Задумывались ли вы когда-нибудь о том, что интересующий вас сайт, например сайт многомиллионной корпорации, интернет-магазина, чей-то блог ранее мог выглядеть абсолютно по-другому? С течением времени меняется дизайн, может поменяться доменное имя, и наполнение сайта также, может стать другим. Да, у каждого сайта есть своя уникальная история.
Возможность узнать больше может быть полезна для того, чтобы узнать первоначальную тему сайта, а также о том, каким он был в разное время. При помощи так называемого веб-архива можно посмотреть историю конкретного сайта, узнать, как он использовался. Кроме того в веб-архиве можно найти множество полезных файлов: фотографии, картинки, музыкальные композиции.
Каким образом можно посмотреть, как выглядел сайт раньше?
Для того чтобы узнать о том, как сайт выглядел раньше стоит обратиться к сервису, который заслуживает отдельных аплодисментов. Он индексирует сайты в разное время и сохраняет их. Название сервиса — web archive . Его создал американский программист Брюстер Кейл в 1996 году.
КАК ВЫГЛЯДЕЛА ТВОЯ СТРАНИЦА ВКОНТАКТЕ 10 ЛЕТ НАЗАД? #shorts

До 1999 года это была вариация текстового архива, но начиная с 1999 года сервис функционирует как полноценное программное обеспечение и помимо всего прочего сохраняет фото, видео и аудиоматериалы. Основной целью его создателя стала идея о создании так называемой «библиотеки» в едином интернет-пространстве.
О сервисе web archive и чем он может помочь
Современные веб-архивы хранят в себе действительно большое количество данных. Важно уметь верно отсортировывать информацию и среди кучи «мусора» находить то, что действительно важно именно для вас. Для большинства пользователей очень важно: получить доступ к когда-то потерянным данным, изучить контент для будущего сайта, провести грамотную аналитику, собрать статистику. Веб-архив является публичным и каждый желающий может получить доступ к нему без каких-либо проблем.
Как правильно использовать сервис web archive
Для того чтобы увидеть принцип работы этого сервиса в действии — переходим сюда . Далее указываем адрес интересующего нас сайта: например: yandex.ru

Теперь мы сможем увидеть, что история для этой поисковой системы сохраняется с 1997 года. Достаточно просто выбрать интересующую вас дату, и вы увидите, как выглядел сайт Яндекса в то время.

А вот так портал Яндекс выглядел уже в 2005 году:

Аналогичным образом можно проверить подавляющее большинство сайтов, причём как зарубежных, так и отечественных.
КАК ВЫГЛЯДЕЛА ТВОЯ СТРАНИЦА ВК 10 ЛЕТ НАЗАД??? #shorts
Дополнительные возможности сервиса и что ещё можно найти в web archive
Многие, только планируя создать собственный сайт находятся в поисках уникального,
- Что такое веб-архив
- Зачем нужен web archive и как его можно использовать
- Как просмотреть старые версии сайтов на Wayback Machine
- Как добавить современную версию сайта в веб-архив Wayback Machine и выполнить другие действия
- Уникальный контент из веб-архива
Создание и наполнение онлайн-ресурса — это многоэтапный системный процесс. Контент фирменного сайта, интернет-магазина, лэндинга или портала должен постоянно обновляться с учетом целей и задач компании, изменений предпочтений целевой аудитории и алгоритмов поисковых систем. Но иногда старые тексты могут пригодиться, и тогда их можно найти на веб-архивах.
Что такое веб-архив
Веб-архив (web archive, internet archive) — это онлайн-платформа Wayback Machine, созданная в 1996 году. Здесь хранятся копии контента сайтов, интернет-магазинов, блогов, информационных и развлекательных порталов и других интернет-ресурсов, которые разрешены для сохранения. Это бесплатная онлайн-библиотека web.archive.org, где можно найти разные версии всех веб-ресурсов и просмотреть, как выглядел их контент, сохраненный на дату посещения сайта роботом сервиса.
Со времени создания веб-архива, здесь накопилось и на данный момент хранится больше 330 миллиардов файлов:
- интернет-страниц;
- аудио;
- видео;
- электронных книг и пр.
Зачем нужен web archive и как его можно использовать

Веб-архивирование нужно для того, чтобы можно было восстановить важную утерянную информацию с сайта, которая может не сохраниться из-за технических проблем или повреждения вирусом.
Например, владелец сайта создал его и наполнил описанием продукции, полезными статьями и изображениями по тематике. Через время веб-ресурс был обновлен и тексты заменены на новые. А еще через время понадобились именно старые тексты. В таких случаях и нужен открытый интернет-архив, в котором можно найти десятки сохраненных версий сайта на разные даты.
- Возможность восстановления собственного контента в случае повреждения или удаления старых текстов и изображений.
- Просмотр старых файлов на других работающих веб-сайтах.
- Анализ изменений наполнения онлайн-ресурсов (собственных и конкурентных).
Сохранение авторского контента — это важная функция. Намного проще корректировать уже имеющиеся тексты, чем писать новые с нуля. Можно сделать рерайт (переписывание текста другим словами с сохранением смысла и структуры). Особенности использования резервных копий приведены в Табл. 1.
Табл. 1. Для каких целей можно использовать более ранний контент
| Цели | Особенности применения |
| Восстановление сайта | Бывают случаи непоправимого повреждения онлайн-ресурса — из-за вирусов, хакерских атак.  Если не было проведено резервное копирование на своем хостинге, то можно будет найти свои тексты в веб-архиве Если не было проведено резервное копирование на своем хостинге, то можно будет найти свои тексты в веб-архиве |
| Наполнение сайта по похожей тематике | Старый экспертный текст по своей тематике может понадобиться при создании лэндинга, вспомогательного онлайн-ресурса. Если тексты неуникальны, их нужно рерайтить |
| Ведение блога | Для привлечения трафика на профильный сайт нужно вести блог с текстами узкой тематики. Это могут быть советы по выбору товаров, использованию продукции и другой контент. Для написания таких текстов может потребоваться информация со старых копий веб-ресурса |
| Публикации на странице в социальных сетях | Бизнес-аккаунт в соцсетях помогает поднять узнаваемость бренда и компании, привлечь новых покупателей, расширить рынки сбыта. Для постов в социальных сетях можно использовать тексты, которые ранее были опубликованы на сайте (если они не дублируются с новыми) |
Как просмотреть старые версии сайтов на Wayback Machine
Если вам необходимо найти старую версию страниц какого-либо веб сайта, выполните следующие действия:

- Наберите в поисковой строке адрес https://web. archive.org/.
- С главной страницы архива сайтов перейдите по ссылке на нужный раздел (файлы, видео, изображения и пр.), укажите адрес домена и нажмите «BROWSE HISTORY».
- Во временной шкале будут отображены все копии сайтов. Словно с помощью машины времени, здесь можно найти любую созданную ранее архивную копию и даже скачать ее при помощи специальных инструментов.
- В открывшемся календаре можно выбрать дату, отмеченную зеленым или голубым кружком (диаметр этого кружка зависит от числа обращений робота сервиса к онлайн-проекту в указанный день). Зеленым кружком обозначены редиректы.
Важно! Если веб-страницу через некоторое время не удается просмотреть, это может быть вызвано несколькими причинами:

- Правообладатель обратился на платформу архива интернета с требованием удалить копии.
- Сам веб-проект был закрыт из-за нарушения авторских прав и закона об использовании интеллектуальной собственности.
- Разработчики закрыли страницы своего онлайн-ресурса от индексации роботами поисковых систем.
Если вы хотите посмотреть, как выглядел веб-сайт, но на сохраненной копии нет изображений или других элементов дизайна (иногда они не сохраняются), нужно открыть другую версию, которую веб-архив сохранил в другой день.
Как добавить современную версию сайта в веб-архив Wayback Machine и выполнить другие действия
Онлайн-платформа по веб-архивированию сайтов предоставляет множество возможностей разработчикам и владельцам ресурсов (Табл. 2).
Табл. 2. Как работать с веб-архивом
| Возможности | Особенности выполнения |
| Сохранение нужной версии сайта на платформе интернет-архива | Нужно самостоятельно инициировать сохранение. В разделе платформы «Save Page Now» нужно забить домен онлайн-ресурса и нажать «Save page». Такую процедуру рекомендуется повторять каждый раз, когда в контент были внесены исправления или дополнения |
| Запрет на добавление интернет-ресурса в память веб-архива | Для запрета добавления нужно прописать это в файле robots.  txt. В панелях хостеров есть корневой каталог, в котором предусмотрена возможность редактирования файлов. При введении кода User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: / файл будет скрыт от копирования. При введении такого кода из веб-архива удаляется и текущая версия сайта и не осуществляется системное копирование (до тех пор, пока в файле robots.txt есть такие настройки или пока не закончится срок регистрации домена) txt. В панелях хостеров есть корневой каталог, в котором предусмотрена возможность редактирования файлов. При введении кода User-agent: ia_archiverDisallow: /User-agent: ia_archiver-web.archive.orgDisallow: / файл будет скрыт от копирования. При введении такого кода из веб-архива удаляется и текущая версия сайта и не осуществляется системное копирование (до тех пор, пока в файле robots.txt есть такие настройки или пока не закончится срок регистрации домена) |
| Восстановление веб-сайта из интернет-архива | Если сайт был поврежден вирусами или есть другие технические проблемы, из-за которых контент был нарушен, можно восстановить файлы из онлайн-хранилища. Для этого применяются специальные сервисы. Есть платные и бесплатные варианты, которые выбираются с учетом количества страниц для восстановления |
Уникальный контент из веб-архива

Многие коммерческие сайты через некоторое время существования закрываются. Если на них был опубликован полезный контент (экспертные статьи, аналитические обзоры и другая важная информация), то после закрытия первоисточника они могут быть востребованными. То есть, сайт уже не работает и ранее написанные статьи могут использоваться на информационных порталах (если они уникальны).
Веб-архив является очень полезным сервисом, который может пригодиться в различных ситуациях. Быстрое восстановление потерянных данных может значительно сэкономить время и финансы, если сайт подвергнется хакерской атаке или же перестанет работать из-за серьезной технической проблемы. Веб-архив дает возможность не только просматривать старые версии своего сайта, но и анализировать контент конкурентов, сохраненный в разные периоды времени.
Другие наши статьи
- Контент
Верстка и оформление статей на сайте

Вы можете написать интересный текст, придумать цепляющий заголовок, но если статью будет сложно читать, то вы рискуете потерять своих посетителей.
- Valeriy London
- 17 октября 2021
- 6 мин.
- Копирайтинг
Работаем с Текстовым Анализатором в Rush Analytics
Сегодня, когда контент играет все большую роль в продвижении сайтов, найти инструмент с помощью которого можно качественно оптимизировать текст под поисковые машины — цель каждого оптимизатора или seo-копирайтера.

- Дмитрий Цытрош
- 17 октября 2021
- 10 мин.
Получите 7 дней бесплатного доступа
Здесь вы можете собрать поисковые подсказки из Яндекс, Google или YouTube
история проекта, и том как использовать архив веб-страниц
Веб-архив сайтов (The Wayback Machine): история проекта, и том как использовать архив веб-страниц
Подробная информация о сервисе
История интернет архива, описание проекта, награды и блокировка

The Wayback Machine — это архив интернета (Internet Archive). По сути это некоммерческая организация, которая была основана в 1996 году. Задачей данной организации является сбор и хранение всевозможной публичной информации собранной из интернета: веб-страницы, электронные книги, фото- и, видео материалы. Основные сервера расположены в Сан-Франциско. Размер архива на февраль 2017 года составляет 13 петабайт и включает в себя 525 миллиардов копий веб-страниц.
Краткая история Archive.org
Основателем является Брюстер Кейл, который основал организацию в 1996 году. В том же оду начал процесс по архивации веб страниц. Проект назывался Wayback Machine. По сей день сохраненные копии доступны любому пользователю посетившему сайт.
Расширение организации в 1999 году, ознаменовалось хранением не только веб-страниц, но и видео, аудио, изображения и даже программное обеспечение.
Основные направления работы
Archive.org имеется два основных проекта
В интернете не существует аналогов данному проекту. База архива собиралась в общей сложности около 20 лет. При этом, можно смело заявить что проект является волантерским.
The Wayback Machine
Работает с 1996 года

Веб-сервис по сбору и хранению веб-страниц сайтов со всем их содержимым.
Фиксирует копии специальный робот. Результатом работы является возможность просмотра сайтов которых уже не существует, или не поддерживаются.
Open Library
Работает с 2005 года
Это общественный проект по сканированию всех книг в по всему миру. Проект имеет 13 центров оцифровки оцифровки книг в крупных библиотеках. Архив книг насчитывает более 1, миллионов книг, и коллекция постоянно растет.
Проблемы на законодательном уровне
На сервис не единожды подавались иски в суд за нарушение авторских прав. Поэтому по требованию правообладателей архив удаляет из публичного доступа соответствующие материалы.
Мануал: как пользоваться сайтом archive.org?

Открываем сайт по адресу — https://archive.
org. В поле сверху вводим доменное имя. Если сайт найден, то вы увидите в первом блоке выбор года и ниже месяцы и годы. Кликнув на определенную дату, Вам откроется сохраненная копия которую вы можете просмотреть перейдя по внутренним ссылкам.
Как найти нужный сайт и восстановить копию из веб-архива?
Чтобы скачать страницы сайта, Вам необходимо использовать специализированные сервисы или соответствующее программное обеспечение. В открытом доступе такого программного обеспечения нет. Мы предлагаем Вам воспользоваться услугами сервиса — WEBARCHIVEORG.RU.
Почему именно мы?
Восстановленный сайт будет работать на простом движке. По качеству нет аналогов. Неограниченное количество страниц за фиксированную цену. Адекватная служба поддержки.
Инструкция по настройке https, и редиректа www на нашей платформе

Как настроить редиректы http и www на восстановленном из веб-архива сайте? Подробнее об этом читайте. ..
Как установить счетчики, почистить и сделать замену участков кода?
Рассматриваем на примерах как самостоятельно отредактировать максимальное количество страниц с миним…
Руководство по установке сайта на ISPManager
Если на вашем хостинге установлена панель ISPManager, то данная инструкция поможет вам установить во…
Источник: socialvk.ru
Как выглядел сайт раньше?
Иногда хочется вспомнить те времена, когда по интернетам бродили динозавры, а одна песня загружалась 10 минут. Смотрим в прошлое и ностальгуем, спасибо за это онлайн-сервису: Wayback Machine – Internet Archive. Работает с 1996 года, за это время собрал в базе данных более 279 миллиардов веб-страниц.
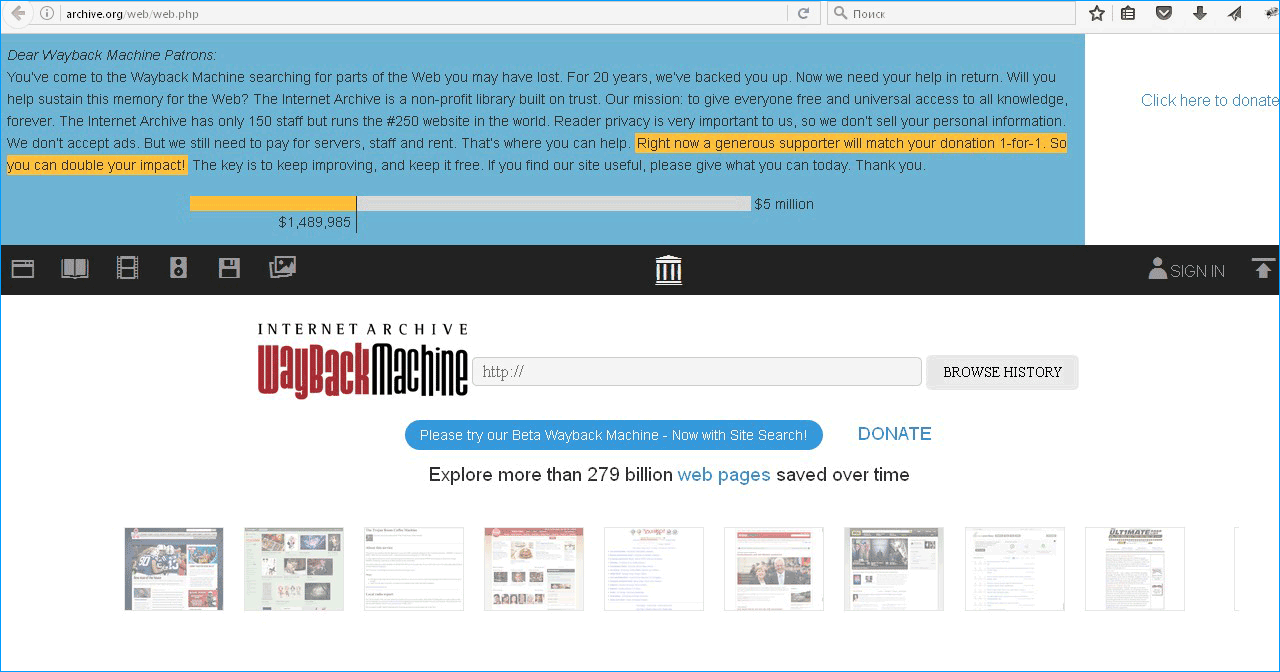
Переходим по ссылке: http://archive.org/web/web.php В строку вводим: адрес интересующего сайта и нажимаем «Browse History». Система выдаст всю историю по конкретному порталу.
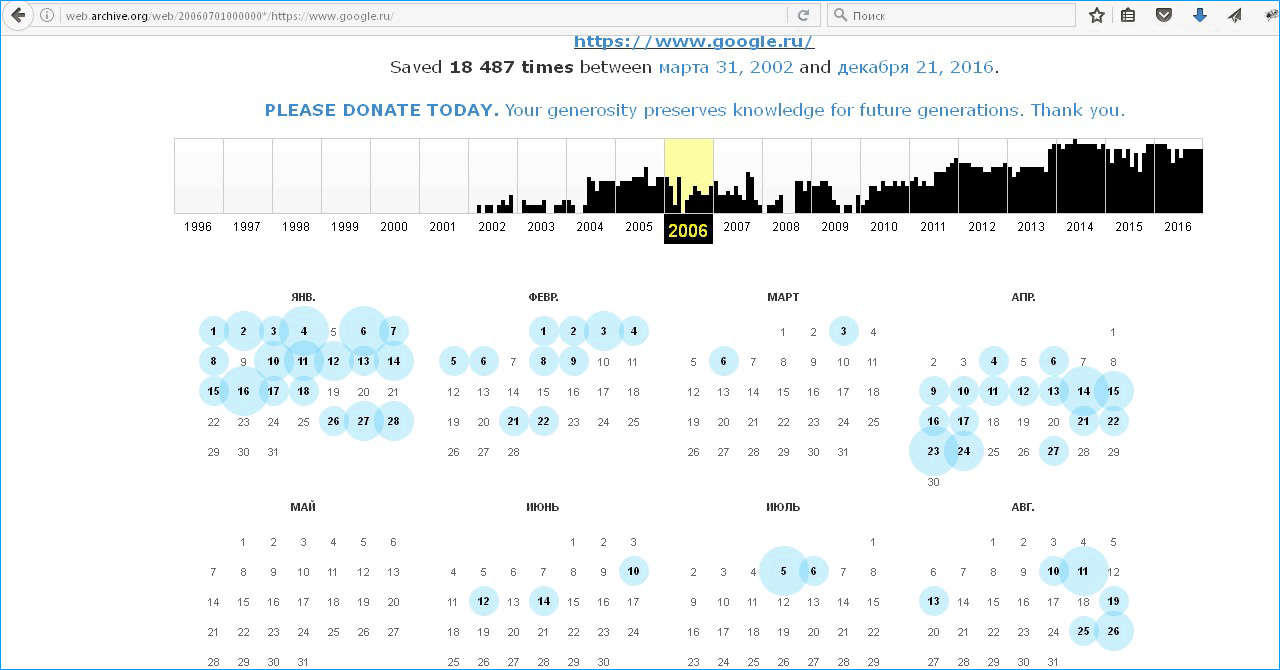
Синими кругами на календаре обведены даты резервных копий. Выбираем нужный год, дату и заглядываем в прошлое веб-страницы.
Где посмотреть, как выглядели страницы сайтов в разные годы
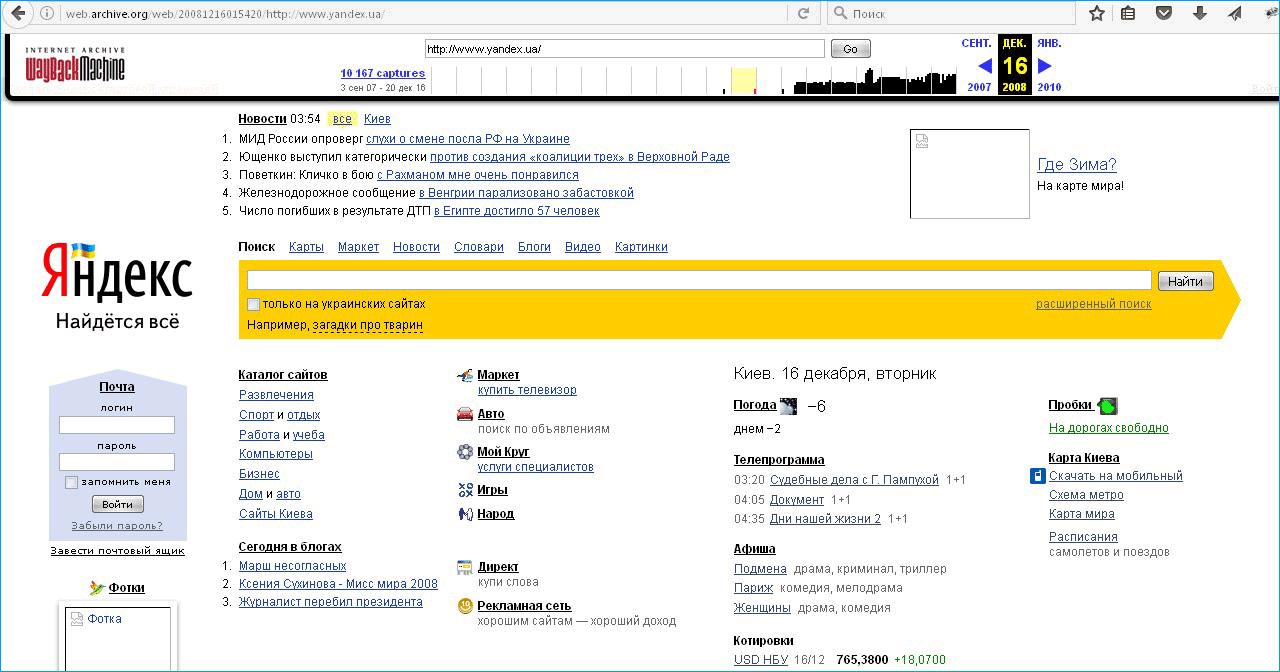
Яндекс в это время открыл первый удаленный офис в Питере, запустил Яндекс.пробки и «словари». А майл.ру начали использовать поисковик на своем портале. Через год Яндекс купит разработчика мобильного софта «Смартком» и соц. сеть «Мой круг». Запустит «Календари», блого-сервис Я.ру, портал Яндекс.Mirror и откроет школу анализа данных — бесплатный образовательный курс.
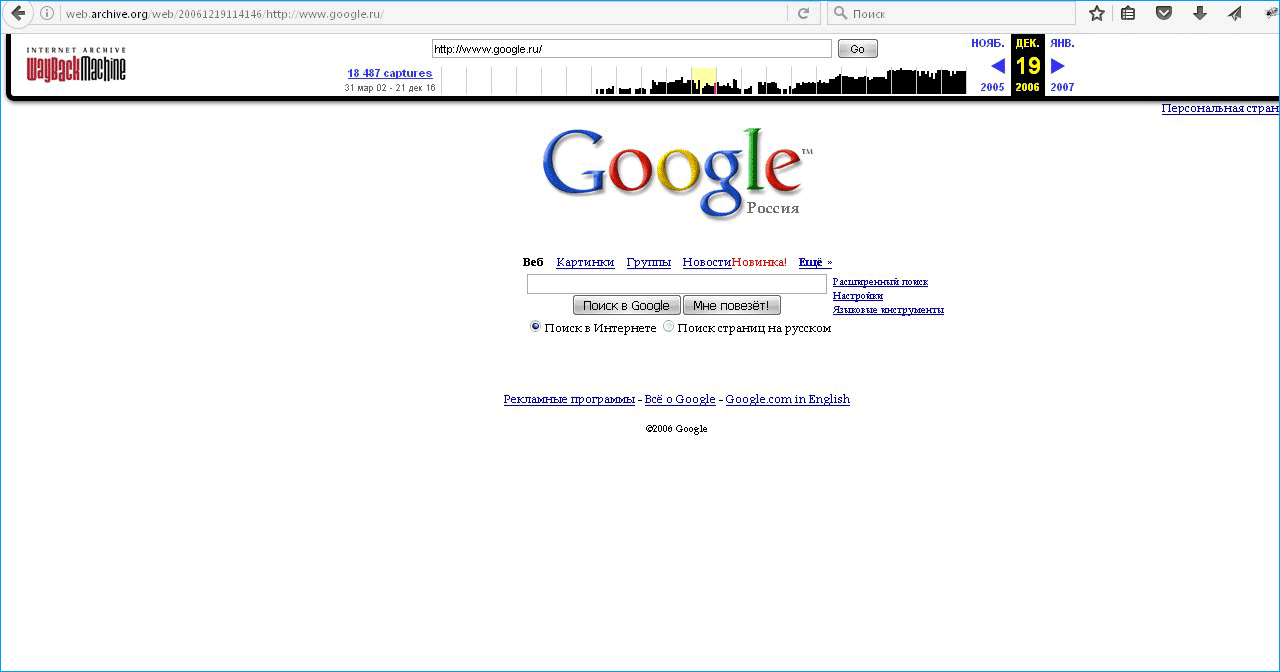
Google запускают календарь, финансы и переводчик. Открывают бесплатный хостинг изображений Picasa и объявляют о покупке YouTube. В 2007 компания установит крупнейшую систему солнечных батарей (Сейчас она обеспечивает энергией 30% офисов) и объявит о появлении Android. А сотрудники начинают ездить по офисам на велосипедах gBikes.
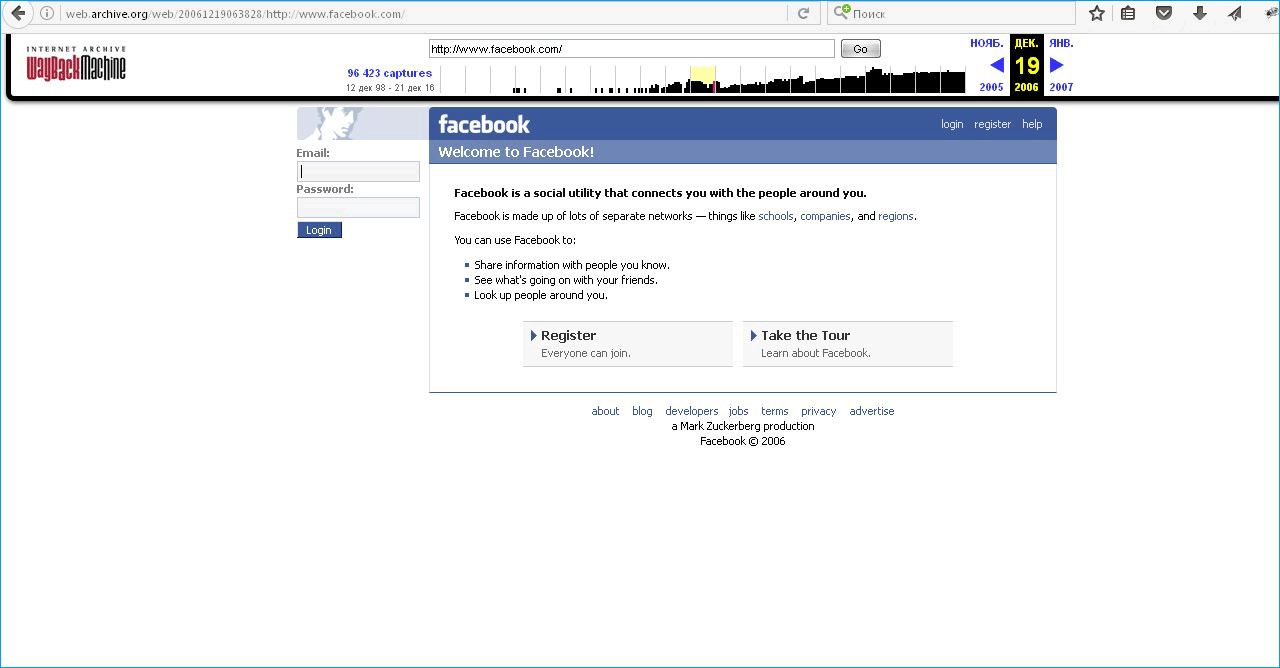
История Facebook уникальна. Только в 2004 году сервис вышел за стены Гарварда, а уже в 2008 вырос так, что количество пользователей перевалило за 50 млн. человек, а состояние Марка Цукерберга уже оценивалось в 1.5 млдр. долларов.
Как раньше выглядел наш сайт
А вот так менялся наш сайт с 2006 года:

iPipe – надёжный хостинг-провайдер с опытом работы более 15 лет.
- Виртуальные серверы с NVMe SSD дисками от 299 руб/мес
- Безлимитный хостинг на SSD дисках от 142 руб/мес
- Выделенные серверы в наличии и под заказ
- Регистрацию доменов в более 350 зонах
Источник: ipipe.ru