При размещении рекламы некоторые площадки в настройках аудитории позволяют загрузить список конкретных людей, которые увидят рекламу. Для парсинга id по конкретным пабликам существуют специальные инструменты, но куда интереснее (и дешевле) сделать это собственноручно при помощи Python и VK API. Сегодня расскажем, как для рекламной кампании LEFTJOIN мы спарсили целевую аудиторию и загрузили её в рекламный кабинет.
В материале «Собираем данные по рекламным кампаниям ВКонтакте» подробно описан процесс получения токена пользователя для VK API
Парсинг пользователей
Для отправки запросов потребуется токен пользователя и список пабликов, чьих участников мы хотим получить. Мы собрали около 30 сообществ, посвящённых аналитике, BI-инструментам и Data Science.
import requests import time group_list = [‘datacampus’, ‘185023286’, ‘data_mining_in_action’, ‘223456’, ‘187222444’, ‘nta_ds_ai’, ‘business__intelligence’, ‘club1981711’, ‘datascience’, ‘ozonmasters’, ‘businessanalysts’, ‘datamining.team’, ‘club.shad’, ‘174278716’, ‘sqlex’, ‘sql_helper’, ‘odssib’, ‘sapbi’, ‘sql_learn’, ‘hsespbcareer’, ‘smartdata’, ‘pomoshch_s_spss’, ‘dwhexpert’, ‘k0d_ds’, ‘sql_ex_ru’, ‘datascience_ai’, ‘data_club’, ‘mashinnoe_obuchenie_ai_big_data’, ‘womeninbigdata’, ‘introstats’, ‘smartdata’, ‘data_mining_in_action’, ‘dlschool_mipt’] token = ‘ваш_токен’
Запрос на получение участников сообщества к API ВКонтакте вернёт максимум 1000 строк — для получения последующих тысяч потребуется смещать параметр offset на единицу. Но нужно знать, до какого момента это делать — поэтому опишем функцию, которая принимает id сообщества, получает информацию о числе участников сообщества и возвращает максимальное значение для offset — отношение числа участников к 1000, ведь мы можем получить ровно тысячу человек за раз.
Парсинг групп и пользователей Telegram, VKontakte, Twitter и других соц.сетей в одном видео
def get_offset(group_id): count = requests.get(‘https://api.vk.com/method/groups.getMembers’, params=< ‘access_token’:token, ‘v’:5.103, ‘group_id’: group_id, ‘sort’:’id_desc’, ‘offset’:0, ‘fields’:’last_seen’ >).json()[‘response’][‘count’] return count // 1000
Следующим этапом опишем функцию, которая принимает id сообщества, собирает в один список id всех подписчиков и возвращает его. Для этого отправляем запросы на получение 1000 человек, пока не кончается offset, вносим данные в список и возвращаем его. Проходя по каждому человеку дополнительно проверяем дату его последнего посещения социальной сети — если он не заходил с середины ноября, добавлять его не будем. Время указывается в формате unixtime.
def get_users(group_id): good_id_list = [] offset = 0 max_offset = get_offset(group_id) while offset < max_offset: response = requests.get(‘https://api.vk.com/method/groups.getMembers’, params=< ‘access_token’:token, ‘v’:5.103, ‘group_id’: group_id, ‘sort’:’id_desc’, ‘offset’:offset, ‘fields’:’last_seen’ >).json()[‘response’] offset += 1 for item in response[‘items’]: try: if item[‘last_seen’][‘time’] >= 1605571200: good_id_list.append(item[‘id’]) except Exception as E: continue return good_id_list
Теперь пройдём по всем сообществам из списка и для каждого соберём участников, а затем внесём их в общий список all_users. В конце переводим сначала список в множество, а затем опять в список, чтобы избавиться от возможных дубликатов: одни и те же люди могли быть участниками разных пабликов. Лишним не будет после каждого паблика приостановить работу программы на секунду, чтобы не столкнуться с ограничениями на число запросов.
Бот ВКонтакте на Python #1 | Парсинг ВКонтакте
all_users = [] for group in group_list: print(group) try: users = get_users(group) all_users.extend(users) time.sleep(1) except KeyError as E: print(group, E) continue all_users = list(set(all_users))
Последним шагом записываем каждого пользователя в файл с новой строки.
with open(‘users.txt’, ‘w’) as f: for item in all_users: f.write(«%sn» % item)
Аудитория в рекламном кабинете из файла
Переходим в свой рекламный кабинет ВКонтакте и заходим во вкладку «Ретаргетинг». Там будем кнопка «Создать аудиторию»:

После нажатия на неё откроется новое окно, где можно будет выбрать в качестве источника файл и указать название для аудитории:

После загрузки пройдёт несколько секунд и аудитория будет доступна. Первые минут 10 будет указано, что аудитория слишком мала: это не так и панель вскоре обновится, если в вашей аудитории действительно более 100 человек.

Итоги
Сравним среднюю стоимость привлечённого в наше сообщество участника в объявлении с автоматической настройкой аудитории и в объявлении, аудиторию для которого мы спарсили. В первом случае получаем среднюю стоимость в 52,4 рубля, а во втором — в 33,2 рубля. Подбор качественной аудитории при помощи методов парсинга данных из ВКонтакте помог снизить среднюю стоимость на 37%.
Для рекламной кампании мы подготовили такой пост (нажмите на картинку, чтобы перейти к нему):
Источник: leftjoin.ru
Анализируем группы ВКонтакте на python

Пишем парсер групп ВКонтакте, узнаем процент живых пользователей в группах и стоит ли размещать в них свою рекламу или сотрудничать с ними.
08 сентября 2022 (обновлено 08.03.2023) · На чтение: 5 мин Комментарии: 0
Просмотров статьи: 861
Предисловие
Доброго времени суток дорогой читатель. Недавно мы с командой при поддержке JetBrains разыграли 2 ключа на годовую лицензию Pycharm Professional в нашей официальной группе Вконтакте «Happy Python». Чтобы получить больший охват нашего розыгрыша, мы провели рекламную компанию через сторонние паблики.
Столкнулись с огромным количеством групп, где можно распространить свой розыгрыш но огромный минус всех их — это очень высокие цены.
По незнанию приобрели рекламу с очень слабым откликом. Группа в которой размещался наш пост, при численности участников в 200 000 человек, набрал около 2000 просмотров. Что нас конечно же расстроило.
Всё это меня навело на мысль, написать анализатор групп Вконтакте, то есть проверять сколько из участников действительно живы и активны, ведь именно они нам интересны, как целевая аудитория рекламной компании И решили мы изучить теорию как происходит анализ данных, какие сведения нам нужны и насколько сложно их получить. А по нашей ссылке вы можете изучить курс Анализ данных на Python по 40% скидке. Действительно стоящий материал, который сложно найти в открытом доступе. Рекомендуем.
Исходный код доступен на GitHub. Вопросы по коду задать в нашем Telegram чате.
Импорт используемых библиотек для работы с ВК
Начнем написание кода с импорта нужных нам библиотек. Установим requests командой pip install requests, все остальные библиотеки являются стандартными и идут с python из упаковки, нам остается их только импортировать.
from config import token — данный импорт из файла config.py расположенного в данной рабочей директории, это ваш токен, которые вы должны получить в Вконтакте, если конечно у вас его еще нет. Если будут трудности, пишите в нашу группу VK HappyPython или Telegram чат, Вам всегда помогут.
import requests import time from config import token import datetime
Получаем количество смещений по количеству подписчиков в целевой группе ВК
Теперь нам надо выявить количество смещений (offset) в группе. Это нам нужно для того, чтобы собрать всех пользователей группы, если их больше 1000, так как ВК, может выдать только по 1000 участников за раз.
def get_offset(group_id): «»»Выявляем параметр offset для групп, 1 смещение * 1000 id»»» params = r = requests.get(‘https://api.vk.com/method/groups.getMembers’, params=params) count = r.json()[‘response’][‘count’] print(f’Количество подписчиков: ‘) if count > 1000: return count // 1000 else: count = 1 return count
Получение данных об активности подписчиков ВК группы
Данная функция на входе принимает id группы (group_id) и дату (from_data) с которой вы хотите начать анализ группы. Функция выведет нам количество пользователей со скрытой датой (список users_can_closed_visit), активных подписчиков (список active_list) плюс процентное соотношение с общим количеством участников и не активных подписчиков (список un_active_list)
def get_users(group_id, from_data): «»»Получаем всех участников группы и фильтруем их»»» active_list = [] users_can_closed_visit = [] un_active_list = [] for offset in range(0, get_offset(group_id) + 1): params = users = requests.get(‘https://api.vk.com/method/groups.getMembers’, params=params).json()[‘response’] for user in users[‘items’]: # проверка последнего посещения, не ранее указанной даты from_data преобразованной в timestamp start_point_data = datetime.datetime.strptime(from_data, ‘%d.%m.%Y’).timestamp() try: if user[‘last_seen’][‘time’] >= start_point_data: active_list.append(user[‘id’]) else: un_active_list.append(user[‘id’]) except: users_can_closed_visit.append(user[‘id’]) print(f’Количество пользователей со скрытой датой: ‘) print(f»Активных подписчиков: (%)») print(f’Не активные подписчики: n’) return active_list
Основная функция парсера ВК
Функция принимает список групп, проходится по ним, выводя в терминал подробную информацию.
def parser(group_list): from_data = input(‘Введите дату, с которой хотите отслеживать активностьnв формате: дд.мм.гггг: ‘) # from_data = ‘20.08.2022’ all_active_users = [] print(f’Анализируем с n’) for group in group_list: print(f’Группа: ‘) try: users = get_users(group, from_data=from_data) all_active_users.extend(users) time.sleep(2) except Exception as ex: print(f’ — не предвиденная ошибка: n’) continue
Запуск парсера групп ВК
Пропишем конструкцию if name == ‘main‘. И вызовим нашу основную функцию, передав в нее список групп, которые мы хотим проанализировать. Для примера я взял свою группу (при желании вы можете внести в список любое количество групп, как в за комментированном примере ).
if __name__ == ‘__main__’: # вносим в список интересующие вас группы # group_list = [‘happython’, ‘python_forum’, ‘vk_python’, ‘pirsipy’] group_list = [‘happython’] parser(group_list)
После запуска кода, в терминале видим следующее (Рисунок 1):

Вводим дату с которой хотим проанализировать группу, я введу 20.08.2022, то есть буду выявлять тех, кто был онлайн за последние два месяца. Жмем enter и получаем результат (Рисунок 2):

И так, активность нашей группы на 20.09.2022 за последние два месяца составляет ~88%, что не может не радовать. ^_^.
Благодаря данному коду Вы можете отсортировать группы в которых стоит брать рекламу, а какие стоит обойти стороной, где раздутые не активные подписчики.
Подписывайтесь на Нас: Вконтакте и Telegram. А так же если Вас интересует Backend на Python рекомендую канал нашего партнера в Telegram Backend development
Источник: happypython.ru
Парсинг данных через api vk и google sheets api на python
Появилась потребность собирать статистику постов из группы в контакте и затем проанализировать реакции подписчиков на конкретные посты. Если переформулировать на выходе стоит задача с заданной периодичностью снимать показания статистики постов в вк и сохранять их.
Я не профессиональный программист и не претендую, поэтому решил сделать все довольно просто. При помощи api VK забирать посты из группы, собираю нужный мне датафрейм и записываю данные в гугл таблицу, так же через api.
Может быть это и не самое оптимальное решение,
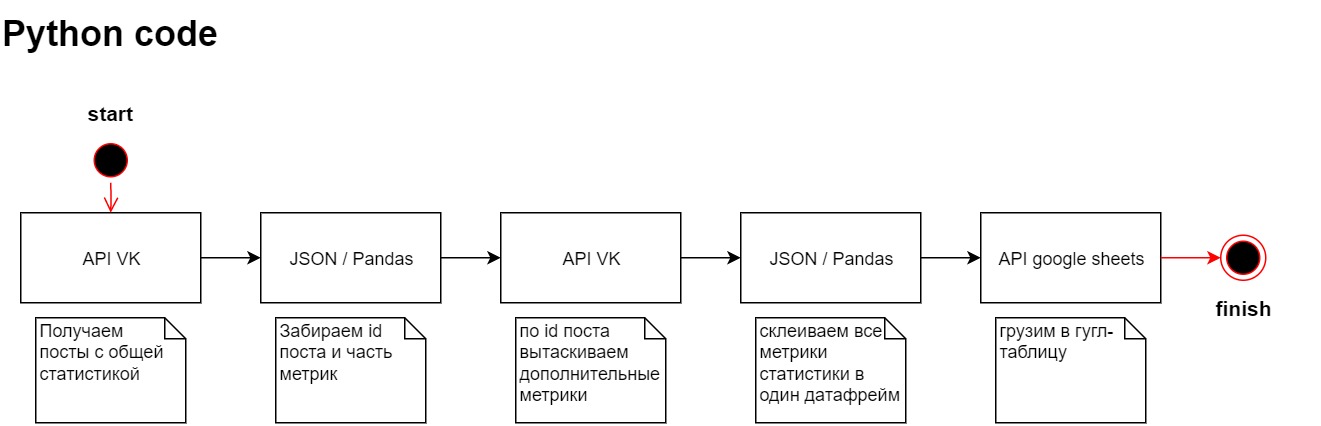
Настраиваем API VK
В этом блоке мы хотим собрать статистику постов из группы vk.
Для начала работы нам нужен user_token из vk. Мне понравилась видеоинструкция здесь, коротко и по делу.
Токен держим в секрете. Переходим в https://dev.vk.com изучаем документацию API.
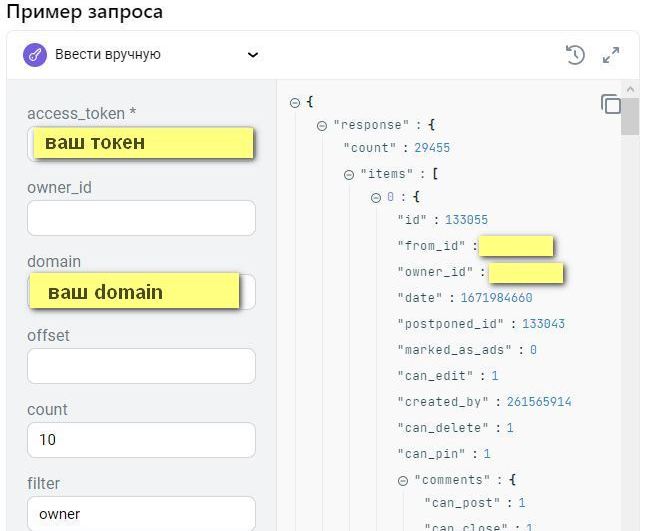
Прямо на сайте документации можем попробовать дернуть запрос.
Для этого нам нужно access_token, domain, count, v, filter.
access_token – получили на прошлом шаге. domain – название группы вы увидите в url название группы например https://vk.com/adminsclub. count – количество постов которые можем дернуть. v – версия api. filter – хотим получить только посты от группы устанавливаем owner.
Прописываем логику сбора
Импортируем библиотеку requests. Дергаем тестовый запрос. Поcле анализа структуры решаю, что мне нужен раздел items
# переменные TOKEN_USER = #ваш токен VERSION = #версися api vk DOMAIN = #ваш domain # через api vk вызываем статистику постов response = requests.get(‘https://api.vk.com/method/wall.get’, params=) data = response.json()[‘response’][‘items’]
Отдельное поле в статистики количество фотографий для поста, я не нашел.
Через цикл перебираем каждый пост и считаем количество фото, если фотографии нет скрипт ловит ошибку. Обрабатываем ошибку и ставим 0. Собираем новый список с полями id поста и количество фото.
Пишем обработчик. Вызываем pandas
# считаем сколько фото у поста, заводи все в df id = [] photo = [] for post in data: id.append(post[‘id’]) try: photo.append(len(post[‘attachments’])) except: photo.append(0) df_photo = pd.DataFrame( )
Переводим cловарь в df. Импортируем метод from pandas import json_normalize
Оставляем нужные атрибуты и переводим дату в другой формат.
В переменной post_id запихиваем id наших постов.
Я бы хотел обогатить свою статистику более расширенными измерениями
Из документации по api о которой рассказывал выше подобрал метод status.getPostReach
В методе обнаружил новый аргумент owner_id, его можно найти в настройках группы.
Делаем еще один запрос и новые данные сохраняем в датафрейм df_stat_post
# вытаскиваем нужные нам столбцы и переводим формат даты df = json_normalize(data) df = df[[‘id’,’date’,’comments.count’,’likes.count’,’reposts.count’,’reposts.wall_count’,’reposts.mail_count’,’views.count’,’text’]] df[‘date’]= [datetime.fromtimestamp(df[‘date’][i]) for i in range(len(df[‘date’]))] # для каждого поста вытаскиваем дополнительную статистику post_id = ‘,’.join(df[‘id’].astype(«str»)) response = requests.get(‘https://api.vk.com/method/stats.getPostReach’, params=) data = response.json()[‘response’] df_stat_post = json_normalize(data)
Теперь приступим к сборке объединяем все наши датафреймы, накидываем дополнительные метрики.
Далее наши данные преобразовываем для загрузки в гугл таблицу.
# объединяем все df cо всеми статистиками и количествам фото df_final = df.merge(df_stat_post, how=’left’, left_on=’id’, right_on=»post_id») df_final = df_final.merge(df_photo, how=’left’, left_on=’id’, right_on=»id») df_final.drop(columns=’post_id’,inplace=True) # добавляем дополнительные столбцы с временем df_final[‘date_time_report’] = datetime.now() df_final[‘date_report’] = date.today() df_final[‘year’] = df_final[‘date_time_report’].dt.year df_final[‘month’] = df_final[‘date_time_report’].dt.month df_final[‘day’] = df_final[‘date_time_report’].dt.day df_final[‘hour’] = df_final[‘date_time_report’].dt.hour df_final[‘minute’] = df_final[‘date_time_report’].dt.minute df_final[[‘date’,’date_report’,’date_time_report’]] = df_final[[‘date’,’date_report’,’date_time_report’]].astype(‘str’) # сохраняем все значения data_list = df_final.values.tolist()
Грузим в google sheet через api
Есть готовые библиотеки для работы с google sheet например pygsheets, но мне было важно поработать с API поэтому легких путей не искал.
Прежде чем загрузить надо настроить наш api прекрасная статья, в который пошагово написано и даст возможность поиграться с листами https://habr.com/ru/post/483302/
# подключаемся к гугл таблице CREDENTIALS_FILE = # Имя файла с закрытым ключом, вы должны подставить свое # Читаем ключи из файла credentials = ServiceAccountCredentials.from_json_keyfile_name(CREDENTIALS_FILE, [‘https://www.googleapis.com/auth/spreadsheets’, ‘https://www.googleapis.com/auth/drive’]) httpAuth = credentials.authorize(httplib2.Http()) # Авторизуемся в системе service = apiclient.discovery.build(‘sheets’, ‘v4’, http = httpAuth) # Выбираем работу с таблицами и 4 версию API spreadsheetId = # ваш id лист
После подключения к листу. Находим последнюю заполненную строку.
В моем примере я заполняю последние 10 строк ровно по количеству постов которые я получил из get запроса. Подготавливаем шаблон для запроса, заполняем шаблон данными какие ячейки заполняем и заполняем. Далее выполняем запрос. Готово
# находим последнию строку заполненную response = service.spreadsheets().values().get(spreadsheetId = spreadsheetId,range=»Лист номер один!A1:A»).execute() # последние 10 строк заполняем number_sheet = «Лист номер один!A» + str(len(response[‘values’])+1) + ‘:AA’ + str(len(response[‘values’])+10) # создаем запрос и вставляем туда данные data_vk = < «valueInputOption»: «USER_ENTERED», # Данные воспринимаются, как вводимые пользователем (считается значение формул) «data»: [ ] > data_vk[‘data’][0][‘range’] = number_sheet data_vk[‘data’][0][‘values’] = data_list # выполняем запрос results = service.spreadsheets().values().batchUpdate(spreadsheetId = spreadsheetId, body = data_vk).execute()
Заключение
После написания этого кода мне требовалось запускать его каждый час и принял решение арендовать сервер, установить туда docker и через crontab запускать.
Источник: habr.com