Любой канал можно спарсить прямо из телеграма , сделав выгрузку, выгружаются все файлы и сообщения.
Нужно сделать то же самое на питоне: чтобы выгружался весь канал — сообщения и все файлы, по завершению скачивания скрипт завершал работу, но запоминал на каком сообщении остановился, чтобы при следующем запуске парсинг продолжался с места последней его остановки(последнего полученного сообщения или файла)
если на канале есть кнопки или какие-то другие элементы — их тоже нужно скачивать, например вот такие кнопки. в них есть ссылки https://s.mail.ru/k6pZ/kfKmELAYB , а вот ссылка на такой канал.
То есть скачивать нужно ВЕСЬ контент.
Каналов будет несколько , они будут периодически удаляться или добавляться.
файлы можно скачивать с таким же названием как они названы на канале, только если названия будут попадаться одинаковые они не должны перезаписывать друг друга, сообщениям? Сообщения и другой контент можно записывать отдельными файлами или валить всю информацию в один файл.
Парсинг каналов телеграм с помощью @telecobra4bot
Все это в дальнейшем будет обрабатываться парсером, но это уже другие задачи.
Источник: www.weblancer.net
Парсер участников групп Telegram

Dark Store Market
Инструкция по установке
1. Заходим на официальный сайт питона и выбираем версию 3.9.9 (скачать)
Выбираем файл — Windows installer (64-bit)
Скачиваем, устанавливаем. При установке, обязательно поставьте галочку на «Add Python to path»
Убедитесь, что у вас отсутствуют другие версии питона
2.Скачиваем и распаковываем архив
Открываем файл config.ini
Получаем данные API от вашего аккаунта:
Переходите на сайт: https://my.telegram.org
Вводите номер, к которому привязан аккаунт. После чего вводите код подтверждения, который пришел вам на аккаунт
Откроется меню для управления аккаунтом

Выбираем API development tools
В первой строке пишите: telegram, а второй любое слово на латинице, после чего нажимайте на «Create application»

В итоге, вы получите свои данные API
Нам нужны только
● API_id:
● API_hash:

Полученные данные вписываем в файл config.ini
● Данные API от вашего аккаунта
- api_id =
- api_hash =
● Номер телефона от вашего аккаунта

Парсинг групп и пользователей Telegram, VKontakte, Twitter и других соц.сетей в одном видео
- phone =
3. Открываем командную строку(cmd), переходим в директорию скрипта ( cd путь/до/папки/с/скрипта) и устанавливаем все необходимые библиотеки следующими командами:
pip install telethon

4. Открываем файл
Telegram Parser.exe

Вводим код авторизации Telegram
 Главное меню
Главное меню 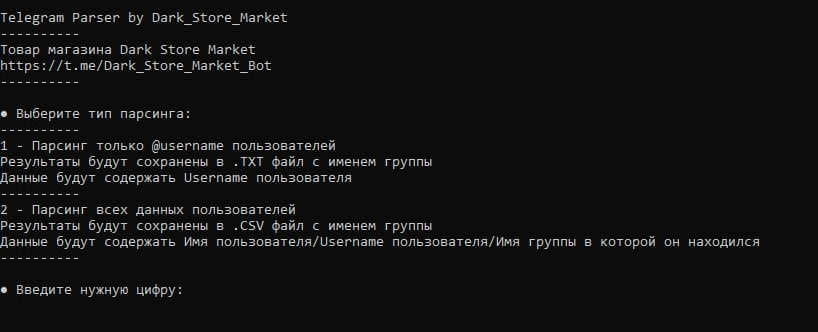
Парсер имеет несколько вариантов работы
- Результаты будут сохранены в .TXT файл с именем группы
- Данные будут содержать Username пользователя
- В файле будет указанно из какой группы собрана аудитория
● Парсинг всех данных пользователей
- Результаты будут сохранены в .CSV файл с именем группы
- Данные будут содержать Имя пользователя/Username пользователя/Имя группы в которой он находился
Выбираем нужный тип работы отправив соответствующую цифру
Выбираем нужную группу отправив соответствующую цифру

- Для выбора доступны все группы в которых состоит аккаунт
Парсер успешно начинает работу
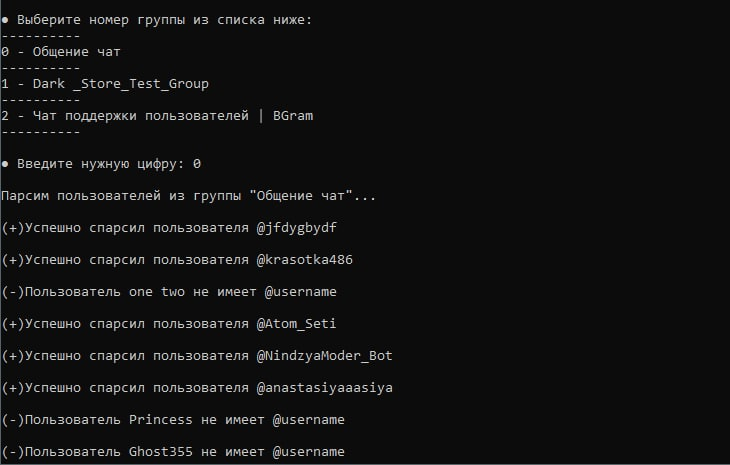
После окончания парсинга показывается подробная информация о проделанной работе
Результаты парсинга
Парсинг всех данных пользователей
Выбираем нужную группу отправив соответствующую цифру

- Для выбора доступны все группы в которых состоит аккаунт
Парсер успешно начинает работу

После окончания парсинга показывается подробная информация о проделанной работе
Результаты парсинга
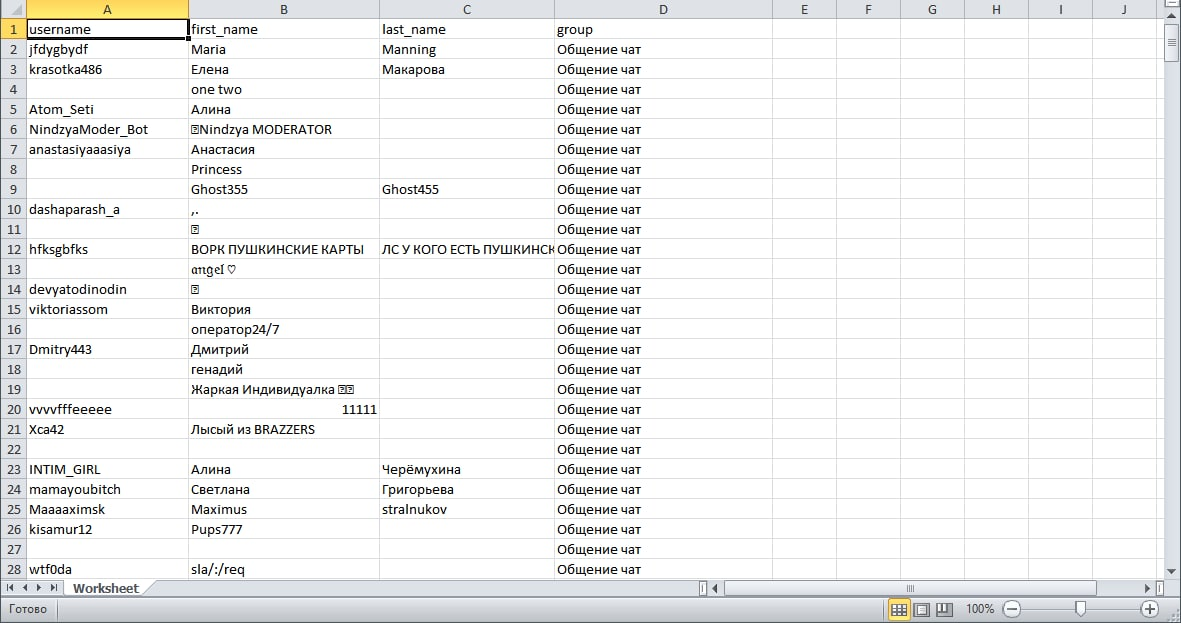
- Если у пользователя нет каких то данных в профиле (Имя/Фамили/Юзера)
Это поле будет пустым
Все результаты сохраняются в папку parse
Каждый новый результат записывается в файл с именем группы из которого была получена аудитория

- Формат сохраненного файла зависит от выбора типа парсинга
Если в имени группы присутствуют символы
- Файл будет сохранен с рандомным номером
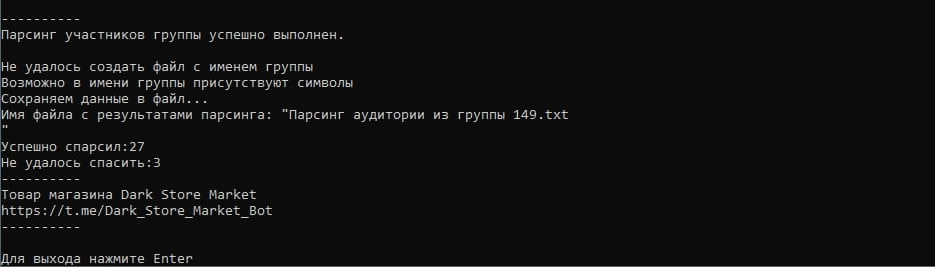
- Если файл в формате .txt то в файле будет указано название группы из которой была взята аудитория

Источник: telegra.ph
Как написать парсер для телеграмм
В данном туториале мы научимся собирать данные и сообщения участников чатов и каналов Telegram, а также сохранять эту информацию в виде JSON-файлов, которые далее легко анализировать или экспортировать в базы данных.
Для указанных задач будет использоваться Python не ниже версии 3.5, а также высокоуровневая библиотека для работы с Telegram API – Telethon. Установить библиотеку можно с помощью менеджера пакетов pip :
pip3 install telethon
Для подключения к Telegram API необходимы api_id и api_hash . Эти параметры выдаются при регистрации приложения в инструментах разработчика (при отсутствии доступа используйте VPN). Для авторизации указываем номер телефона, к которому привязан аккаунт Telegram.
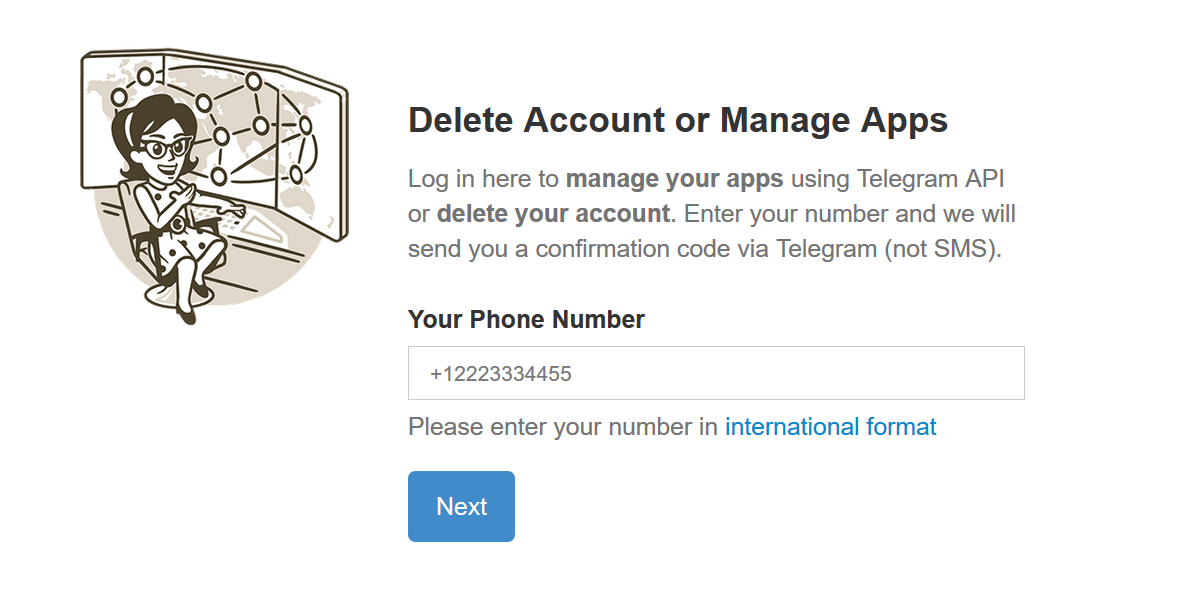
Вводим пришедший в Telegram численно-буквенный код и попадаем на страницу регистрации нового приложения. Заполняем форму, достаточно первых двух граф:
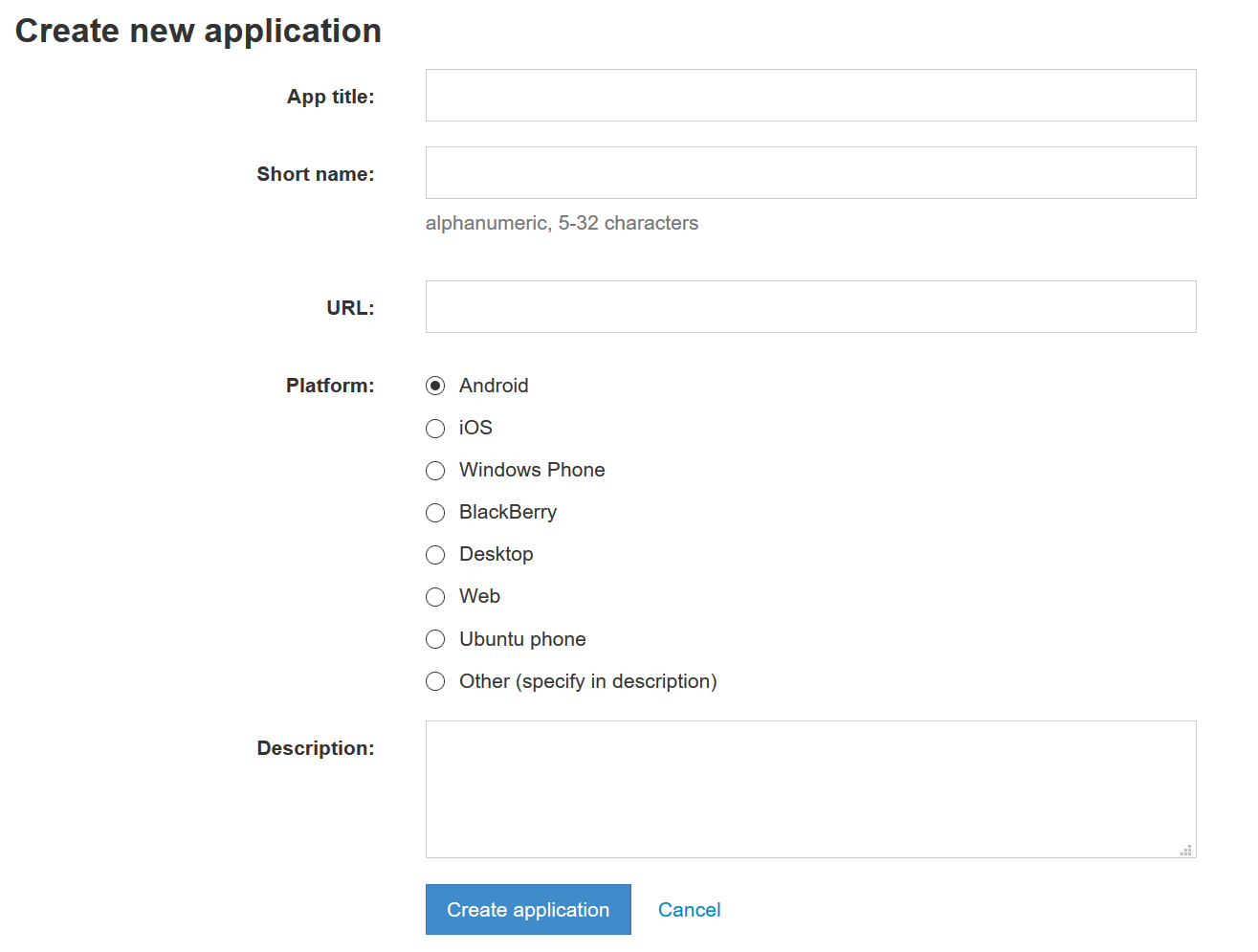
В результате попадаем на страницу конфигурации приложения. Находим оба параметра, а также доступные MTProto-сервера и открытые (публичные) ключи.
Избегая проблем с безопасностью, сохраняем учетные данные в отдельном файле config.ini следующей структуры:
[Telegram] api_id = Telegram-API-ID api_hash = Telegram-API-Hash username = Your-Telegram-Username
Поле username далее будет использоваться лишь для автоматического сохранения сессии под именем username.session . Одному клиенту соответствует одна сессия, учтите это в случае запуска нескольких клиентов.
Создаем клиент Telegram
Начнем с импорта библиотек.
import configparser import json from telethon.sync import TelegramClient from telethon import connection # для корректного переноса времени сообщений в json from datetime import date, datetime # классы для работы с каналами from telethon.tl.functions.channels import GetParticipantsRequest from telethon.tl.types import ChannelParticipantsSearch # класс для работы с сообщениями from telethon.tl.functions.messages import GetHistoryRequest
Встроенные модули configparser и json применяем соответственно для чтения параметров и вывода данных. Из библиотеки Telethon импортируем класс клиента Telegram и класс исключений. Внутренний модуль connection необходим при использовании прокси-сервера. Остальные элементы модуля telethon.tl используются для запросов необходимых нам списков (участников канала/чата и их сообщений).
Теперь считаем учетные данные из config.ini :
# Считываем учетные данные config = configparser.ConfigParser() config.read(«config.ini») # Присваиваем значения внутренним переменным api_id = config[‘Telegram’][‘api_id’] api_hash = config[‘Telegram’][‘api_hash’] username = config[‘Telegram’][‘username’]
Создадим объект клиента Telegram API:
client = TelegramClient(username, api_id, api_hash)
При необходимости прописываем прокси. При использовании протокола MTProxy прокси задается в виде кортежа (сервер, порт, ключ) .
proxy = (proxy_server, proxy_port, proxy_key) client = TelegramClient(username, api_id, api_hash, connection=connection.ConnectionTcpMTProxyRandomizedIntermediate, proxy=proxy)
client.start()
При первом запуске платформа запросит номер телефона, и вслед – код подтверждения. Так же, как если бы вы входили в учетную запись в приложении или браузере.
Для сбора, обработки и сохранения информации мы создадим две функции:
- dump_all_participants(сhannel) заберет данные о пользователях администрируемого нами сообщества channel ;
- dump_all_messages(сhannel) соберет все сообщения. Для этой функции достаточно, чтобы у вас был доступ к сообществу (необязательно быть администратором).
Обе функции будут вызываться в теле функции main , в которой пользователь передаст ссылку на интересующий источник:
url = input(«Введите ссылку на канал или чат: «) channel = await client.get_entity(url)
Касательно написания вызова функций стоит оговориться, что Telethon является асинхронной библиотекой. Поэтому в коде используются операторы async и await. В связи с этим функция main полностью будет выглядеть так:
async def main(): url = input(«Введите ссылку на канал или чат: «) channel = await client.get_entity(url) await dump_all_participants(channel) await dump_all_messages(channel)
Заметим, что из-за асинхронности Telethon может некорректно работать в средах, использующих те же подходы (Anaconda, Spyder, Jupyter).
Рекомендуемым способом управления клиентом является менеджер контекстов with . Его мы запустим в конце скрипта после описания вложенных в main функций.
with client: client.loop.run_until_complete(main())
Собираем данные об участниках
Telegram не выводит все запрашиваемые данные за один раз, а выдает их в пакетном режиме, по 100 записей за каждый запрос.
async def dump_all_participants(channel): «»»Записывает json-файл с информацией о всех участниках канала/чата»»» offset_user = 0 # номер участника, с которого начинается считывание limit_user = 100 # максимальное число записей, передаваемых за один раз all_participants = [] # список всех участников канала filter_user = ChannelParticipantsSearch(») while True: participants = await client(GetParticipantsRequest(channel, filter_user, offset_user, limit_user, hash=0)) if not participants.users: break all_participants.extend(participants.users) offset_user += len(participants.users)
Устанавливаем ограничение в 100, начинаем со смещения 0, создаем список всех участников канала all_participants . Внутри бесконечного цикла передаем запрос GetParticipantsRequest .
Проверяем, есть ли у объекта participants свойство users . Если нет, выходим из цикла. В обратном случае добавляем новых членов в список all_participants , а длину полученного списка добавляем к смещению offset_user . Следующий запрос забирает пользователей, начиная с этого смещения. Цикл продолжается до тех пор, пока не соберет всех фолловеров канала.
Самый простой способ сохранить собранные данные в структурированном виде – воспользоваться форматом JSON. Базы данных, такие как MySQL, MongoDB и т. д., стоит рассматривать лишь для очень популярных каналов и большого количества сохраняемой информации. Либо если вы планируете такое расширение в будущем.
В JSON-файле можно хранить и всю информацию о каждом пользователе, но обычно достаточно лишь нескольких параметров. Покажем на примере, как ограничиться набором определенных данных:
all_users_details = [] # список словарей с интересующими параметрами участников канала for participant in all_participants: all_users_details.append() with open(‘channel_users.json’, ‘w’, encoding=’utf8′) as outfile: json.dump(all_users_details, outfile, ensure_ascii=False)
Итак, для каждого пользователя создается свой словарь данных и добавляется в общий список all_user_details , который записывается в JSON-файл.
Собираем сообщения
Ситуация со сбором сообщений идентична сбору сведений о пользователях. Отличия сводятся к трем пунктам:
- Вместо клиентского запроса GetParticipantsRequest необходимо отправить GetHistoryRequest со своим набором параметров. Так же, как и в случае со списком участников запрос ограничен сотней записей за один раз.
- Для списка сообщений важна их последовательность. Чтобы получать последние сообщения, нужно правильно задать смещение в GetHistoryRequest (с конца).
- Чтобы корректно сохранить данные о времени публикации сообщений в JSON-файле, нужно преобразовать формат времени.
import configparser import json from telethon.sync import TelegramClient from telethon import connection # для корректного переноса времени сообщений в json from datetime import date, datetime # классы для работы с каналами from telethon.tl.functions.channels import GetParticipantsRequest from telethon.tl.types import ChannelParticipantsSearch # класс для работы с сообщениями from telethon.tl.functions.messages import GetHistoryRequest # Считываем учетные данные config = configparser.ConfigParser() config.read(«config.ini») # Присваиваем значения внутренним переменным api_id = config[‘Telegram’][‘api_id’] api_hash = config[‘Telegram’][‘api_hash’] username = config[‘Telegram’][‘username’] proxy = (proxy_server, proxy_port, proxy_key) client = TelegramClient(username, api_id, api_hash, connection=connection.ConnectionTcpMTProxyRandomizedIntermediate, proxy=proxy) client.start() async def dump_all_participants(channel): «»»Записывает json-файл с информацией о всех участниках канала/чата»»» offset_user = 0 # номер участника, с которого начинается считывание limit_user = 100 # максимальное число записей, передаваемых за один раз all_participants = [] # список всех участников канала filter_user = ChannelParticipantsSearch(») while True: participants = await client(GetParticipantsRequest(channel, filter_user, offset_user, limit_user, hash=0)) if not participants.users: break all_participants.extend(participants.users) offset_user += len(participants.users) all_users_details = [] # список словарей с интересующими параметрами участников канала for participant in all_participants: all_users_details.append() with open(‘channel_users.json’, ‘w’, encoding=’utf8′) as outfile: json.dump(all_users_details, outfile, ensure_ascii=False) async def dump_all_messages(channel): «»»Записывает json-файл с информацией о всех сообщениях канала/чата»»» offset_msg = 0 # номер записи, с которой начинается считывание limit_msg = 100 # максимальное число записей, передаваемых за один раз all_messages = [] # список всех сообщений total_messages = 0 total_count_limit = 0 # поменяйте это значение, если вам нужны не все сообщения class DateTimeEncoder(json.JSONEncoder): »’Класс для сериализации записи дат в JSON»’ def default(self, o): if isinstance(o, datetime): return o.isoformat() if isinstance(o, bytes): return list(o) return json.JSONEncoder.default(self, o) while True: history = await client(GetHistoryRequest( peer=channel, offset_id=offset_msg, offset_date=None, add_offset=0, limit=limit_msg, max_id=0, min_id=0, hash=0)) if not history.messages: break messages = history.messages for message in messages: all_messages.append(message.to_dict()) offset_msg = messages[len(messages) — 1].id total_messages = len(all_messages) if total_count_limit != 0 and total_messages >= total_count_limit: break with open(‘channel_messages.json’, ‘w’, encoding=’utf8′) as outfile: json.dump(all_messages, outfile, ensure_ascii=False, cls=DateTimeEncoder) async def main(): url = input(«Введите ссылку на канал или чат: «) channel = await client.get_entity(url) await dump_all_participants(channel) await dump_all_messages(channel) with client: client.loop.run_until_complete(main())
Если для анализа сообщений потребуются не все записи, задайте их число в переменной total_count_limit . Если нужна только сборка сообщений канала, достаточно закомментировать вызов await dump_all_participants(channel) .
Таким образом, с помощью Python и Telethon мы написали скрипт, собирающий и сохраняющий данные и реплики участников сообществ Telegram.
Источник: pishuverno.ru