Здравствуйте, уважаемые читатели, почитатели и прочие хорошие люди!
Случалось ли Вам получать и читать письма на “фиг каком пойми языке” или заходить на какой-нибудь интернет-ресурс и вместо привычных букв видеть сплошные кракозябры? Если да, тогда эта заметка для Вас, ибо в ней мы поговорим о кодировке страниц, её форматах, почему оная возникает и как впредь избежать непонятных иероглифов.

Итак, сегодня нас ждет не легкая софтовая статья, а суровая техническая, так что приготовьтесь: будем немного ударяться в суровые реалии.
Поехали.
Что такое кодировка текста и с чем ее едят?
Начать хотелось бы с того, что этой статьи могло бы и не быть, т.к. компьютерно-юзательная жизнь автора этих строк протекала вполне себе спокойно и достойно. Но вот в один прекрасный день, шляясь по просторам сети Интернет не со своего ПК, я столкнулся с непонятными явлениями на некоторых сайтах. Заходя на интернет-ресурсы, я видел не привычный нам русский алфавит и красивый понятный текст, а какую-то ересь в виде непонятной последовательности символов. Выглядела она примерно вот так (см. изображение).
Как убрать иероглифы в SAMP | CRMP | MTA
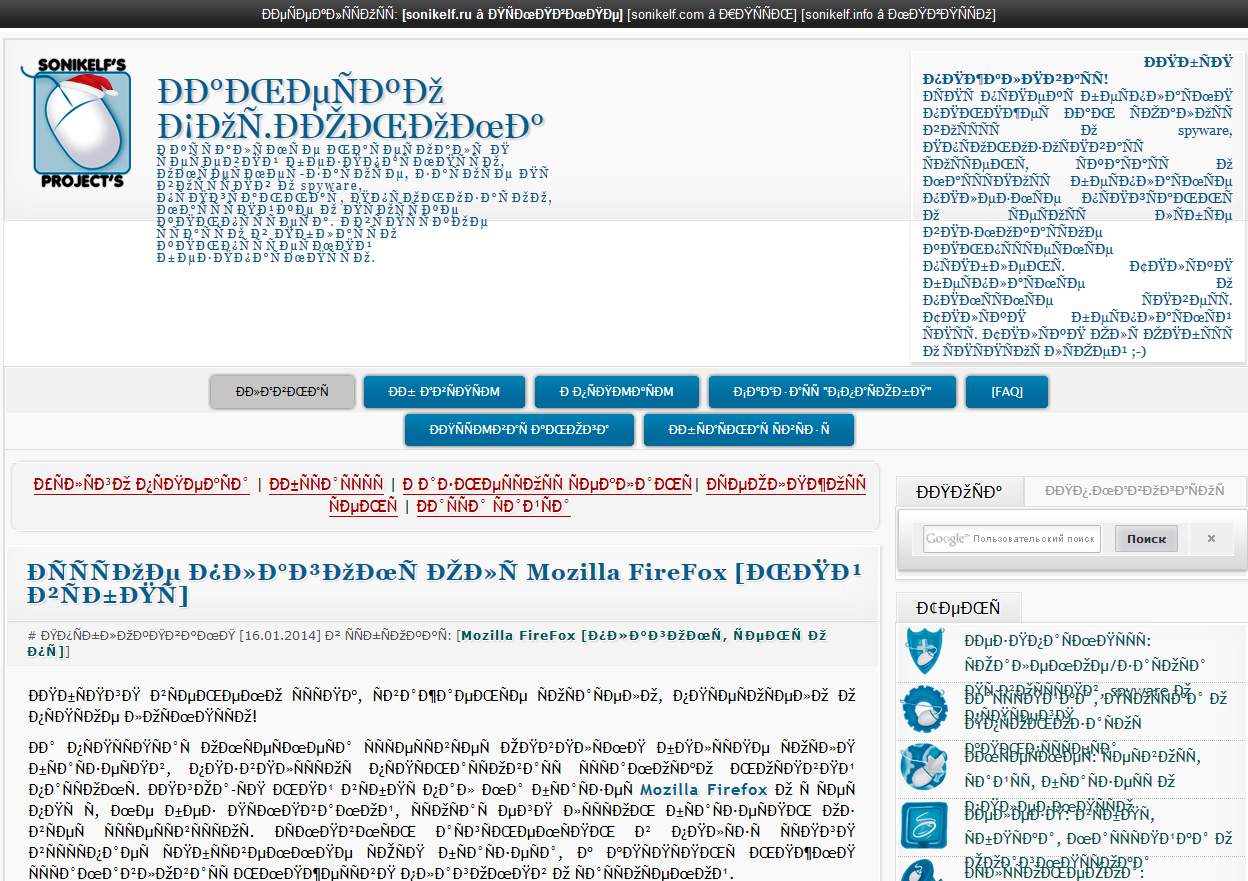
Сначала я подумал, что моя любимая Мозилка (браузер Firefox) перегрелась и ей пора вызывать неотложку, но потом начал понимать, что проблема, скорее всего, на стороне ресурса сети и кроется она в неправильно настроенной кодировке. Это действительно оказалось так, и пошаманив немного с бубном, проблемка была оперативно решена. Результатом же всех моих любовных похождений и стал сегодняшний материал. Собственно, поехали разбираться в деталях.
Всю информацию, представленную в цифровом виде и находящуюся в глобальной паутине, нужно рассматривать с двух сторон: первая — со стороны пользователя (красивый и ухоженный текст на экране монитора) и вторая – со стороны поисковой машины (некий программный код, состоящий из различных тегов/метатегов, таблицы символов и прочее).
Если Вы хоть немного знакомы с языком разметки гипертекста ( HTML ), то должны быть в курсе, что сайт глазами поисковых машин (Google, Яндекс ) видится не как обычный текст, а как структурированный документ, состоящий из последовательностей различного рода тегов. Чтобы было понятней, о чем я говорю, давайте взглянем на всеми нами любимый сайт Заметки Сис.Админа ” проекта [ Sonikelf’s Project’s ], но не глазами обычного пользователя, а «глазами» поисковика. Для этого нажимаем сочетание клавиш Сtrl+U (для браузеров Firefox и Chrome ) и видим следующую картину (см. изображение):
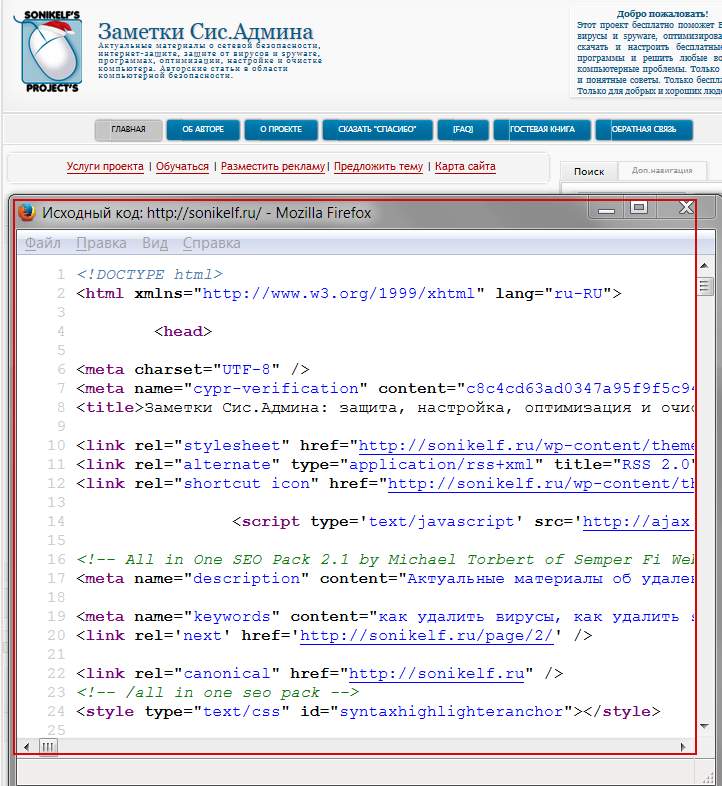
Перед нами машинный вариант sonikelf.ru , вот в таком вот непрезентабельном виде он подается поисковым системам и именно в таком виде они его и кушают. Если бы мы просто взяли и “засандалили” варианты статей из блокнота или Word обычным текстом, машины бы им не то что подавились, они бы даже и есть его не стали. Итак, перед нами главная страница проекта в HTML -виде. Обратите внимание на строку с надписью UTF-8 , это не что иное, как пресловутая кодировка текста страницы, именно она и отвечает за формат вывода информации в презентабельном виде, в результате чего через браузер мы видим нормальный текст.
ЛАЙФХАК: КАК ПИСАТЬ И ЗАПОМИНАТЬ ИЕРОГЛИФЫ. От ПРОСТОГО иероглифа к СЛОЖНОМУ
Теперь давайте разберемся, почему же происходит так, что порой на экране монитора мы видим кракозябры. Все очень просто, проблема кроется в открытии файла в неверной кодировке. Если перевести на бытовой язык, то допустим Вас послали в магазин за молоком, а Вы притарабанили хлеб, вроде бы тоже съестное, но совсем другой формат продукта.
Итак, теперь давайте разбираться с теорией и для этого введем некоторые определения.
- Кодировка (или “ Charset ”) – соответствие набора символов набору числовых значений. Нужна для “сливания” информации в интернет, т.е. текстовая информация преобразуется в биты данных;
- Кодовая страница (“ Codepage ”) – 1 байтовая ( 8 бит) кодировка;
- Количество значений, принимаемое 1 байтом – 256 (два в восьмой).
Соответствие “символ-изображение” задается с помощью специальных кодовых таблиц, где каждому символу уже присвоен свой конкретный числовой код. Таких таблиц существует достаточно много, и в разных таблицах один и тот же символ может идентифицироваться по-разному (ему могут соответствовать разные числовые коды).
Все кодировки различаются количеством байт и набором специальных знаков, в которые преобразуется каждый символ исходного текста.
Примечание:
Декодирование – операция, в результате которой происходит преобразование кода символа в изображение. В результате этой операции информация выводится на экран монитора пользователя.
В общем.. С определениями разобрались, а теперь давайте узнаем, какие же (кодировки) бывают.
Виды кодировок текста
А их, в общем-то, хватает.
Одной из самых “древних” считается американская кодировочная таблица ( ASCII , читается как “аски”), принятая национальным институтом стандартов. Для кодировки она использовала 7 битов, в первых 128 значениях размещался английский алфавит (в нижнем и верхнем регистрах), а также знаки, цифры и символы. Она больше подходила для англоязычных пользователей и не была универсальной.
Отечественный вариант кодировки, для которого стали использовать вторую часть кодовой таблицы – символы с 129 по 256 . Заточена под русскоязычную аудиторию.
- Кодировки семейства MS Windows : Windows 1250-1258 .
8-битные кодировки, появились как следствие разработки самой популярной операционной системы, Windows . Номера с 1250 по 1258 указывают на язык, под который они заточены, например, 1250 – для языков центральной Европы; 1251 – кириллический алфавит.
- Код обмена информацией 8 бит – КОИ8
KOI8-R, KOI8-U, KOI-7 – стандарт для русской кириллицы в юникс-подобных операционных системах.
- Юникод ( Unicode )
Универсальный стандарт кодирования символов, позволяющий описать знаки практически всех письменных языков. Обозначение “ U+xxxx ” (хххх – 16-ричные цифры). Самые распространенные семейства кодировок UTF (Unicode Transformation Format) : UTF-8, 16, 32 .
В настоящее время, как говорится, “рулит” UTF-8 – именно она обеспечивают наилучшую совместимость со старыми ОС , которые использовали 8 -битные символы. В UTF-8 кодировке находятся большинство сайтов в сети Интернет и именно этот стандарт является универсальным (поддержка кириллицы и латиницы).
Разумеется, я привел не все виды кодировок, а только наиболее ходовые. Если же Вы хотите для общего развития знать их все, то полный список можно отыскать в самом браузере. Для этого достаточно пройти в нем на вкладку “ Вид-Кодировка-Выбрать список ” и ознакомиться со всевозможными их вариантами (см. изображение).
Думаю возник резонный вопрос: “ Какого лешего столько кодировок? ”. Их изобилие и причины возникновения можно сравнить с таким явлением, как кроссбраузерность/кроссплатформенность. Это когда один и тот же сайт сайт отображается по-разному в различных интернет-обозревателях и на различных гаджет-устройствах. Кстати у сайта » Заметки Сис.Админа » с этим, как Вы заметили всё в порядке :).
Все эти кодировки – рабочие варианты, созданные разработчиками “под себя” и решение своих задач. Когда же их количество перевалило за все разумные пределы, а в поисковиках стали плодиться запросы типа: “ Как убрать кракозябры в браузере? ” — разработчики стали ломать голову над приведением всей этой каши к единому стандарту, чтобы, так сказать, всем было хорошо. И кодировка Unicode , в общем-то, это “хорошо” и сделала. Теперь если такие проблемы и возникают, то они носят локальный характер, и не знают как их исправить только совсем непросвещенные пользователи (впрочем, часто беда с кодировкой и отображением сайтов появляется из-за того, что веб-мастер указал на стороне сервера некорректный формат, и приходится переключать кодировку в браузере).
Ну вот, собственно, пока вся «базово необходимая» теория, которая позволит Вам “не плавать” в кодировочных вопросах, теперь переходим к практической части статьи.
Решаем проблемы с кодировкой или как убрать кракозябры?
Итак, наша статья была бы неполной, если бы мы не затронули пользовательско-бытовые вопросы. Давайте их и рассмотрим и начнем с того, как (с помощью чего) можно посмотреть кодировку?
В любой операционной системе имеется таблица символов, ее не нужно докачивать, устанавливать – это данность свыше, которая располагается по адресу: “Пуск-программы-стандартные-служебные-таблица символов”. Это таблица векторных форм всех установленных в Вашей операционной системе шрифтов.
Выбрав “дополнительные параметры” (набор Unicode ) и соответствующий тип начертания шрифта, Вы увидите полный набор символов, в него входящих. Кликнув по любому символу, Вы увидите его код в формате UTF-16 , состоящий из 4 -х шестнадцатеричных цифр (см. изображение).
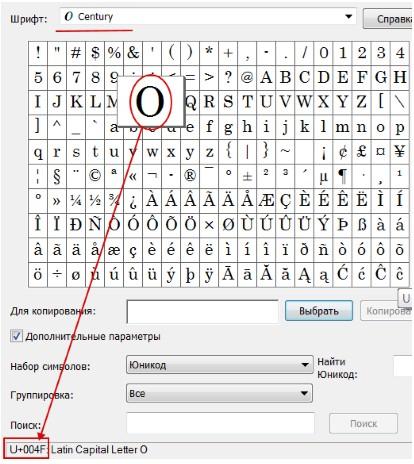
Теперь пара слов о том, как убрать кракозябры. Они могут возникать в двух случаях:
- Со стороны пользователя — при чтении информации в интернет (например, при заходе на сайт);
- Или, как говорилось чуть выше, со стороны веб-мастера (например, при создании/редактировании текстовых файлов с поддержкой синтаксиса языков программирования в программе Notepad ++ или из-за указания неправильной кодировки в коде сайта).
Рассмотрим оба варианта.
№1. Иероглифы со стороны пользователя.
Допустим, Вы запустили ОС и в каком-то из приложений у Вас отображаются пресловутые каракули. Чтобы это исправить, идем по адресу: “ Пуск — Панель управления — Язык и региональные стандарты — Изменение языка ” и выбираем из списка, » Россия «.

Также проверьте во всех вкладках, чтобы локализация была “ Россия/русский ” – это так называемая системная локаль.
Если Вы открыли сайт и вдруг поняли, что почитать информацию Вам не дают иероглифы, тогда стоит поменять кодировку средствами браузера (“ Вид — Кодировка ”). На какую? Тут все зависит от вида этих кракозябр. Ориентируйтесь на следующую шпаргалку (см. изображение).
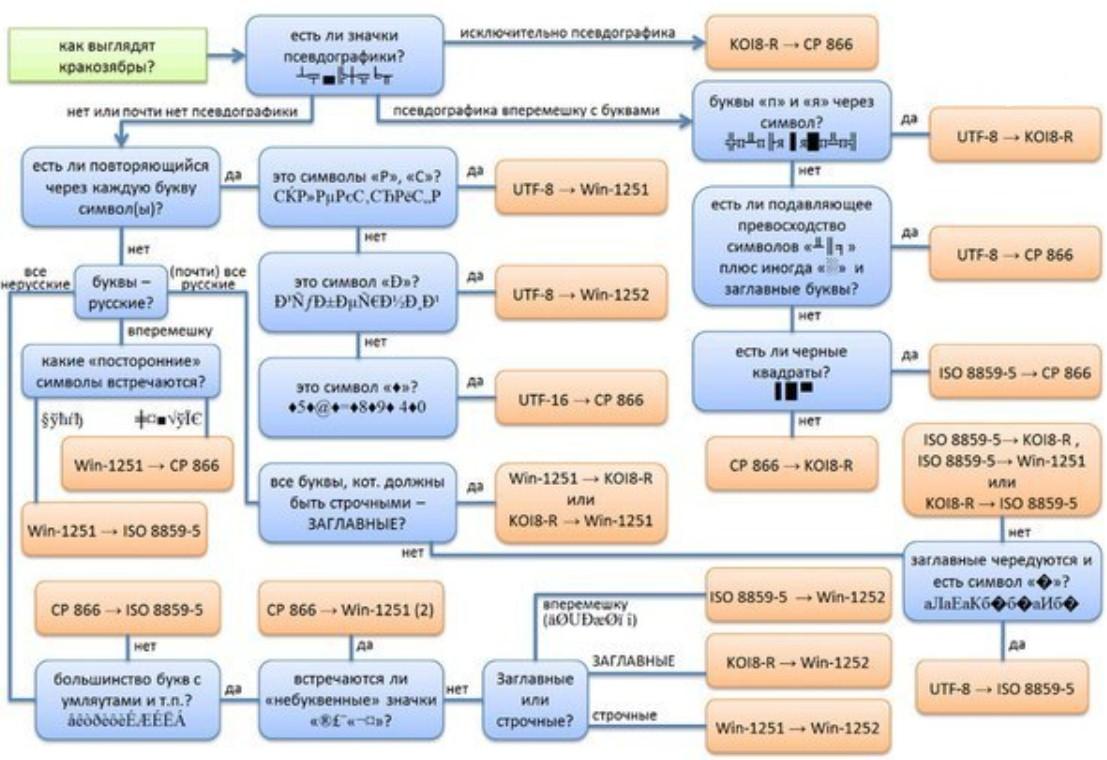
№2. Иероглифы со стороны веб-мастера.
Очень часто начинающие разработчики сайтов не придают большого значения кодировке создаваемого документа, в результате чего потом и сталкиваются с вышеозначенной проблемой. Вот несколько простых базовых советов для веб-мастеров, чтобы исправить беду.
Чтобы такого не происходило, заходим в редактор Notepad++ и выбираем в меню пункт “ Кодировки ”. Именно он поможет преобразовать имеющийся документ. Спрашивается, какой? Чаще всего (если сайт на WordPress или Joomla ), то “ Преобразовать в UTF-8 без BOM ” (см. изображение).
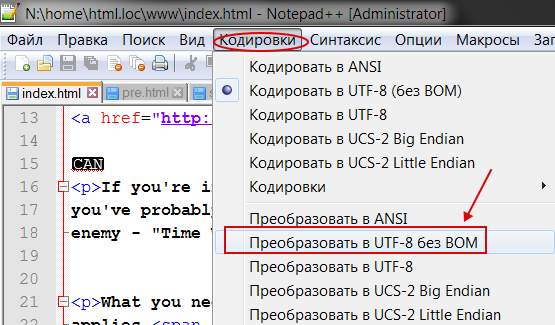
Сделав такое преобразование, Вы увидите изменения в строке статуса программы.

Также во избежание кракозябр необходимо принудительно прописать информацию о кодировке в шапке сайта. Тем самым Вы укажите браузеру на то, что сайт стоит считывать именно в прописанной кодировке. Начинающему веб-мастеру необходимо понимать, что чехарда с кодировкой чаще всего возникает из-за несоответствия настроек сервера настройкам сайта, т.е. на сервере в базе данных прописана одна кодировка, а сайт отдает страницы в браузер в совершенной другой.
Для этого необходимо прописать “внаглую” (в шапку сайта, т.е, как частенько, в файл header.php ) между тегами < head> < /head>следующую строчку:
Прописав такую строчку, Вы заставите браузер правильно интерпретировать кодировку, и иероглифы пропадут.
Также может потребоваться корректировка вывода данных из БД (MySQL). Делается сие так:
mysql_query(‘SET NAMES utf8’ );
myqsl_query(‘SET CHARACTER SET utf8’ );
mysql_query(‘SET COLLATION_CONNECTION=»utf8_general_ci'» ‘);
Как вариант, можно еще сделать ход конём и прописать в файл .htaccess такие вот строчки:
# BEGIN UTF8
AddDefaultCharset utf-8
AddCharset utf-8 *CharsetSourceEnc utf-8
CharsetDefault utf-8# END UTF8
Все вышеприведенные методы (или некоторые из них), скорее всего, помогут Вам и Вашим будущим посетителям избавиться от ненавистных иероглифов и проблем с кодировкой. К сожалению, более подробно мы здесь инструкцию по веб-мастерским штукам рассматривать не будем, думаю, что они обязательно разберутся в подробностях при желании (как-никак у нас несколько другая тематика сайта).
Ну, вот и практическая часть статьи закончена, осталось подвести небольшие итоги.
Послесловие
Сегодня мы познакомились с таким понятием, как кодировка текста. Уверен, теперь при возникновении каракулей на мониторе компьютера Вы не спасуете, а вспомните все приведенные здесь методы и решите вопрос в свою пользу!
На сим все, спасибо за внимание и до новых встреч.
P.S. Комментарии, как и всегда, ждут Ваших горячих дискуссий и вопросов, так что отписываем.
P.P.S : За существование данной статьи спасибо члену команды 25 КАДР
Мы в соц.сетях: ВКFacebookTwitter
Белов Андрей (Sonikelf) Заметки Сис.Админа [Sonikelf’s Project’s] Космодамианская наб., 32-34 Россия, Москва (916) 174-8226
Источник: sonikelf.ru
Как убрать иероглифы в одноклассниках


Решено. В программе вместо русских букв иероглифы, как исправить?
Подробности —> ![]() 03.07.2011
03.07.2011 ![]() 67
67 ![]() 125730
125730
У одного из наших клиентов появилась проблема — вместо русских букв в программе отображаются иероглифы. Эта проблема была обнаружена в двух программах — «налогоплатильщик» и «1С» 7.7. В налогоплатильщике верхнее меню полностью было на непонятном языке, в 1Ске иероглифами отображались только подсказки, хотя все остальные менюшки отображались нормально. Было найдено следующее решение:
- откройте редактор реестра. Пуск — выполнить — regedit, если у вас windows XP, и Пуск — поиск — regedit, если у вас windows vista или windows seven
- Перейдите на ветку реестра HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsCodePage
- Найдите строковый параметр 1252 и измените его значение с «c_1252.nls» на «c_1251.nls»
- Перезагрузитесь
Если этот способ вам не помог, то измените страну «текущего формата» на «Русский (Россия)». Сделать это можно так:
Пуск -> Панель управления -> Языки и региональные стандарты -> Текущий формат.
Для проблем в программе 1С Предприятия версии 7.7 может помочь следующий хак:
Зайдите в 1С Предприятие в конфигуратор. Далее: сервис -> настройка (5-ая строка) и уберите там пункт отображение пиктограмм.
P.S. Если у вас возникли проблемы с техникой, обращайтесь в наш компьютерный сервис, либо закажите выезд компьютерного мастера.
Источник: neosvc.ru
В Ворде появились непонятные символы как убрать
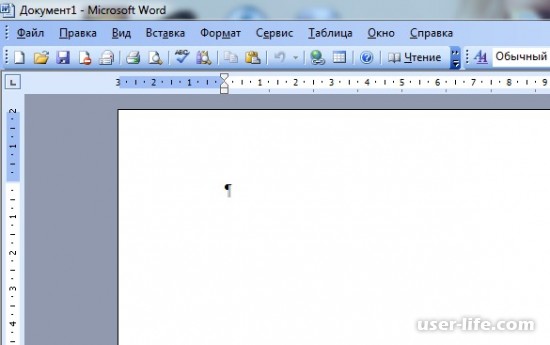

Всем привет! Сегодня поговорим про то как убрать непонятные символы из документа в популярном текстовом редакторе Майкрософт Ворд. Итак, поехали!
В случае если в документе были замечены странные знаки и точки, то их возможно прибрать с поддержкой инвентаря текстового редактора Word.
Эти значки дают возможность узнавать бесполезные пробелы или же отступы, символы табуляции. Но временами функция активизируется при случайном нажатии на кнопку в верхней панели или же применении неправильной композиции кнопок.
Знаки не выводятся на распечатку, а лишь только показываются в документе в электрическом варианте при просмотре документа.
Метод 1: Рабочая панель
При интенсивной функции отражения непечатаемых символов документ смотрится так, как на снимке экрана. Меж текстов показываются точки, а любое предложение или же отступ завершается с эмблемой «¶».
Дабы выключить отражение странных знаков, откройте вкладку «Главная» и в блоке «Абзац» отыщите кнопку со значком «¶». В случае если она деятельна, то режим отражения символов активирован. Для выключения довольно раз один щелкнуть левой кнопкой мыши по кнопке.
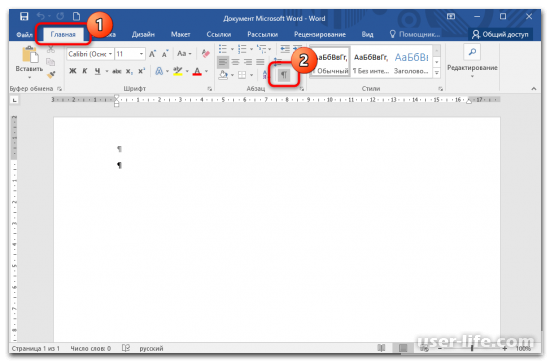
Метод 2: Композиция кнопок
Жаркие кнопки дают возможность проворно использовать всевозможные функции в текстовом редакторе Word. Они несомненно помогут выключить отражение непечатаемых значков, потому что в больше давних версиях программки случается непросто отыскать подходящую функцию.
Еще трудности появляются у юзеров операционной системы MacOS. Для отключения режима просмотра документа с странными значками в одно и тоже время зажмите кнопки «Ctrl + Shift + 8».
Метод 3: Отключение привязки объектов
В случае если ни 1 метод не несомненно помог, то рекомендовано выключить функцию неотклонимого отражения значков. Для их деактивации действуйте сообразно памятке.
В раскрытом документе откройте вкладку «Файл» на верхней панели.
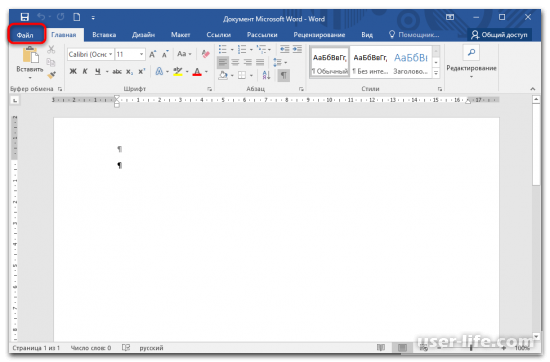
Нажмите по пункту «Параметры» в открывшемся окне.
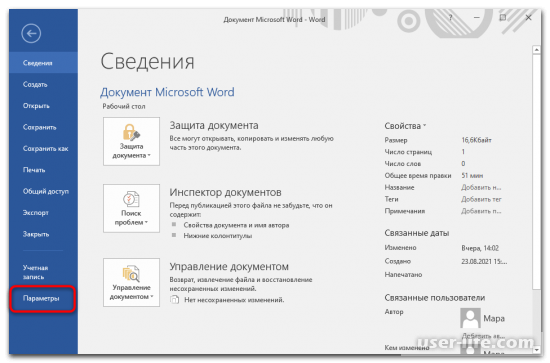
Отобразится вспомогательное окошко, где слева надо избрать раздел «Экран». В блоке с отражением символов форматирования снимите отметку с пункта «Привязка объектов».
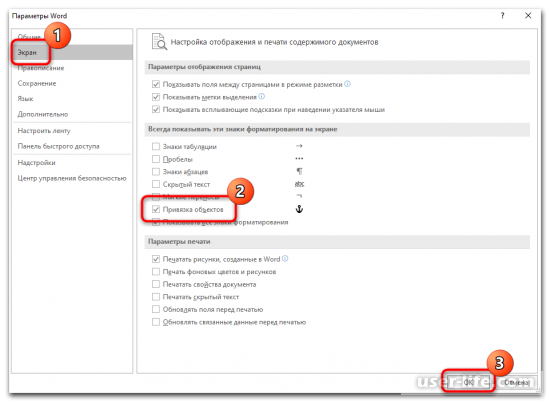
Впоследствии сего странные значки, точки и знаки пропадут из слова документа. В случае если надо выяснить его на присутствие двойных пробелов или же бесполезные символы, то понадобится активировать функцию сквозь характеристики файла.
Источник: user-life.com