме реального времени возвращает текст, или это не так работает?
Wit так не умеет.
И по поводу голосовых — я их просто удаляю. 😉 Слушаю крайне редко. И всегда пишу новым собеседникам, что записи мне слушать неудобно, некогда и так далее.
Если у них времени на меня нет, то у меня — тем более.
Не, колонки — это тема, их просто неправильно используют. Я, например, купил себе несколько колонок, таскаю по участку рядом с домом, и слушаю любимый музон — кому это мешает? Да никому. Сосед, вон, радио слушает — мне не мешает, далеко всё-таки.
Когда же колонку тащат за собой по улице — это зашквар.
Ну я как раз про уличных таскателей. На участке или даче, конечно, самое то-)
единственное исключение — люди на велосипедах, имхо. Так их сзади слышно. И они быстро проезжают дальше
Слишком много чести — распознавать! Значит, собеседник тебя не уважает, не бережёт твое время, а ему что-то должен?
Телеграм, как записать видео сообщение и голосовое.
Да, это очень удобная фича, особенно радуют заказчики дающие техзадание в виде войсмэйлов. На 10 минут
а телефонные звонки вы тоже не любите?
или речь касается только записи, не живого разговора?
Только записи, разумеется. Звонки я люблю, потому что связь двусторонняя.
Зачем?
У всех остальных критический недостаток?
Отлично! Я буду пользоваться, часто записываю аудио тк нет времени писать текст (сказать быстрее).
п.с. проблема не в том, что не времени, а в том что когти длинные и русский хромает — отсюда и популярность голосовых.
У Вас странные аргументы!
Если Вам записывают 2-х минутное аудио и 1,5 минуты из них эээ-кают .. я Вам сочувствую! Я же записываю лаконичные и краткие аудио, в случаях, когда мне действительно неудобно.. и мои собеседники/сотрудники/партнеры не против)
Единственное, в чем я вижу недостаток- не всем удобно сразу прослушать аудио, в этом может помочь Денис со своим ботом!
По-моему, удобно)
Голосовое же нужно прослушать от и до. И желательно в тихой располагающей обстановке.
Голосовые я иногда слушаю. Но вечером, после работы. Вам удобно их записывать, а мне их удобно слушать вечером. Паритет.
Плюс по голосу нет поиска, что иногда удобно в будущем
В Ваших словах есть правда, и да, прослушивать не всегда удобно или приятно !
Но выбор каждого пользоваться данной услугой или нет. Я уверена, в Вашем случае, клиенты/ сотрудники/друзья знают о Вашем отношении к аудио, но это не значит, что оно НЕ подходит всем.
Что значит — «пользоваться данной услугой или нет»?
Мне присылают голосовые — что мне делать, если я не могу тут же их прослушать?
Наверное, видите, какие я тут пишу тексты, длинные и понятные. Такие же я пишу в мессенджерах. Мне проще чётко написать собеседнику, что необходимо, выделить основную тему, а не использовать голосовые.
Честно напишу, что я никогда не использовал голосовые как исходящие. Я понимаю всецело, что человек может быть занят. Что ему «прямщас» не удобно ответить. Именно поэтому в качестве средства коммуникации я обожаю электронную почту, email — ты просто пишешь когда удобно, а тебе отвечают, когда им удобно.
p.s. мне набить длинный текст не западло. я уважаю русский язык, равно как и любой другой, могу набить такую же простыню на инглише и на дойче. каждый свой текст я набиваю так, чтобы меня понял собеседник.
Я не знаю, как Вы читаете, может, по слогам, а я читаю по диагонали.
Когда видишь текст размером даже во весь экран, глаза быстро пробегаются, и находят ключевые фразы — на это нужны доли секунды!
А дальше либо приступаешь к решению проблемы, либо пропускаешь до более подходящего момента.
Уважаемый, по слогам дети читают, а отвлекаться от дороги находясь за рулем не советую даже на пару секунд. Боком вам выйдет однажды чтение «опусов ни о чём» даже по диагонали.
Я никогда не отвлекаюсь от дороги, это плохая привычка. Для звонков есть BT, а чтобы взглянуть на уведомления, достаточно остановки перед светофором.
Если же там будут голосовые, а не текст, я много времени после старта потрачу. Да ещё напрягайся, разбирай, что там хотели сказать.
Текстовое же уведомление с проблемой — это повод остановиться на обочине.
Без регистрации и смс слить все свои разговоры рандомному чуваку который сделал бота
В популярном мессенджере с русскими корнями появился ещё один способ общения. В этой статье вы узнаете: что за способ, как им пользоваться и как отключить. Поехали!
Но вчера я не мог записывать голосовые, кнопка с изображением микрофона куда-то пропала. А на её месте появилось иконка, похожая на значок Инстаграма. При нажатии на неё начинается запись селфи-видео. Кстати, интересная, эксклюзивная и, возможно, полезная функция. Лично мне понравилась!

Как вам такое нововведение? Лично мне нравится. Ведь хорошо, когда есть выбор.
Поставьте 5 звезд внизу статьи, если нравится эта тема. Подписывайтесь на нас Telegram , ВКонтакте , Instagram , Facebook , Twitter , YouTube .
На телефоне


Кроме того, вы можете поставить запись на удержание:
- Кликните на микрофон и дождитесь начала записи аудио;
- Сделайте свайп вверх по кнопке с замочком.
А хотите узнать, как записать видео в кружочке в Телеграм? Вам поможет другая наша статья на сайте, обязательно переходите на нее после прочтения этой статьи.
- Если вы решили записать аудио в ручном режиме, месседж будет отправлен автоматически;
- Если вы поставили запись на удержание, нужно будет кликнуть на значок в виде квадрата – он появится над строкой для ввода текста.


Приведенная выше инструкция применима к девайсам, работающим под управлением операционной системы Андроид и к Айфонам. Разобрались с мобильной версией – пора переходить к десктопному приложению.
На компьютере

- Откройте беседу и задержите палец на аудио;
- Дождитесь появления стрелки в верхнем правом углу;

К сожалению, других опций пока не предусмотрено – загрузить документ сразу же на смартфон не получится.

Держать не надо
Мало кто знает, но во время записи аудио вовсе необязательно удерживать палец на иконке микрофона. Если вы планируете рассказать другу долгую историю, есть 2 способа облегчить себе задачу.
Во-вторых, можно открыть нужный чат и поднести смартфон к уху. Экран устройства погаснет, и вы почувствуете короткую одиночную вибрацию. Это будет означать, что запись началась автоматически. Убрав телефон от уха, вы сможете прослушать аудио перед отправкой.
Отменить быстро
Удалить запись поможет соответствующая иконка в левой части экрана.
Источник: 1svoimi-rukami.ru
Telegram бот с offline распознаванием голосовых и генерацией аудио из текста
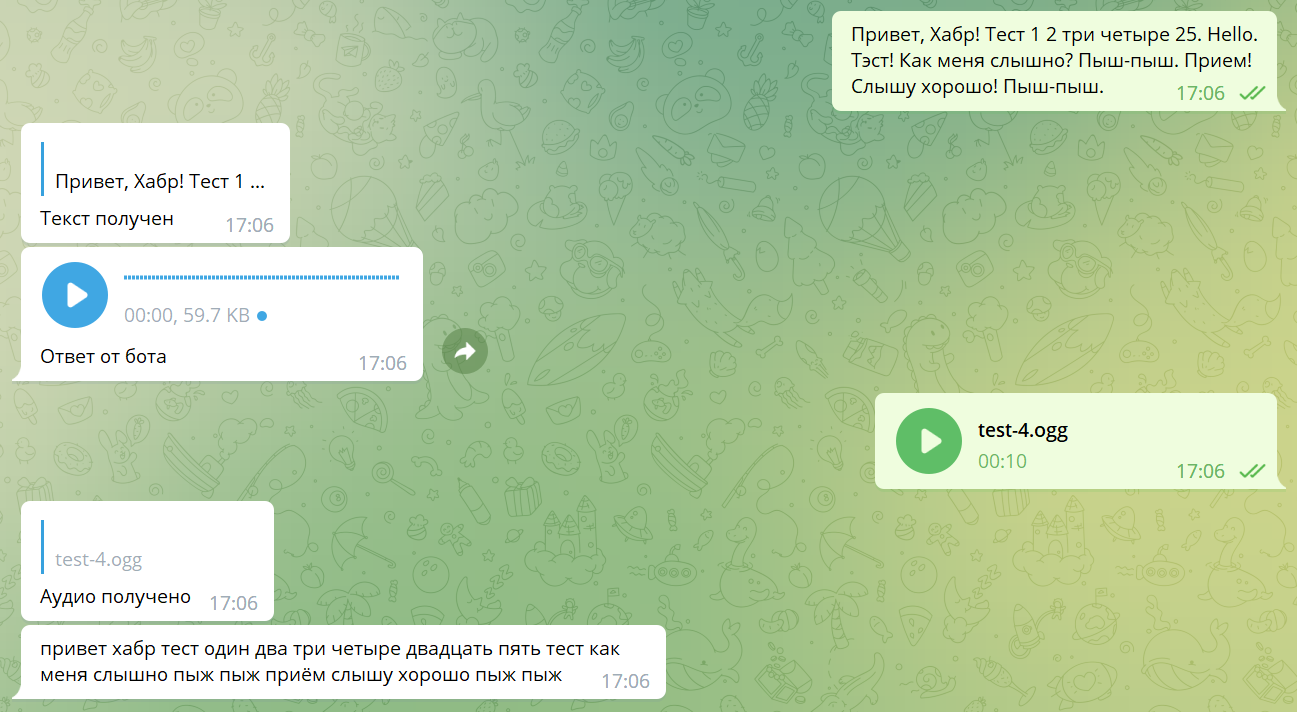
Всем привет! После прочтения постов про голосового ассистента (первый, второй) и сервис Silero, мне стало интересно поиграться с offline распознаванием аудио, а также обратным преобразованием текста в аудио. И как все начинающие разработчики я сделал своего Telegram бота. Просто Telegram – это удобный и мобильный интерфейс для взаимодействия с чем угодно. В своем пет-проекте я применил: Python, aiogram, Vosk, Silero и ffmpeg.
Этот проект не призван заменить существующие решения. Просто им было интересно заниматься в свободное время и учиться писать код на Python. Проект работает под Windows, но с небольшими изменениями запустится и под другими ОС.
Главное отличие проекта от примеров из Vosk и Silero – легкость использования, т.к. вся инициализация параметрами по умолчанию проходит в отдельном классе. Остается лишь создать экземпляр класса и передать в него текст или путь до аудио файла.
Под offline работой подразумевается, что проект полностью работает на одной машине и не использует сторонние сервисы, кроме Telegram. Можно не запускать Telegram бота, а только скачать модели и отдельно поиграться с распознаванием или генерацией аудио.
Для удобства работы я разбил проект на 3 файла:
- bot.py – код Telegram бота
- stt.py – код преобразования аудио в текст, Speech to Text
- tts.py – код преобразования текста в аудио, Text to Speech
Код Telegram бота
Бот построен на асинхронной библиотеке для Telegram – aiogram, которая позволяет достаточно легко создать скрипт простого бота для чтения и отправки сообщений.
Бот в Telegram – это как отдельный пользователь, которым можно управлять через API. Его нужно создать в самом Telegram и получить токен. Процесс создания и получения токена не описываю, т.к. это легко найти в интернете.
Ниже представлен пример скрипта бота.
Хэндлер – это функция, реагирующая на какое-то событие. В нашем случае на команду /start или /help бот ответит сообщением.
По сути наш бот должен реагировать на получение сообщения с текстом и аудио. Поэтому добавим хэндлеры для реагирования на получение текста и аудио.
При получении текста мы отправляем ответ, что получили текст. Затем конвертируем текст в аудио и отправляем голосовое сообщение. В конце удаляем временный файл.
Этот хэндлер реагирует на голосовые, аудио и любые документы, т.к. не понятно какой файл пришлет пользователь. Скрипт скачивает файл на диск. В описании aiogram написано, что файл должен быть менее 20 Мб иначе придется скачать другим способом. Я пробовал отправлять короткие сообщения, так что не проверял это. Файл с аудио конвертируем в текст и отправляем ответ.
В конце удаляем временный файл.
Код распознавания аудио, Speech to Text
Распознавать аудио будем с помощью offline проекта Vosk. Нам нужно только скачать модель для нейросети и поместить в папку models/vosk. Модель представляет собой архив. Просто создайте папку model и поместите содержимое архива туда, а затем закиньте папку model в models/vosk.
В файле stt.py есть класс, который проводит инициализацию модели Vosk параметрами по умолчанию и предоставляет метод для конвертации аудио в текст. Vosk может работать только с wav файлами, поэтому тут используют ffmpeg для конвертации.
Ffmpeg — набор open-source библиотек для конвертирования аудио- и видео в различных форматах. Для Windows скачайте набор exe файлов с сайта проекта и поместите файл ffmpeg.exe в папки models/vosk и models/silero.
class STT: «»» Класс для распознавания аудио через Vosk и преобразования его в текст. Поддерживаются форматы аудио: wav, ogg «»» default_init = < «model_path»: «models/vosk/model», # путь к папке с файлами STT модели Vosk «sample_rate»: 16000, «ffmpeg_path»: «models/vosk» # путь к ffmpeg >def __init__(self, model_path=None, sample_rate=None, ffmpeg_path=None ) -> None: «»» Настройка модели Vosk для распознавания аудио и преобразования его в текст. :arg model_path: str путь до модели Vosk :arg sample_rate: int частота выборки, обычно 16000 :arg ffmpeg_path: str путь к ffmpeg «»» self.model_path = model_path if model_path else STT.default_init[«model_path»] self.sample_rate = sample_rate if sample_rate else STT.default_init[«sample_rate»] self.ffmpeg_path = ffmpeg_path if ffmpeg_path else STT.default_init[«ffmpeg_path»] self._check_model() model = Model(self.model_path) self.recognizer = KaldiRecognizer(model, self.sample_rate) self.recognizer.SetWords(True) def audio_to_text(self, audio_file_name=None) -> str: «»» Offline-распознавание аудио в текст через Vosk :param audio_file_name: str путь и имя аудио файла :return: str распознанный текст «»» # Конвертация аудио в wav и результат в process.stdout process = subprocess.Popen( [self.ffmpeg_path, «-loglevel», «quiet», «-i», audio_file_name, # имя входного файла «-ar», str(self.sample_rate), # частота выборки «-ac», «1», # кол-во каналов «-f», «s16le», # кодек для перекодирования, у нас wav «-» # имя выходного файла нет, тк читаем из stdout ], stdout=subprocess.PIPE ) # Чтение данных кусками и распознование через модель while True: data = process.stdout.read(4000) if len(data) == 0: break if self.recognizer.AcceptWaveform(data): pass # Возвращаем распознанный текст в виде str result_json = self.recognizer.FinalResult() # это json в виде str result_dict = json.loads(result_json) # это dict return result_dict[«text»] # текст в виде str
Метод STT.audio_to_text принимает путь до аудио файла. Ffmpeg конвертирует файл в нужный формат, а затем модель Vosk через recognizer распознает текст. В конце возвращаем распознанный текст.
Кстати, если знаете рабочий способ, как в ffmpeg передать байты и получить результат в байтах без сохранения файла на диск, то напишите в комментариях.
stt = STT() print(stt.audio_to_text(«test-1.ogg»))
Код генерации аудио, Text to Speech
Генерировать аудио будем с помощью offline модели проекта Silero. Нам нужна модель для нейросети, но при первом запуске она сама скачается по URL из настроек по умолчанию (замените URL, если вам нужна другая модель). Также нам нужно скачать ffmpeg и положить в папку models/silero.
В файле tts.py есть класс, который проводит инициализацию модели Silero параметрами по умолчанию и предоставляет метод для конвертации текста в аудио. По умолчанию Silero генерирует аудио в wav, но т.к. он занимает много места, то я конвертировал wav в ogg через ffmpeg.
class TTS: «»» Класс для преобразования текста в аудио. Поддерживаются форматы аудио: wav, ogg «»» default_init = < «sample_rate»: 24000, «device_init»: «cpu», «threads»: 4, «speaker_voice»: «kseniya», «model_path»: «models/silero/model.pt», # путь к файлу TTS модели Silero «model_url»: «https://models.silero.ai/models/tts/ru/v3_1_ru.pt», # URL к TTS модели Silero «ffmpeg_path»: «models/silero» # путь к ffmpeg >def __init__( self, sample_rate=None, device_init=None, threads=None, speaker_voice=None, model_path=None, model_url=None, ffmpeg_path=None ) -> None: «»» Настройка модели Silero для преобразования текста в аудио. :arg sample_rate: int # 8000, 24000, 48000 — качество звука :arg device_init: str # «cpu», «gpu»(для gpu нужно ставить другой torch) :arg threads: int # количество тредов, например, 4 :arg speaker_voice: str # диктор «aidar», «baya», «kseniya», «xenia», «random»(генерит голос каждый раз, долго) :arg model_path: str # путь до модели silero :arg model_url: str # URL к TTS модели Silero :arg ffmpeg_path: str # путь к ffmpeg «»» self.sample_rate = sample_rate if sample_rate else TTS.default_init[«sample_rate»] self.device_init = device_init if device_init else TTS.default_init[«device_init»] self.threads = threads if threads else TTS.default_init[«threads»] self.speaker_voice = speaker_voice if speaker_voice else TTS.default_init[«speaker_voice»] self.model_path = model_path if model_path else TTS.default_init[«model_path»] self.model_url = model_url if model_url else TTS.default_init[«model_url»] self.ffmpeg_path = ffmpeg_path if ffmpeg_path else TTS.default_init[«ffmpeg_path»] self._check_model() device = torch.device(self.device_init) torch.set_num_threads(self.threads) self.model = torch.package.PackageImporter(self.model_path).load_pickle(«tts_models», «model») self.model.to(device) def _get_wav(self, text: str, speaker_voice=None, sample_rate=None) -> str: «»» Конвертирует текст в wav файл :arg text: str # текст до 1000 символов :arg speaker_voice: str # голос диктора :arg sample_rate: str # качество выходного аудио :return: str # путь до выходного файла «»» if text is None: raise Exception(«Передайте текст») # Удаляем существующий файл чтобы все хорошо работало if os.path.exists(«test.wav»): os.remove(«test.wav») if speaker_voice is None: speaker_voice = self.speaker_voice if sample_rate is None: sample_rate = self.sample_rate # Сохранение результата в файл test.wav return self.model.save_wav( text=text, speaker=speaker_voice, sample_rate=sample_rate ) def text_to_ogg(self, text: str, out_filename: str = None) -> str: «»» Конвертирует текст в файл ogg. Модель игнорирует латиницу, но поддерживает цифры числами. :arg text: str # текст кирилицей :return: str # имя выходного файла «»» if text is None: raise Exception(«Передайте текст») # Делаем числа буквами text = self._nums_to_text(text) # Генерируем ogg если текст < 1000 символов if len(text) < 1000: # Возвращаем путь до ogg ogg_audio_path = self._get_ogg(text) if out_filename is None: return ogg_audio_path return self._rename_file(ogg_audio_path, out_filename) # Разбиваем текст, конвертируем и склеиваем аудио в один файл texts = [text[x:x+990] for x in range(0, len(text), 990)] files = [] for index in range(len(texts)): # Конвертируем текст в ogg, возвращаем путь до ogg ogg_audio_path = self._get_ogg(texts[index]) # Переименовываем чтобы не затереть файл new_ogg_audio_path = f»_» os.rename(ogg_audio_path, new_ogg_audio_path) # Добавляем новый файл в список files.append(new_ogg_audio_path) # Склеиваем все ogg файлы в один ogg_audio_path = self._merge_audio_n_to_1(files, out_filename=»test_n_1.ogg») # Удаляем временные файлы [os.remove(file) for file in files] if out_filename is None: return ogg_audio_path return self._rename_file(ogg_audio_path, out_filename)
Класс получился большим, т.к. пришлось бороться с ограничениями:
- До 1000 символов на входе модели
- Сохранение аудио только в виде файла с названием text.wav
- Не восприимчивость цифр, пришлось преобразовать их в текст
- Модель русского языка не говорит на английском
Модель русского языка не может озвучить английский текст, поэтому такой текст просто игнорируется. Пробовал делать транслитерацию (английские символы русскими буквами), но это звучит ужасно. Тут нужно делать перевод с английского на русский, либо озвучивать отдельно и потом склеивать результат или просто использовать модель, которая поддерживает 2 языка. В общем не присылайте слова на английском, они будут проигнорированы.
Основная магия происходит во внутреннем методе TTS._get_wav(), который принимает текст и необязательные параметры: голос спикера и качество выходного аудио. Модель создает аудио файл с именем text.wav и метод возвращает путь до него.
Для работы с классом TTS есть основные методы TTS.text_to_ogg() и TTS.text_to_wav(). Методы принимают текст любой длины и необязательный параметр имя выходного файла. Как раз в этих методах происходит преобразование цифр в текст, а также разбивка текста на строки до 990 символов. Сделал самое простое разбиение, но по-хорошему нужно делить по предложениям или словам, т.к. это влияет на конечный результат.
Отдельные строки по 990 символов озвучиваю моделью, а потом склеиваю через ffmpeg, что на выходе метода всегда возвращает 1 файл.
tts = TTS() print(tts.text_to_ogg(«Привет,Хабр! Тэст 1 2 три четыре», «test-1.ogg»))
TODO
В проекте еще многого чего можно улучшить, вот несколько моментов:
- Реализовать методы без сохранения файлов на диск
- Добавить перевод английских слов на русские
- Упаковать проект в докер-контейнер для развертывания на сервере
- Проверить ограничения по размеру сообщения и файла в Telegram
- Когда-нибудь написать тесты
Выводы
Возможно у меня не получилось с первого раза промышленное решение для крупных корпораций, но думаю такой пет-проект позволил мне попрактиковаться сразу в нескольких областях программирования:
- Продумать архитектуру проекта
- Написать своего Telegram бота
- Получить опыт на реальном проекте, который потом еще можно развивать
- Развить умение гуглить ошибки и читать документацию
В общем занимайтесь интересными вещами и получайте от этого удовольствие, даже если это нужно только вам.
Источник: habr.com
Как сделать из голосового сообщения аудиозапись: 6 способов


Сейчас многие пользуются мессенджерами. Поэтому актуален вопрос: как сделать из голосового сообщения аудиозапись?
Скачивание в ВК на телефоне, планшете
- Пересылаем боту «VOICELOAD» необходимое сообщение. Бот даёт нам ссылку, по которой вы скачиваете ГС.
- Старинный метод – сохранение аудиосообщения посредством записи через диктофон. Включаем средство записи на телефоне, и одновременно включаем сообщение. Получаем нужный аудиофайл. Но не факт, что качество звука будет хорошим. Для того чтобы устранить шумы в записи и улучшить её – используйте микрофон, например, микрофон-петличку.
Есть ещё вариант установить дополнительные приложения на телефон. Поработать над улучшением качества ГС в аудио редакторе, но это трудозатратно.
Скачивание из диалогов
В помощь – код страницы в ВК. Выберете нужное сообщение, щёлкните правой кнопкой мыши по любой части страницы. Находим строку в меню «Исследовать элемент». Она бывает под именем «Проверить», «Посмотреть код элемента». Либо есть вариант зайти в инспектор кода с помощью Ctrl+Shift+I.
Перед вами – окно. Нажимаем на кнопку со стрелкой (слева первая) и кликаем на изображение ГС. Кликаем левой кнопкой мыши по ссылке, содержащую текст: «data-ogg=»https://psv4.userapi.com…» и копируем.
Вставляем в адресную строку ссылку; переходим по этой ссылке. Перед вами – окно с ГС, которое вы имеете возможность и скачать, и прослушать . Нажимаем на три точки, а затем на пункт меню «Загрузить». И затем получаем файл в формате .ogg, конвертируемый с помощью программы в формат mp3.
Расширения
Есть вариант скачать с помощью расширения через плагины, например, VK Helper. Есть также сервис, например, SaveFrom.ru, где можно скачать не только видео и аудио в заявленной соцсети, но и в других, к примеру, в YouTube. Процесс установки указан на сайтах данных проектов.
Пересылка аудиосообщения боту ВК
Есть ещё способ. Нужны знания о кэше – временной памяти каждой программы. Из-за этого в специальной папке мы можем найти прослушанные нами сообщения в ВК. Подходят все браузеры, из известных: Google, FireFox, Explore, Opera, Yandex. На примере последнего разберём способ скачивания через кэш:
- Проходим путь: C:Users(Ваше имя пользователяAppDataLocalYandexYandexBrowserUser DataProfile (индивидуальный номер)Cache (Примечание: если профиля у вас нет, то необходимо зайти в папку Default).
- Делаем сортировку в таблице файлов согласно дате изменения.
- Нажмите на аудиозаписи кнопку «Пуск», чтобы ГС проигрывалось (до конца – необязательно).
- Появившийся в папке кэша сверху файл переименовываем и меняем расширение .mp
Запись через микрофон

Главное условие работоспособности метода – рабочий микрофон.
- Скачайте приложение для записи микрофона на ПК.
- Одновременно с записью воспроизводим голосовое сообщение.
Важен хороший микрофон, если хотите высокое качество аудиофайла. При плохом микрофоне будут лишние шумы.
Запись через диктофон онлайн
Это похоже на запись сообщения с диктофона телефона. Воспользуемся диктофоном с онлайн сервиса. Подготовьте микрофон.
- Выберете нужное ГС сообщение.
- Подключите звукозаписывающую аппаратуру.
- Затем выбираем сервер. online-voice-recorder.com, voice-recorder-online.com, vocalremover.org/ru/online-voice-recorder .
- Выберете нужные настройки.
- Одновременно включаем запись и ГС.
- Скачиваем файл.
- При необходимости конвертируем.
Выводы из статьи
В статье приведены простые и действенные методы записи голосовых из ВК. Это не значит, что не существует ещё методов записи.
Из приведённых выше методов простейшими являются запись через микрофон компьютера или телефона. Но не всегда получаются качественные мп3 файлы. Всё зависит от качества микрофона: дороговизны(дешевизны), технических характеристик, от помещения, где ведётся запись. Исключите посторонние шумы, создайте тишину в комнате.
После получения файла с сообщением поработайте при необходимости в аудиоредакторе с целью устранения лишних и мешающих звуков, например, в Audacity. Самый сложный, но качественный метод: скачивание через код в ВК. Позволяют получить высокое качество аудиозаписи методы скачивания через бота, через кэш и плагины VKHelper и SaveFrom.
- Как удалить расширение из гугл хром
- Как научиться программировать с нуля в домашних условиях
- Самозанятость плюсы и минусы: как оформить 2022 год
- Как уоррен баффет стал миллиардером: история успеха
Источник: myrabotanadomu.ru