Чтобы подгрузить данные контента на ютубе, обычно используют либо Selenium, либо YouTube API. Однако везде есть свои минусы.
- Selenium слишком медленный для парсинга. Представьте себе парсинг плейлиста из ~1000 роликов селениумом.
- YouTube API, конечно, наилучший вариант, если у вас какое-то свое приложение или проект, но там требуется зарегистрировать приложение и т.д. В «пробной» версии вам нужно постоянно авторизовываться для использования апи, еще там присутствует быстро заканчиваемая квота.
- В нашем методе, я бы сказал, очень сложные структуры данных, выдаваемыми ютубом. Особенно нестабильно работает парсинг поиска ютуб.
Как подгружать данные на ютубе?
Для этого есть токен, который можно найти в html коде страницы. Потом в дальнейшем его используем, как параметр для запроса к ютубу, выдающему нам новый контент. Сам ютуб прогружает контент с помощью запроса, где как раз используется этот токен.
Там есть дополнительные исходящие параметры, которые нам будут нужны в следующем шаге.
Как СПАРСИТЬ ВИДЕО на ЮТУБ PYTHON Парсинг ВИДЕО НА ЮТУБ через ТЕЛЕГРАМ БОТ PyTelegramBotApi Selenium

Получение токена через скрипт
Составляем параметр headers для запроса к ютубу. Помимо user-agent вставляем два дополнительных, которые вы видите ниже.
headers =
Делаем запрос с помощью библиотеки requests. Ставляете ссылку на страницу, которую нужно прогрузить, а также добавляете headers.
token_page = requests.get(url, headers=headers)
Токен невозможно найти парсерами, т.к он спрятан в тэге script. Чтобы сохранить его в переменную, я прописываю такой некрасивый код:
nextDataToken = token_page.text.split(‘»nextContinuationData»:<«continuation»:»‘)[1].split(‘»,»‘)[0]
Обычно это токен длиной 80 символов.
Делаем запрос на получение контента
service = ‘https://www.youtube.com/browse_ajax’ params = < «ctoken»: nextDataToken, «continuation»: nextDataToken >r = requests.post(service, params=params, headers=headers)
Разные типы подгружаемых данных имеют разные service ссылки. Наша подойдет для плейлистов и видео с каналов.
Данные Ютуб присылает в json формате. Поэтому пишем r.json(), но вам прилетит список, нам нужен второй элемент списка, поэтому r.json()[1]. Далее у нас уже имеются данные. Остается парсить.
Парсинг json ответа
Можно увидеть длинные цепочки словарей, но мы их сократим, чтобы было более менее понятно.
r_jsonResponse = r_json[‘response’] dataContainer = r_jsonResponse[«continuationContents»][«playlistVideoListContinuation»] nextDataToken = dataContainer[«continuations»][0][«nextContinuationData»][«continuation»]
Здесь мы получаем новый токен для дальнейшего запроса. Если подгружаемые данные закончились, то токена вы не увидите.
for content in dataContainer[«contents»]: videoId = content[‘playlistVideoRenderer’][‘videoId’]
Вот так можно извлечь id видеоролика, дописав шаблонную часть, вы получите ссылку на видеоролик.
Парсер ютуба на Python. Новый способ без ограничений
Чтобы получить следующие данные, вы должны проделать тоже самое — запрос токеном, парсинг и потом снова.
Полностью рабочий код выглядит вот так:
import requests, json url = input(‘url: ‘) headers = < «User-Agent»: «Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36″, ‘x-youtube-client-name’: ‘1’, ‘x-youtube-client-version’: ‘2.20200429.03.00’, >token_page = requests.get(url, headers=headers) nextDataToken = token_page.text.split(‘»nextContinuationData»: <«continuation»:»‘)[1].split(‘»,»‘)[0] sleep = False #Цикл будет завершен, когда не будет токенов ids = [] while not sleep: service = ‘https://www.youtube.com/browse_ajax’ params = < «ctoken»: nextDataToken, «continuation»: nextDataToken >r = requests.post(service, params=params, headers=headers) r_json = r.json()[1] r_jsonResponse = r_json[‘response’] dataContainer = r_jsonResponse[«continuationContents»][«playlistVideoListContinuation»] try: #пробуем найти токен nextDataToken = dataContainer[«continuations»][0][«nextContinuationData»][«continuation»] except: #токен не найден. Значит, далее запроса не будет. Остается собрать оставшийся контент sleep = True for content in dataContainer[«contents»]: videoId = content[‘playlistVideoRenderer’][‘videoId’] ids.append(videoId) print(len(ids))
Источник: h.amazingsoftworks.com
Парсер сайтов на Python
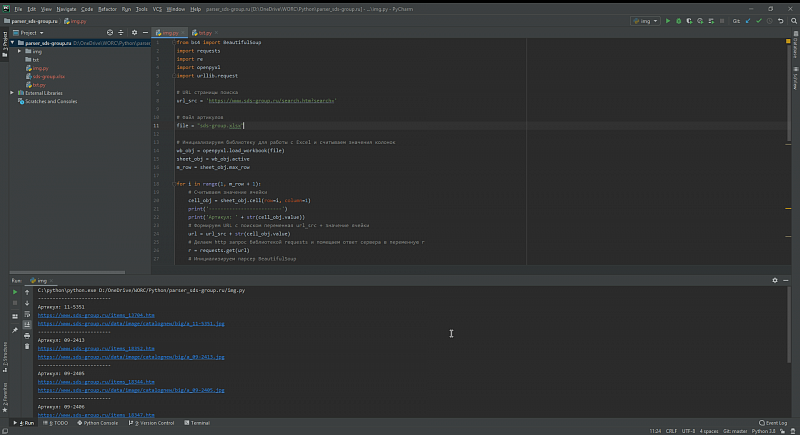
Сегодня мы напишем с вами парсер сайтов на Python
Задача:
С сайта https://www.sds-group.ru/ загрузить изображения товаров в формате артикул_товара.jpg и описание товаров в формате артикул_товара.txt для последующей загрузки в 1С.
Файл Excel с артикулами которые нужно загрузить прилагается(в файле две колонки первая — артикула, вторая — наименование товара).
Для этой задачи нам понадобятся дополнительные библиотеки BeautifulSoup, requests, openpyxl и стандартная библиотека re, установим недостающее библиотеки:
pip install beautifulsoup4 pip install requests pip install openpyxl
Для начала напишем загрузку картинок, создаем файл img.py и в начале файла импортируем нужные нам библиотеки:
from bs4 import BeautifulSoup import requests import re import openpyxl import urllib.request
При анализе сайта выясняем что поиск на сайте работает через GET параметр search, и URL поиска будет выглядеть как https://www.sds-group.ru/search.htm?search=сюда_можно_подставить_артикул , занесем переменные в наш скрипт
# Инициализируем библиотеку для работы с Excel и считываем значения колонок wb_obj = openpyxl.load_workbook(file) sheet_obj = wb_obj.active m_row = sheet_obj.max_row
for i in range(1, m_row + 1): # Считываем значение ячейки cell_obj = sheet_obj.cell(row=i, column=1) print(‘————————-‘) print(‘Артикул: ‘ + str(cell_obj.value)) # Формируем URL с поиском переменная url_src + значение ячейки url = url_src + str(cell_obj.value) # Делаем http запрос библиотекой requests и помещаем ответ сервера в переменную r r = requests.get(url) # Инициализируем парсер BeautifulSoup soup = BeautifulSoup(r.text, ‘html.parser’) # Находим на полученной странице с сайта элемент с классами flex-3 m-flex t-left(именно в этом элементе содержится ссылка на детальную страницу товара) url_item = soup.find_all(class_=’flex-3 m-flex t-left’) url_item_str = str(url_item) item = re.findall(‘href=[‘»]?([^'» >]+)’, url_item_str) # Проверяем нашелся ли вообще нужный артикул на сайте? если нет то переходим к следующему артиклу из файла try: item_href = str(item[0]) print(‘https://www.sds-group.ru’ + item_href) except IndexError: print(‘Артикул на сайте не найден’) continue # Если артикул нашелся то переходим на страницу детального просмотра r = requests.get(‘https://www.sds-group.ru’ + item_href) soup2 = BeautifulSoup(r.text, ‘html.parser’) # Изображение находится в div с классом product-img, находим его и получаем прямую ссылку на картинку img_item = soup2.find(«div», ) img = img_item.img[‘src’] img_src = ‘https://www.sds-group.ru’ + img print(img_src) # Скачиваем файл в папку img try: urllib.request.urlretrieve(img_src, ‘./img/’ + str(cell_obj.value) + ‘.jpg’) except: print(‘Не получилось сохранить файл’)
Парсер текстового описание товаров выглядит аналогично, но с небольшими особенностями, я сделал его отдельным файлом — txt.py
Источник: nikovit.ru
Как скачать видео с YouTube при помощи Python
YouTube – это известный интернет-сервис потокового видео. Здесь собраны миллионы видеороликов в таких категориях, как образование, развлечения и путешествия. Эти видео можно запросто просматривать, но скачивать довольно сложно. Недавнее обновление YouTube позволяет сохранять видео в папке загрузок для просмотра в автономном режиме. Тем не менее, вы не можете сохранять их локально.
Из этого руководства вы узнаете, как написать код на Python для загрузки видео с YouTube. Вероятно, вам известно, что одним из достоинств Python является огромное количество модулей и библиотек. Мы напишем скрипт, используя популярный пакет pytube .
Чтобы следовать этому руководству, вам понадобятся:
- понимание языка Python
- Python 3+, установленный на вашем компьютере
- редактор кода.
Обзор и установка pytube
Pytube – это небольшой, свободный от зависимостей модуль Python для доступа к видео из интернета. Этот модуль не поставляется в комплекте с Python, а значит, для использования его необходимо сначала установить. Если у вас есть pip , установка проста.
Чтобы установить pytube с помощью pip, вам нужно открыть командную строку от имени администратора и ввести следующую команду:
pip install pytube
Python-скрипт для загрузки видео с YouTube
Когда модуль установлен, можно приступать к работе. Для обращения к определенному видео на YouTube необходимо создать объект YouTube, в конструктор которого передается ссылка на видео. Затем указывается нужное расширение и разрешение видео. Имя файла можно изменить по своему усмотрению (в противном случае будет сохранено исходное имя).
Давайте рассмотрим на примере, как все это работает.
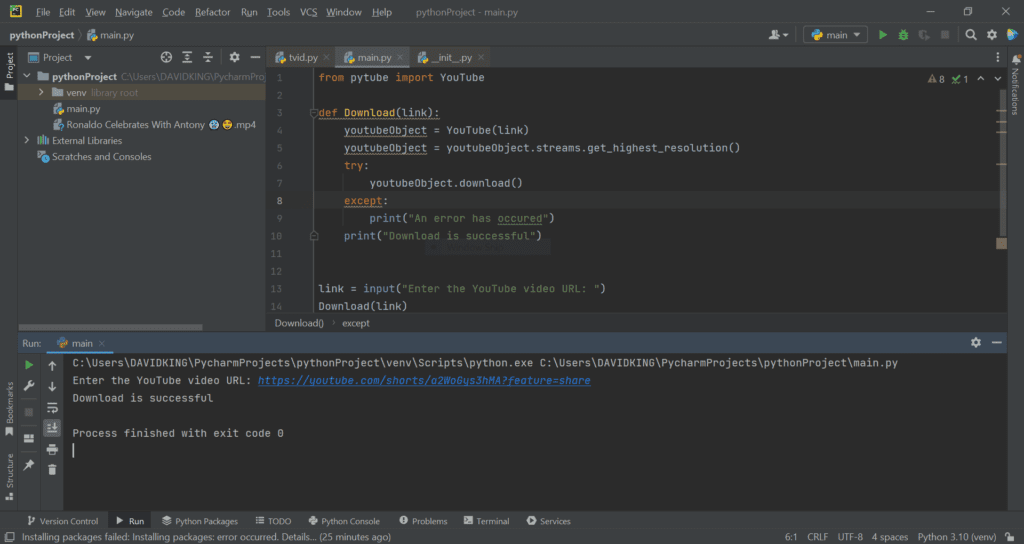
from pytube import YouTube def Download(link): youtubeObject = YouTube(link) youtubeObject = youtubeObject.streams.get_highest_resolution() try: youtubeObject.download() except: print(«An error has occurred») print(«Download is completed successfully») link = input(«Enter the YouTube video URL: «) Download(link)
Строка from pytube import YouTube нужна для импорта библиотеки. Затем мы определяем функцию Download.
Строка youtubeObject = youtubeObject.streams.get_highest_resolution() указывает, что загружать нужно самое высокое доступное разрешение.
try и except нужны, чтобы вернуть сообщение об ошибке, если загрузка не удалась. В противном случае будет выведено, что загрузка завершена успешно.
В переменную link мы сохраняем пользовательский ввод – ссылку на видео на YouTube. Сразу после нажатия кнопки Enter начнется загрузка видео.
Примечание редакции: о try-except можно почитать в статье “Чем полезна обработка ошибок при помощи try-except”.
Вот как выглядит запуск нашего кода в редакторе:
Примечание редакции: о том, как запускать полученный скрипт, читайте в статье “Как запустить скрипт Python”.
Загруженное видео вы найдете в той же папке, где находится скрипт. Но при желании вы можете переместить его в удобное для вас место. В моем случае видео называется “Ronaldo celebrates with Antony.mp4”.
Желательно, чтобы во время работы скрипта у вас было надежное подключение к Интернету.
Библиотека pytube имеет множество сложных и интересных функций. Познакомиться с ними можно, почитав хорошо написанную официальную документацию.