
![]()

Перед созданием аудитории lal, советуем почитать о том, что такое похожие аудитории.
Прочитали? Отлично! Тогда попробуем создать похожую аудиторию в ВКонтакте.
Чтобы создать похожую аудиторию, нам нужна соответствующая вкладка в рекламном кабинете во вкладке “Ретаргетинг”.
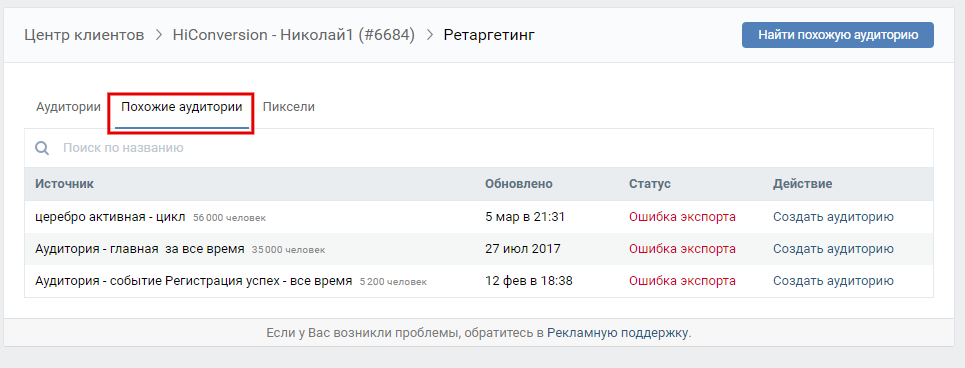
Жмем на кнопку “Найти похожую аудиторию” и перед нами появляется попап.
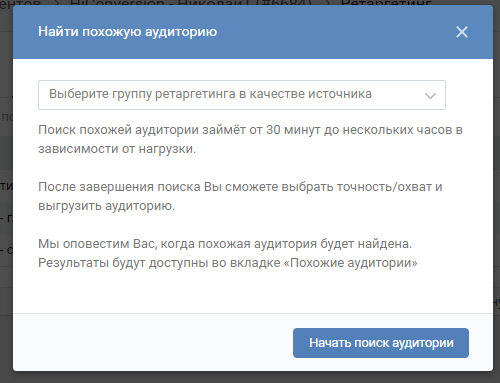
Необходимо выбрать группу ретаргетинга, загруженную ранее, на основе которой будет собираться похожая аудитория.
АУДИТОРИИ ВКОНТАКТЕ: КАК ИХ СОЗДАВАТЬ, КАКИЕ ОНИ БЫВАЮТ И КАК ИСПОЛЬЗОВАТЬ В РЕКЛАМНЫХ КАМПАНИЯХ
После того как статус сбора аудитории будет “Выполнен”, у вас появится кнопка “Создать аудиторию”. Она нам и нужна.
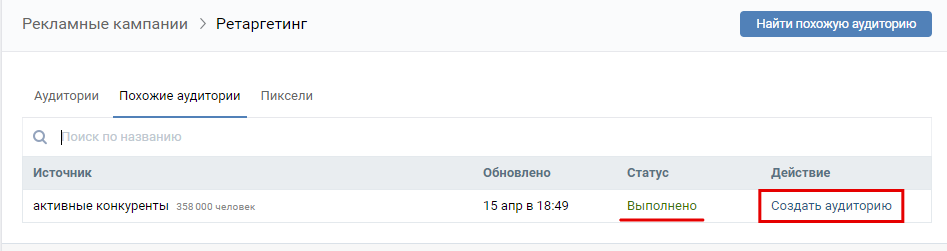
При нажатии на нее нам появляется попап, в котором необходимо выбрать степень схожести аудитории с источником.
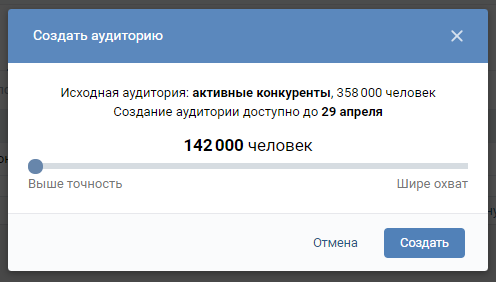
Чем выше точность, тем меньше аудитории будет в базе и тем больше будет степень схожести с источником. К примеру, при высокой точности ВК будет подбирать аудиторию, которая потребляет тот же контент в соцсетях, что и пользователи из источника. При широком охвате, схожесть может быть только в населенном пункте или возрасте источника и похожей аудитории, поэтому и аудитории в готовой базе будет больше.
Выбор точность или охват зависит от рекламодателя. После того как вы определили степень схожести, жмите “Создать”.
Все. Теперь в списке ваших аудиторий появилась похожая аудитория, вы можете создать на нее рекламное объявление и протестировать эффективность.
Источник: hiconversion.ru
Look-alike аудитория
Look-alike аудитория (LAL) — это пользователи, которые похожи на выбранную рекламодателем аудиторию.
Алгоритмы рекламных сетей анализируют исходные данные по возрасту, интересам, паттернам поведения и другим критериям. По результатам анализа подбираются люди, которые максимально похожи на исходный список. На собранную таким образом аудиторию таргетируют рекламу.
Настроить сбор look-alike аудиторий можно во всех популярных рекламных и социальных сетях: рекламной сети «Яндекса», «ВКонтакте», MyTarget, Google Ads.
Настройка похожих аудиторий LOOK-ALIKE (LAL) в ВК, Facebook, Instagram, myTarget и PromoPult
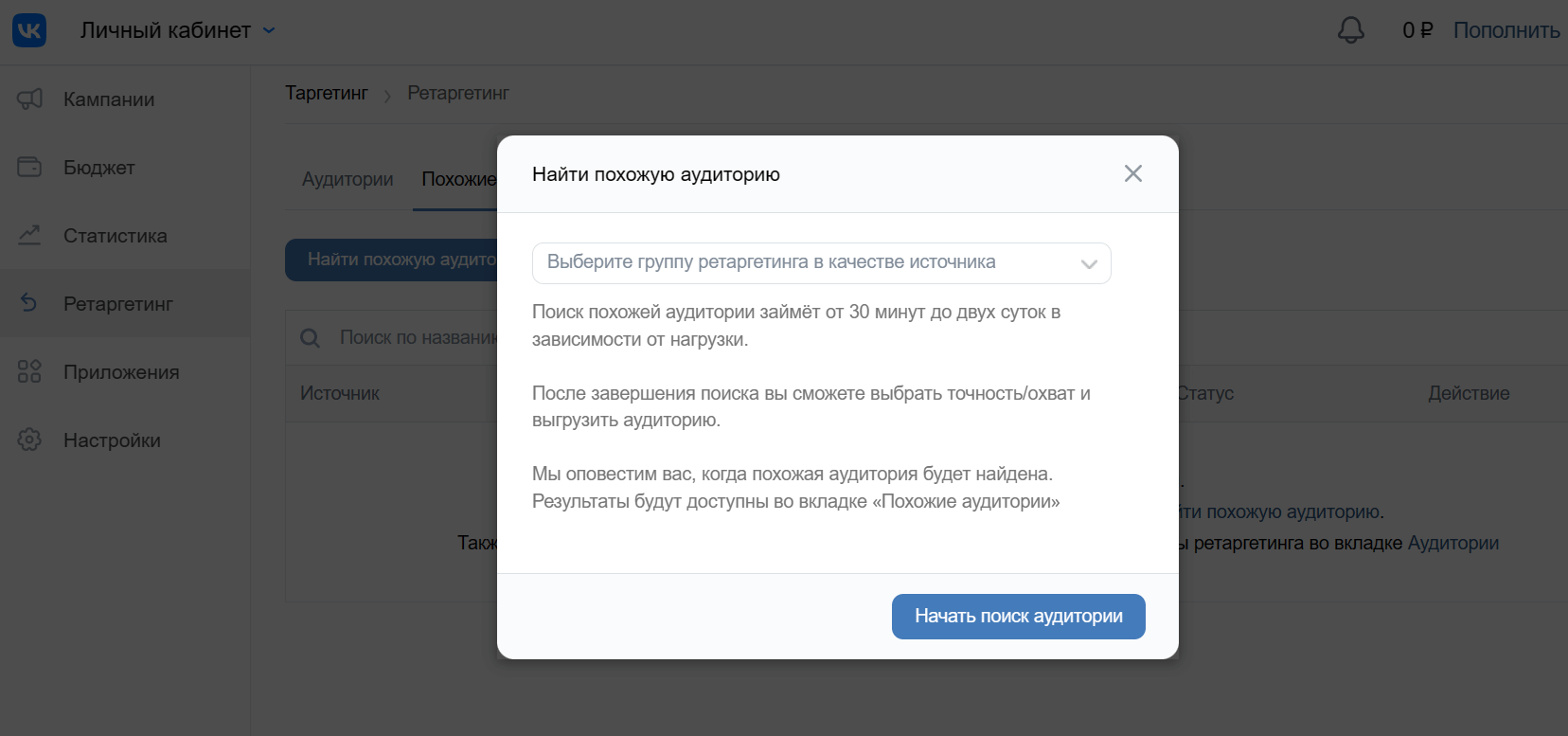
Поиск LAL в рекламном кабинете VK
Зачем использовать LAL
Привлечь новых клиентов . LAL-технология может найти пользователей, которые похожи на существующих покупателей. Это помогает компаниям расширять охваты и находить тех, кого с большой вероятностью заинтересуют их предложения.
Например, владелец интернет-магазина музыкальных товаров заметил, что посетители почти не покупают наушники. С помощью LAL-технологии он может загрузить в рекламный кабинет данные о тех, кто уже покупал в его магазине именно этот товар. Алгоритмы системы проанализируют информацию о прежних клиентах и найдут максимально похожих на них пользователей. Тогда продавец сможет показывать рекламу тем, кого с большей вероятностью заинтересуют именно наушники.
Улучшить таргетинг . Когда алгоритмы анализируют исходный список, они выделяют в нем частые паттерны. Это помогает собрать более глубокую информацию о клиентах, чтобы реклама стала прицельнее.
Допустим, тот же продавец музыкальных товаров знает, что его аудитория — это чаще всего москвичи 30–40 лет. Самостоятельно он настраивает таргет, используя только эти характеристики. LAL помогает найти более глубокие связи среди пользователей исходной аудитории. Например, многие покупатели магазина интересуются благотворительностью и долго сидят в интернете после 22:00. Теперь рекламу будут показывать не всем москвичам среднего возраста, а в первую очередь тем, кто сидит на благотворительных сайтах поздним вечером.
Система не покажет, какие общие черты она выделила в исходном списке, но учтет найденные паттерны и улучшит таргетинг.
Повысить конверсию . Более прицельная реклама позволяет находить более релевантную аудиторию, а значит увеличить вероятность целевого действия.
Основные характеристики для сбора LAL
Для сбора look-alike рекламная система сравнивает пользователей по ряду признаков. Основные из них для любой рекламной платформы:
- Пол . Система подбирает новую аудиторию с тем же соотношением мужчин и женщин, что и в исходном списке.
- Возраст . В список LAL войдут пользователи того же возраста, что и люди из загруженной базы.
- Регион . Алгоритмы ищут пользователей, проживающих в регионе выбранной аудитории.
- Интересы . В процессе подбора ищутся пользователи, поведение и интересы которых схожи с паттернами, найденными в изначальном списке.
- События из рекламных кампаний . Система ищет людей, похожих на пользователей, которые реагировали на рекламные кампании бизнеса.
Это только базовые параметры для каждой платформы. Алгоритмы рекламных систем учитывают несколько десятков, а иногда и сотен характеристик. К примеру, «Рекламная сеть Яндекса» учитывает используемые в запросах слова, посещаемые сайты, время выхода в интернет. Кроме того, можно задать собственные условия подбора LAL.

В Яндекс.Директ можно создать собственное условие подбора LAL. Источник
Из какой аудитории создают look-alike
Для формирования похожих аудиторий используют:
- базу клиентов из CRM;
- подписчиков бизнес-страницы в соцсетях;
- людей, участвовавшие в проектах компании;
- посетителей ресурса, собранных с помощью пикселей;
- списки ремаркетинга;
- подписчиков страниц и сообществ конкурентов.
В настройках рекламной платформы обычно можно выбрать конкретный источник данных для поиска LAL. Например, на myTarget можно создавать сегменты из подписчиков групп во «ВКонтакте» и «Одноклассниках».
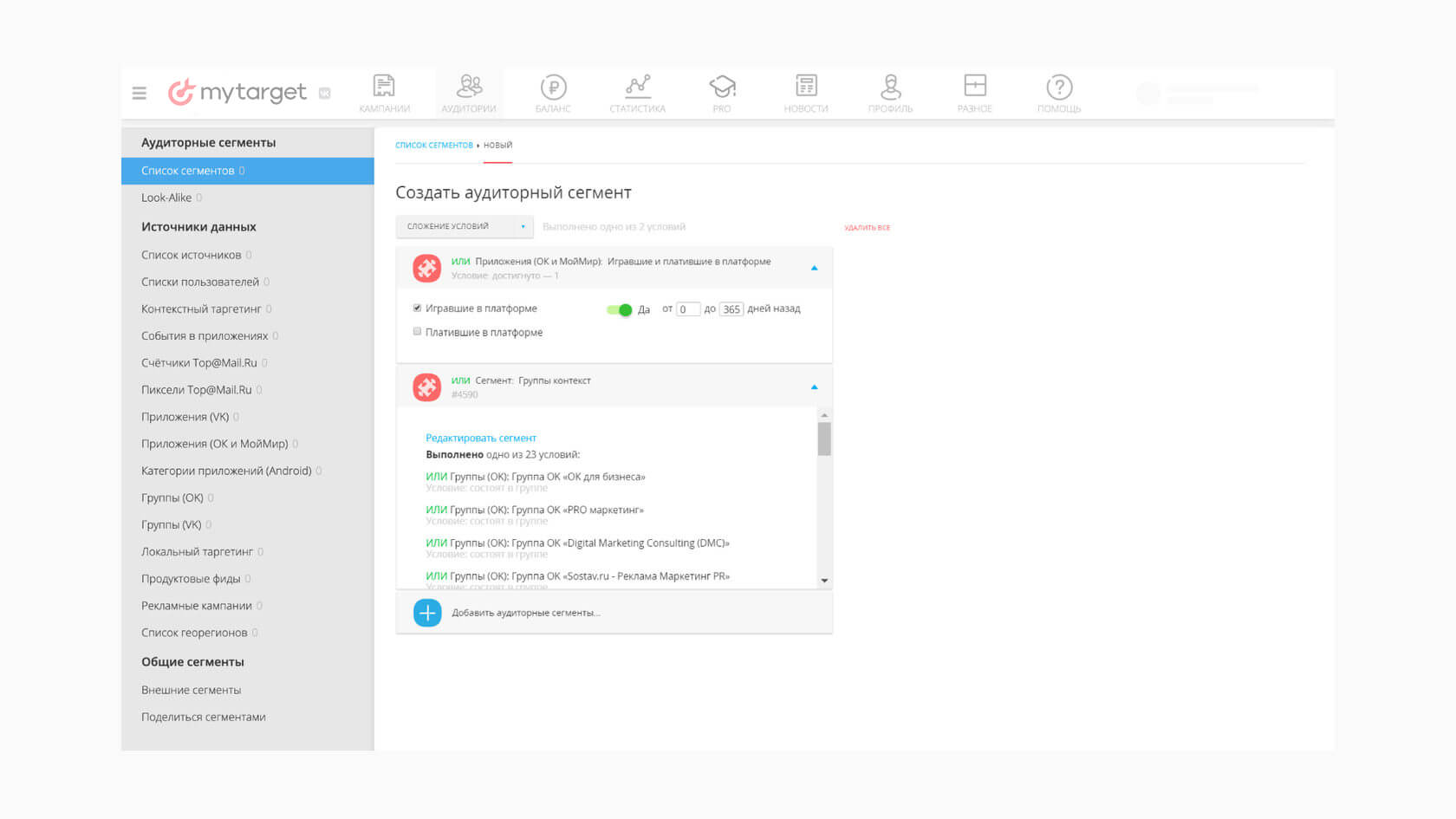
Создание аудиторных сегментов в myTarget. Источник
Зачем и как сегментировать исходную аудиторию
Если создать список из всех имеющихся исходных аудиторий, результат получится средним: характеристики LAL будут слишком общими. Для более точного подбора базу сегментируют по какому-то признаку, например по этапам воронки продаж. В первую группу можно выделить недавно зарегистрировавшихся на сайте пользователей, во вторую — уже интересовавшихся товаром, а в третью — клиентов, которые уже совершали покупки.
Параметры могут быть любыми. Например, для клиентов интернет-магазина сегментацию можно выстроить по среднему чеку: до 10 000 рублей и более 10 000 рублей.
Чтобы разделить аудитории, можно использовать пиксели . Они позволяют отслеживать действия посетителей на сайте. Благодаря этому пользователей можно сегментировать в зависимости от совершаемых ими действий. К примеру, первая группа — впервые зашли на сайт, вторая — просмотрели конкретный раздел, третья — подписались на email-рассылку или сделали заказ.
Как работает look-alike аудитория
Вот как работает LAL-технология:
- Рекламодатель загружает в систему базу пользователей. Важно убедиться, что исходные данные — качественные. Если неправильно собрать целевую аудиторию , можно слить бюджет впустую.
- Алгоритмы выявляют признаки, объединяющие пользователей из списка.
- Система сравнивает всех посетителей какого-либо ресурса с паттернами, обнаруженными в исходной базе. Например, LAL-технология в рекламном кабинете VK, найдет похожую аудиторию среди пользователей этой социальной сети.
- Все найденные похожие пользователи входят в список look-alike. Система обновляет подобранную аудиторию раз в несколько дней, если она используется в активных рекламных компаниях.
В исходном списке должно быть не меньше 1 000 пользователей, иначе система может выдать ошибку: слишком мало информации, чтобы алгоритм распознал паттерны. Собрать качественную LAL поможет база, содержащая от 10 000 до 50 000 уникальных пользователей.
Созданный список LAL может содержать несколько миллионов человек. Поэтому для рекламных целей объем можно сократить. Для этого в разделе настроек уменьшают расширение аудитории до нужного значения.
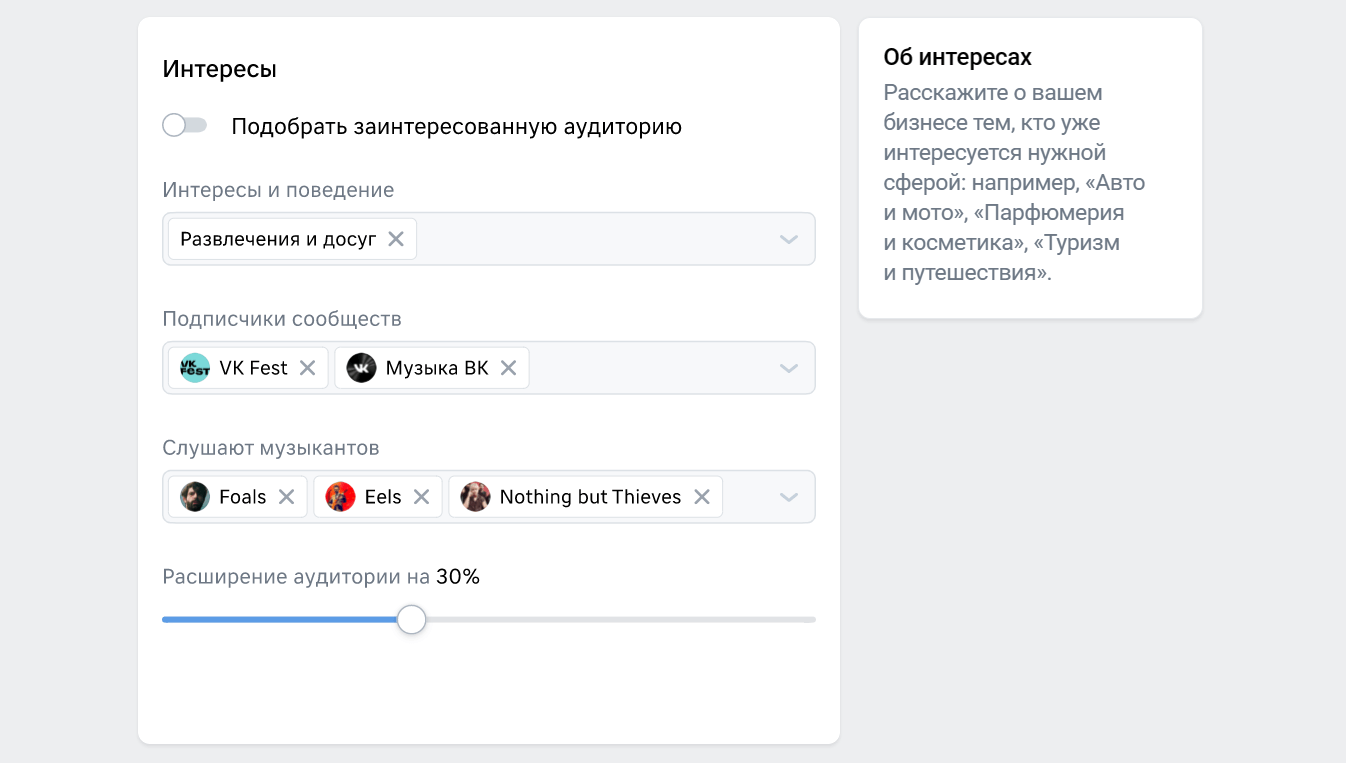
Настройки подбора LAL в рекламном кабинете VK
Создание похожей аудитории в среднем занимает от 6 до 24 часов, но может длиться и несколько дней. После сбора первого списка каждые 3–7 дней запускается его обновление.
Алгоритмы LAL выбирают пользователей, которые максимально схожи с изначальным списком. Но с течением времени система расширяет новую базу и она становится всё меньше похожа на исходную аудиторию — идеальные совпадения заканчиваются. Из-за этого падает конверсия. Поэтому важно регулярно загружать новые списки. Эффективность рекламных кампаний не снизится, если дополнять данные каждые 1–3 месяца.
Стратегии работы с look-alike аудиториями
В зависимости от задачи, выбирают разные исходные источники и по-разному их сегментируют.
- Расширить охват и привлечь трафик — look-alike создают на основе данных обо всех посетителях ресурса компании или её конкурентов.
- Собрать заинтересованных людей — составляют базу из тех, кто интересовался компанией, но не стал ее клиентом. Например, из посетителей сайта, которые положили товары в корзину, но не оплатили.
- Найти новых клиентов — исходный список формируют из пользователей, действия которых уже влияли на повышение конверсии. Например, только из реальных покупателей.
- Выровнять спрос — изначальную аудиторию создают из тех, кто взаимодействовал с конкретным разделом сайта или, например, интересовался определенным продуктом.
Источник: www.unisender.com
Look-a-like. Как это работает на стороне площадки и чем полезно бизнесу
Фразе Гиппократа «Ты — то, что ты ешь» уже более тысячи лет. И в 21 веке очевидно, что она относится не только к еде, но и к потребляемому контенту. Это давно доказано различными исследованиями и активно используется бизнесом: анализ историй посещённых веб-сайтов позволяет извлечь как базовые знания о человеке (пол, возраст, уровень зарплаты и т.д.), так и более специфичные вещи, например, интересы человека или факт наличия определённой вещи, будь то кроссовки фирмы Nike или дорогого автомобиля.

В этой статье мы расскажем, как корпорации используют ваши истории браузеров для объединения людей по интересам, причём здесь таргетированная реклама и как эту задачу решают разработчики компании Amberdata. Если более конкретно — поговорим с вами о задаче Look-A-Like.
Что такое LAL
Сперва разберемся, что такое Look-A-Like моделирование и зачем это вообще нужно бизнесу.
Допустим, есть банк, который хочет прорекламировать свои новые условия кредитования, причём нацелены эти условия преимущественно на людей с высоким доходом. Цель такой рекламы — выдать как можно больше новых кредитов. При этом банк хочет показывать рекламу только тем людям, которые с наибольшей вероятностью совершат указанное целевое действие. Поэтому банк обращается в компанию Amberdata с просьбой подобрать выборку людей, которая будет лучше всего отвечать его целям и запросам.
Поставленную задачу можно решить двумя способами.
Первый — подобрать для банка аудиторию, которая одновременно интересуется, например, дорогими автомобилями, часто ездит между Москвой и Петербургом, передвигаясь при этом исключительно в бизнес-классе сапсанов и, главное, за последний месяц хотя бы три раза заходила на сайты банков и искала их ставки и условия по кредитам. Итого получаем набор людей, которые (по нашему мнению) зарабатывают много денег и планируют крупную покупку в ближайшее время.
Вариант вполне рабочий, но только в случае, если заказчик хорошо разбирается в своей целевой аудитории, а главное — знает, для какой группы людей создан их продукт.
Второй способ предполагает, что банк уже показывал подобную (а может, и ту же самую) рекламу в интернете и знает, кто из этой выборки людей таки совершил целевое действие и взял рекламируемый кредит. Тогда нет смысла угадывать характеристики и интересы ЦА, так как на руках у нас есть целая выборка людей, которые как раз интересуют банк — пусть в их характеристиках разбирается компьютер!
В таком случае мы просто берём выборку клиентов от банка (разметим такие данные как 1, теперь это для нас «позитивное событие» — именно таких людей мы и ищем), с нашей стороны — берём выборку людей, которые точно не похожи на целевую аудиторию рекламы (способов выбрать такую выборку «непохожих» людей множество, но обсудим это в других статьях, а пока — размечаем такие данные как 0, то есть «негативное событие»: люди не похожи на тех, кого мы ищем).
Далее — обучаем нейросеть, которая учится отделять «искомых» людей от «остальных», применяем обученную модель на всех пользователей, которые есть у нас в доступе. В итоге получается, что для каждого пользователя, о котором у нас хранятся данные, мы с помощью нейросети оценили вероятность его схожести по своим характеристикам с людьми из банковской выборки, и, следовательно, вероятность того, что каждый конкретный пользователь возьмёт кредит после просмотренной рекламы. Вуаля!
А теперь чуть более формально.
Цель LAL-моделей — поиск аудитории, максимально похожей на целевое множество пользователей. Либо у заказчика это множество уже есть, с заранее определенными признаками, и он просит найти похожих людей среди множества наших данных. Либо такого набора у заказчика нет, но он знает, какая аудитория ему нужна. Тогда (если мы, конечно, охватываем подобную аудиторию) мы можем обучить LAL-модель и найти похожих людей из оставшегося множества данных.
Как работает LAL-сегментация
Данные и их предобработка
Основное топливо для нашей работы — данные о посещённых пользователями веб-сайтов, которые собираются с помощью установленных на сайтах пикселей. Базово пиксель —это код, который добавляется на сайт (по обоюдному согласию владельца сайта и нашей компании). Он срабатывает при заходе каждого пользователя и записывает:
- куку пользователя;
- User-Agent его устройства;
- время захода на сайт.
Всё это группируется по кукам, сортируется по времени, и в итоге получаем «мини историю браузера» — когда, с какого устройства и на какие сайты заходил пользователь. Последовательность посещённых сайтов и есть основной источник данных о пользователе и называется его кликстримом (от англ. clickstream — «поток кликов»). По сути, для каждого пользователя мы имеем список доменов, написанных через пробел.
Со стороны может показаться, что этого мало, но по таким данным можно многое понять о человеке.
Краткий обзор данных
В сыром виде домены выглядят следующим образом: https://www.example.com/. Их нужно «почистить» — удаляем всё лишнее, остаётся www.example.com. Далее нам нужно избавиться от «мусорных» доменов — под этим термином мы понимаем те сайты, которые не несут никакой смысловой нагрузки, сбивая наши модели с толку. Чаще всего это ссылки на поисковики (например, google.ru), рекламные сайты, которые открываются одновременно с тем, как мы открываем новую статью на новостном сайте, либо просто домены, которые не работают.
Также отдельной нейросетью мы удаляем те строки данных, которые похожи на работу ботов — это полезно как для обучения LAL-модели, так и для заказчика, он не будет тратить лишние деньги на показ рекламы куску кода 🙂 Реклама-то покажется, но этот кусок кода вряд ли купит рекламируемый товар.
Финальная стадия очистки данных —фильтрация по длине историй пользователей. Так, из примерно 60 млн. кук в нашей выборке мы убираем 15 млн. историй, в которых указано меньше 3 доменов — такие короткие кликстримы несут в себе мало информации, тем самым «засоряя» нашу модель.
В конечном итоге у нас остаются истории посещённых доменов, где:
- минимальная длина истории — 3 домена;
- максимальная длина истории — 2487 доменов;
- средняя длина истории — 10 доменов;
- общий объем выборки — около 45 млн кук.
Получившаяся выборка готова для подачи в модель и выглядит следующим образом:
| viuserid| history|count_uniq|count| first_ts|
|sE1xfJbXGgQVcDR7kgrc|deti.mail.ru news. | 4|
|NrQeI3dyNfFj4ov7F-m4|sunhome.ru kp.ru . | 8|
|T6QjnNvI64T4nFO7V35p|ssp.rambler.ru la. | 14|
Разделение выборки negative/positive
Так как модель должна научиться отделять пользователей целевой группы от «других», то генеральная совокупность разделяется на выборки positive и negative. Как было упомянуто ранее, выбор «негативных» примеров разнообразен и не очевиден, поэтому оставим это на обсуждение в будущих статьях и перейдём к следующему важному пункту работы — векторизации данных.
Векторизация данных для обучения модели
Как известно, модели не могут работать со строками, на вход им нужно подавать числа. Для векторизации мы используем предобученную модель Word2Vec, которая обучалась на всем имеющимся у нас кликстриме. В итоге обученная модель Word2Vec сопоставляет каждому домену свой уникальный числовой вектор размерности 300, в котором отражается «смысл» этого домена, а именно — тип сайта и вид контента, который он предоставляет.
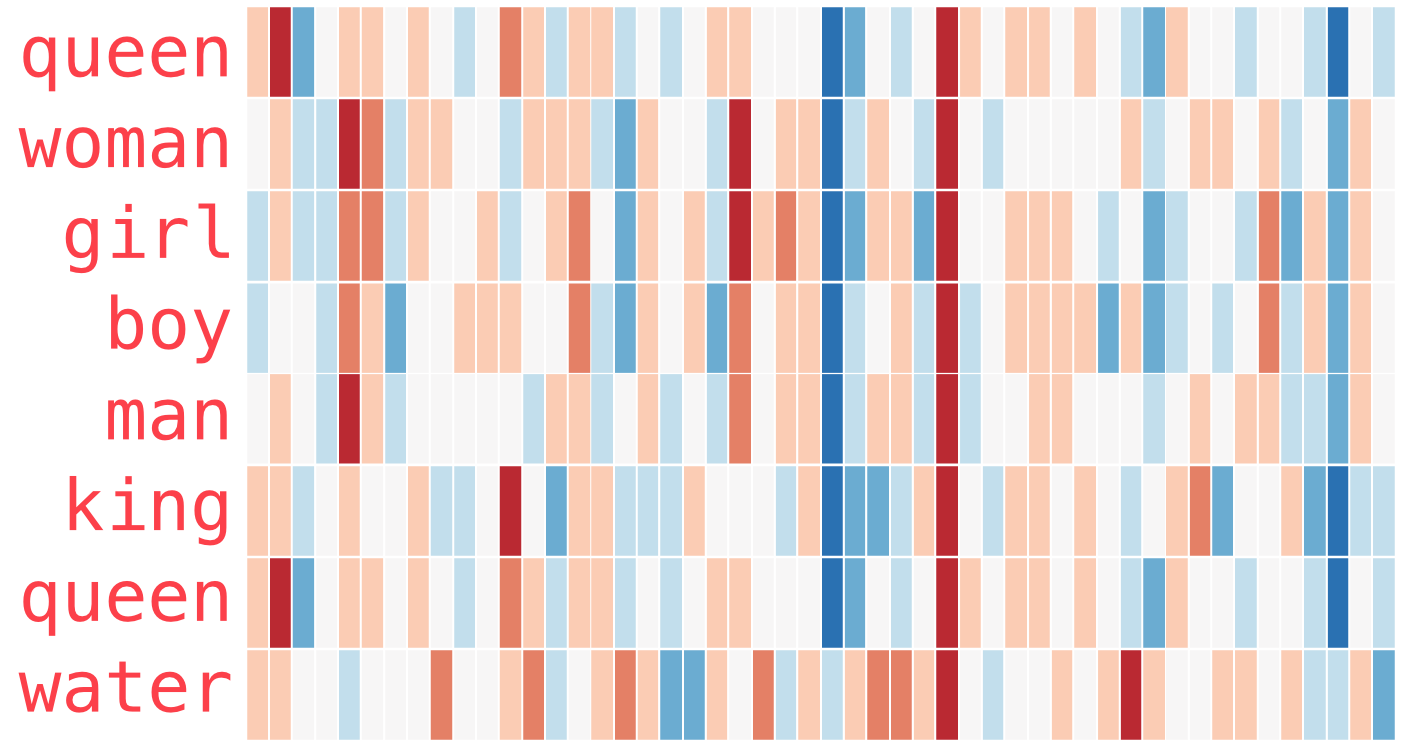
Один из примеров визуального представление word2vec
По полученным векторным представлениям можно кластеризовать сайты — на двумерном графике будут осмысленные кластеры доменов, объединённых по смыслу в группы.
Для перевода целой истории пользователя в векторное пространство мы получаем вектор каждого домена и усредняем их. Затем к полученным векторам добавляются дополнительные признаки User Agent и формируется окончательный датасет.
Модель
В качестве модели используется рекуррентная двунаправленная нейронная сеть. В дополнение к скрытым рекуррентным слоям используются также и сверточные слои и пулинги. Сверточные слои решают две важные задачи в нашей сети:
- уменьшают количество параметров, необходимых для обучения;
- помогают извлекать из полученных признаков низкоуровневую информацию, как это делают сверточные сети в решении задач компьютерного зрения.
Метрики
Для оценки качества работы нашей LAL-модели мы используем одну основную метрику и несколько второстепенных, которые дополняют общую картину.
Основной метрикой является lift_score, которая показывает, во сколько раз получаемая модель лучше той, чтобы предсказывала бы метки случайным образом lift = …..
В среднем модель выдает следующие метрики:
- f1: 0.93
- acc: 0.93
- auc: 0.98
- lift_score: 1.8
Компоненты сервиса
Описанное выше важно для разработчиков и аналитиков Amberdata, однако менеджерам, которые принимают заказы по LAL-сегментированию и отдают заказчикам отскоренные моделью аудитории, важно наличие простого процесса постановки задачи разработчикам и удобное получение результатов.
А ещё хорошо бы не дёргать программистов каждый раз, когда приходит новый заказ на LAL-моделирование и не тратить их время на решение однотипных задач.
Мы учли желания обеих сторон и разработали свой Look-A-Like сервис.
- UI-интерфейс — необходим для комфортной постановки задачи: выбираются целевые категории, желаемый объем финальной аудитории и фильтры для данных.
- Менеджер задач — контролирует выполнение поставленных задач и выделение ресурсов для очередного этапа подготовки данных или обучения. В его обязанности также входит обеспечение связи между API и скриптами подготовки данных и обучения модели, оповещение о наличии критических ошибок и перезапуске сервиса в случае его поломки.
- База данных, где записываются все логи о ходе выполнения LAL-задач. С помощью неё менеджер задач следит за выполнением этапов построение LAL-сегментов.
- Скрипты подготовки данных, обучения модели и сохранения результата.
- API — координация всех частей сервиса.
Как все это работает в целом.
1. Менеджер заводит задачу, где указывает:
- на основе каких данных построить LAL;
- необходимый объем отскоренных данных;
- фильтры для данных и т.д.
2. В нашей внутренней БД появляется запись о новой задаче с меткой «LAL готов к построению» и остальной дополнительной информацией.
3. Наша API раз в какое-то время проверяет внутреннюю БД на наличие LAL, готовых к построению, и заносит информацию о них в БД сервиса.
4. Менеджер задач проверяет:
- сколько LAL готовы к построению;
- для скольких уже готовятся данные;
- сколько готовы к обучению;
- сколько уже обучаются;
- имеются ли LAL, готовые к сохранению;
- состояние сервиса: нужно ли его перезапустить или отправить уведомление об ошибке.
На основе этих данных менеджер определяет, сколько ресурсов возможно выделить для сбора данных, подготовки данных и обучения данных и возможно ли их выделить в данный момент. В итоге менеджер легко ставит новую задачу, разработчики минимально вовлечены в процесс, а заказчик получает искомую аудиторию — все довольны.
Мы постарались понятно объяснять, что такое Look-A-Like, зачем это нужно и как мы решаем поставленную задачу. Надеемся, вам было интересно — как тем, кто до прочтения не знал о существовании LAL, так и тем, кто пользуется этим на ежедневной основе, в том числе и разработчикам.
Источник: habr.com