Добрый день, давно я ничего не писал — много было причин. За это время накопилось достаточно большое количество материала и я постараюсь его сюда выставить как можно полнее. Сегодня я хочу рассказать о работе с API контакта через Python, а примером послужит — скачивание стены журнала Евгений Онегин. Глава 11. Если вам лень читать как я всё это делал, а охота поскорее скачать свою стену, переходите сразу к разделу «Отчёт и тестирование».
Подготовка
Первое, что нужно сделать — скачать АПИ и зарегистрировать приложение, получив его идентификатор ( если вам не охота регистрировать своё приложения и получать его идентификатор, то просто пропустите этот шаг — по умолчанию программа подставит мой идентификатор приложения) . АПИ доступно по этому адресу https://pypi.python.org/pypi/vkontakte .Там есть инструкция по установке. Если-же не получается по ней, то скачайте файлы, разархивируйте, в терминале выполните (Linux)
После установки мы можем пользоваться функционалом этой библиотеки, однако с некоторых пор стало обязательным создание окна браузера, чтоб пользователь там ввёл свои логин и пароль, и только потом мы получили token_id для работы с API питона. Чтоб не лезть в эти дебри можно прикинуться окном броузера, фиктивно ввести туда валидные логин и пароль и получить свой законный токен.
Разбираем стену ВК по кирпичикам в Python / СММ Хаб
В этой статье рассказано более подробно про этот маленький хак. В результате статьи был создан класс авторизации, в который сообщается логин, пароль, идентификатор приложения, запрашиваемые права. Я немного подредактировал этот файл, так как он не работал. Скачать мой вариант можно тут.
Первые шаги
Для первого примера давайте сделаем простую авторизацию с неким запросом.
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import vk_auth import vkontakte def main(): (token,user_id) = vk_auth.auth(‘$EMAIL’, ‘$PASSWD’, ‘$ID_APP’, ‘$SOPE’) vk = vkontakte.API(token=token) print «Hello vk API , server time is «,vk.getServerTime() return 0 if __name__ == ‘__main__’: main()
Ничего сложного — импортируем класс авторизации, импортируем библиотеку c API, получаем токен и идентификатор, используем АПИ-шные функции.
Пример
Теперь пришло время к массивному, серьёзному, а главное практичному примеру — скачивание стены Вконтакте. Идея скачивания стены зародилась из острой необходимости. Паблик Вконтакте организован очень удобно, за одним исключением — старую информацию на стене невозможно найти. Родилась идея — скачать всю стену из паблика и разбить её на несколько HTML фалов для лучшей скорости доступа.
Перед началом работы нужно поставить грамотное техническое задание.
Техническое задание
- Имя пользователя
- Пароль
- Идентификатор группыпабликастраницы
- Количество постов для скачивания
- Начиная с какого сообщения скачивать
- На сколько HTML блоков разбивать
Реализация
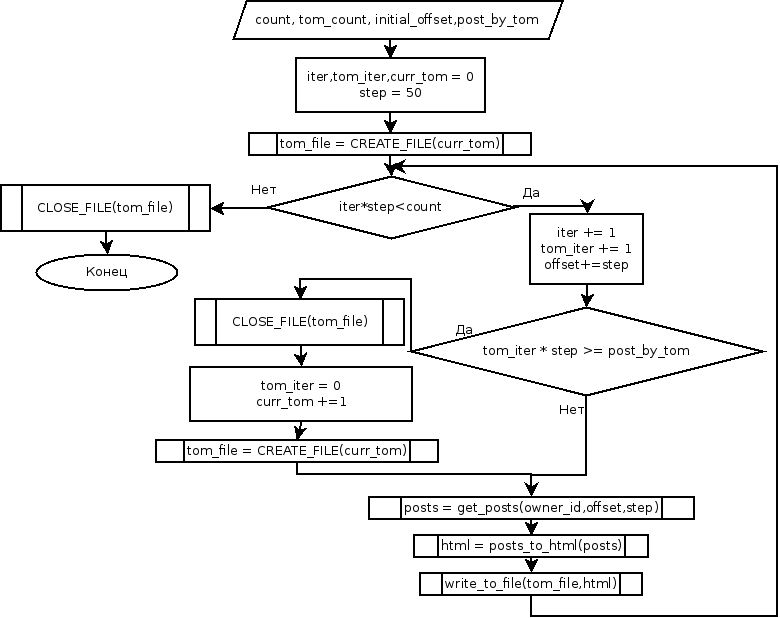 |
| Обобщённый алгоритм работы программы |
Wall.post для VK Пример как сделать пост в сообщество группу через Python
Определимся с каркасом программы и входящими параметрами.
Набросаем пока такой код. Я использовал библиотеку OptionParser для парсинга параметров — она идёт из коробки и о-о-очень удобная. Следующий шаг — организация разбивки на тома. Чуть изменив старый код, мы получаем алгоритм, который разобьёт информацию на необходимое количество томов. Вот код. Далее необходимо использовать vk API и загружать посты из Контакта. Покурив документацию, я быстро нашел необходимую функцию . Апи контакта позволяет отправлять JSON запросы и получать JSON ответы. Используемой нами vkAPI инкапсулирует JSON запросы в список переменных. Не могу сказать, что это очень удобно, но я не нашел другого способа. Для запроса постов со стены определённой группы нам необходимо выполнить следующий код
posts = vk.get(‘wall.get’, owner_id=owner_id,offset=offset,count=count)
После выполнения этого кода в posts запишется count постов со смещением offset. Стоит обратить внимание, что на количество скачиваемых постов есть ограничение и, если я не ошибаюсь, оно равно 100. Я взял значение 50, как оптимальное количество скачиваемых постов за 1 итерацию цикла.
В прошлом листинге я выделил 2 функции: скачивание постов get_posts() и форматирование в HTML posts_to_html(), и поставил на них заглушки. Теперь я заполняю get_posts() кодом, который привёл выше. В техническом задании ещё требовалось скачать все комментарии к коду. Я разделил функцию скачивания постов и оформления их в html, а значит скачивание комментариев должно производиться вместе со скачиванием постов и записываться в одну переменную. Благо, JSON — формат динамический и его несложно дополнить одним полем, в котором будут храниться комментарии.
В документации находим функцию скачивания комментариев и реализуем. Функцию скачивания поста с комментариями разобьём на 2 функции — скачивание поста и скачивание комментариев к нему. Получаем вот такой код:
def get_comments(vk,owner_id,post_id,count): size = 50 comments = [] if(count0): post_id = posts[i][‘id’] comments = get_comments(vk,owner_id,post_id,coments_count) posts[i][‘comments’][‘data’]=comments print len(comments),coments_count return posts
Теперь функция get_posts вернёт посты, в которых в поле comments.data будут храниться комментарии к ним.
На этом работа со скачиванием данных закончена.Необходимо ещё из этой всей канители сформировать красивые HTML странички. Скажу честно — для меня это самый адский труд. Но других путей нет — вперёд.
Формирование HTML страниц.
Для формирования я написал целый ряд шаблонов, в которые потом буду вставлять данные из JSON. Я не буду их всех здесь приводить. Просто дам ссылку на готовый проект. Функция, формирования HTML вышла огромная и некрасивая.Если будут люди — профи в HTML, буду им благодарен за более благоприятный дизайн, который более схож с Vk.
Скачивание Данных.
Одним из пунктов ТЗ был удобный локальный просмотр. В данный момент все ссылки на картинки и аудиозаписи — абсолютные (то есть ведут в интернет) а нужно чтоб они лежали рядом и при отсутствии интернета можно было и картинку посмотреть и музычку прослушать. Можно это сделать питоном через жуткую Караганду. Но я предпочёл вариант поэлегантней — wget. Эта стандартная линуксовская интрнето-качалка и она умеет скачивать web-страницу с информацией на ней.Чтобы скормить HTML-ки нужно ещё почитать man wget и найти несколько необходимых ключей.
Получился вот такой скрипт:
$wget -B -k -r -l0 —force-html -i name-*.html -P ./data
Одно только НО — wget скачает всю информацию, но не преобразует ссылки.Может, конечно, он это и умеет делать, но я не нашел как. Поэтому в питоне мы напишем преобразование от любого контактовского адреса хранения фотоаудио в ссылку на рядом лежащую папку _data. Я умышленно разделил имя группы и номер тома, чтобы можно было переместить за собой только один том и не тащить за собой несчётное количество информации, которая не используется.
def convert_lincs(txt,folder,recurce = 0): out = re.sub(«http://»,folder,txt) return out
Как видите, благодаря мощи регулярных выражений эту задачу мы решили в 1 строку.
Ещё я столкнулся с проблемой постоянно прерывающийся связи (у меня плохой интернет) и отказа со стороны Контакта из-за высокой частоты запросов. Эти 2 фактора периодически валили программу, поэтому я сделал отказоустойчивые обёртки для всех методов обращения в интернет, которые использовал. Получилось вот так:
def wall_getComments(vk,owner_id,post_id,count,recurce = 0): if (recurce ==20): return [] try: com = vk.get(‘wall.getComments’, owner_id=owner_id,post_id=post_id,count=count) except: time.sleep(1) print «Error wall_getComments try «,recurce com = wall_getComments(vk,owner_id,post_id,count,recurce = recurce+1) return com def wall_get(vk,owner_id,offset,count,recurce = 0): if (recurce ==20): return [] try: res = vk.get(‘wall.get’, owner_id=owner_id,offset=offset,count=count) except: time.sleep(1) print «Error wall_get try «,recurce res = wall_get(vk,owner_id,offset,count,recurce = recurce +1) return res def users_get(vk,uids,fields,recurce = 0): if (recurce ==20): return [] try: res = vk.get(‘users.get’,uids=uids,fields=»photo») except: time.sleep(1) print «Error users_get try «,recurce res = users_get(vk,uids,fields,recurce = recurce +1) return res def groups_getById(vk,group_ids,recurce = 0): if (recurce ==20): return [] try: res = vk.get(‘groups.getById’, group_ids=group_ids) except: time.sleep(1) print «Error groups_getById try «,recurce res = groups_getById(vk,group_ids,recurce = recurce +1) return res
При отказе сети или ошибке получения данных я жду полсекунды и повторяю попытку.
Отчёт и тестирование
Результат работы я публикую на Github. Так , что вы можете присоединиться к проекту, взять мои наработки, добавить свои, переделать под свои нужды и просто развивать проект.
И вот, наконец, тестирование. Обратите внимание на то, что я буду использовать Python2.X и не ругайтесь заранее, увидев что-то вроде этого при попытке запустить программу:
- -e EMAIL, —email=EMAIL Имеил для авторизации
- -p PASSWD, —passwd=PASSWD Пароль для авторизации, если вы его не задали в явном виде, программа попросит вас ввести его вовремя выполнения.Конечно пароль будет невидим.
- -i GID, —groupid=GID Идентификатор группы, стену которой необходимо скачать
- -c COUNT, —count=COUNT — количество постов, которые необходимо скачать. Если не задано — выкачивает все записи со стены.
- -f OFFSET, —offset=OFFSET — смещение, с которого необходимо начать скачивание, если не задано , то 0.
- -s SPLIT_NUM, —split=SPLIT_NUM — количество блоков, на которые разбить скачанные посты, если не задано, то 1
- -a APP_ID, —app_id=APP_ID — идентификатор приложения, которое вы получили зарегестрировавшись ( если не указано, то используется мой идентификатор приложения)
- -d DOWNLOAD, —download_all=DOWNLOAD — ключ, который определяет, следует ли загружать мультимедиа. Возможные значения:
- 0 — Не загружать ( по умолчанию)
- 1 — загружать после того, как основная информация загрузится
Типичный пример использования:
python2 ./WallCopy.py -e EMAIL -i GROUP_ID
При этом загрузятся все записи со стены с нулевым смещением, но ссылки останутся абсолютными. Пароль программа спросит в интерактивном режиме, а остальные опции примут значения по умолчанию.
Расширенный пример использования:
python2 ./WallCopy.py -e EMAIL -p PASSWORD -i GROUP_ID -c 1000 -f 500 -s 8 -a APP_ID -d 1
При этом загрузится 1000 постов со смещением на 500 и разобьётся на 8 томов, и картинки с музыкой загрузятся на компьютер.
- Загрузка только фото и игнорирование музыки;
- Загрузка документов;
- Загрузка репостов;
- Более похожий дизайн на Vk;
- Превью Видео;
- Требование Linux ( wget )
- Поддержка только Python 2.X
- Использование ООП
Источник: alexkutsan.blogspot.com
VK API Python
Для взаимодействия с api сайта vk.com на питоне есть готовые библиотеки (например), но иногда нужно использовать всего несколько методов для получения информации и не хочется добавлять дополнительные зависимости к своему скрипту. Реализовать это достаточно просто.
Получение токена
Прежде всего нужно ознакомиться с документацией. Для обращения к методам api нужен токен (подробнее). В данном примере я буду использовать сервисный ключ доступа. Для его получения нужно создать своё приложение на странице https://vk.com/apps?act=manage. Переходите по этой ссылке, жмёте кнопку «Создать», придумываете любое название и выбираете «Standalone-приложение«.
Больше ничего настраивать не нужно в рамках этого примера, но ради интереса можете посмотреть, что там есть ещё. После этого заходите в настройки созданного приложения и копируете «Сервисный ключ доступа». Это и есть токен, который нужен для выполнения запросов к api. Теперь можно переходить к написанию кода.
Написание кода
Так как я отказался от использования внешних библиотек, то в этом примере я буду использовать только те модули, которые идут в составе питона.
import json from urllib.parse import urlencode from urllib.request import urlopen
Ответ на запрос к api возвращается в формате json (подробнее). Для обращения к методам api напишем несколько вспомогательных функций.
import json from urllib.parse import urlencode from urllib.request import urlopen api_ver = ‘5.131’ api_url = ‘https://api.vk.com/method/’ api_token = ‘Сервисный ключ доступа’ def make_url(method, args): return f’?’ f’v=’ def request(method, args): url = make_url(method, args) response = <> try: response = json.loads(urlopen(url).read()) except Exception as e: print(e) if ‘error’ in response: print(response[‘error’][‘error_msg’]) response = None return response
Метод make_url вспомогательный. Он возвращает url запроса, который формируется из имени метода, его параметров, а так же токена и версии api. Метод request выполняет GET запрос к api и возвращает результат в виде словаря.
Теперь нужно обратиться к списку методов, который нам предоставляет api. Например, хочется получить список подписчиков сообщества (их пол, дату рождения и время, когда они последний раз заходили во вконтакте), чтобы проанализировать аудиторию. Для этого понадобится метод groups.getMembers. На этой странице указана подробная информация о том, какие параметры вызова этого метода, в каком виде возвращается результат, а так же пример запроса, чтобы было более наглядно. Допишем к нашему скрипту этот метод:
def groups_get_members(group_id, offset=0, count=1000): response = request(‘groups.getMembers’, ) if response: result = [] for user in response[‘response’][‘items’]: result.append([user.get(‘id’), user.get(‘sex’), user.get(‘bdate’), user.get(‘last_seen’, <>).get(‘time’)]) return result
И вызовем этот метод, для получения информации о десяти подписчиках. Весь код получается таким:
import json from urllib.parse import urlencode from urllib.request import urlopen api_ver = ‘5.131’ api_url = ‘https://api.vk.com/method/’ api_token = ‘Сервисный ключ доступа’ def make_url(method, args): return f’?’ f’v=’ def request(method, args): url = make_url(method, args) response = <> try: response = json.loads(urlopen(url).read()) except Exception as e: print(e) if ‘error’ in response: print(response[‘error’][‘error_msg’]) response = None return response def groups_get_members(group_id, offset=0, count=1000): response = request(‘groups.getMembers’, ) if response: result = [] for user in response[‘response’][‘items’]: result.append([user.get(‘id’), user.get(‘sex’), user.get(‘bdate’), user.get(‘last_seen’, <>).get(‘time’)]) return result members = groups_get_members(‘apiclub’, 0, 10) print(members)
В консоль выведется список списков с необходимой информацией. Таким же образом, можно реализовать и другие методы, а затем засунуть их в класс для удобства. На этом всё.
Источник: lepeshka.wordpress.com
Загрузка данных сообществ Вконтакте посредством языка Python

Довольно часто о проблемах в той или иной сфере работы организации можно узнать на основании отзывов как клиентов и пользователей, так и самих сотрудников. Когда все сайты с отзывами и рекомендациями уже проверены, но информации все равно критически не хватает, возникает вопрос: «Что дальше? Какие еще источники информации использовать?». Решение есть – использовать информацию из популярных сообществ в социальных сетях! Сегодня более подробно остановимся на разработке приложения, позволяющего производить сбор по информации о постах и комментариях к ним в такой популярной социальной сети как «Вконтакте».
Для начала определимся со структурой, предоставляемой сообществами информации. Каждое сообщество имеет свой уникальный id (Как узнать id сообщества можно почитать в официальном FAQ: https://vk.com/faq18062.) Для каждого размещенного поста установлен свой id, также, как и в случае с комментариями к ним. Тип связи между таблицами будет «один ко многим». В данном типе связей несколько строк из дочерней таблицы (в нашем случае комментарии к публикациям) зависят от одной строки в родительской таблице (публикация). Представим структуру будущих таблиц с необходимыми нам данными в виде UML диаграммы:
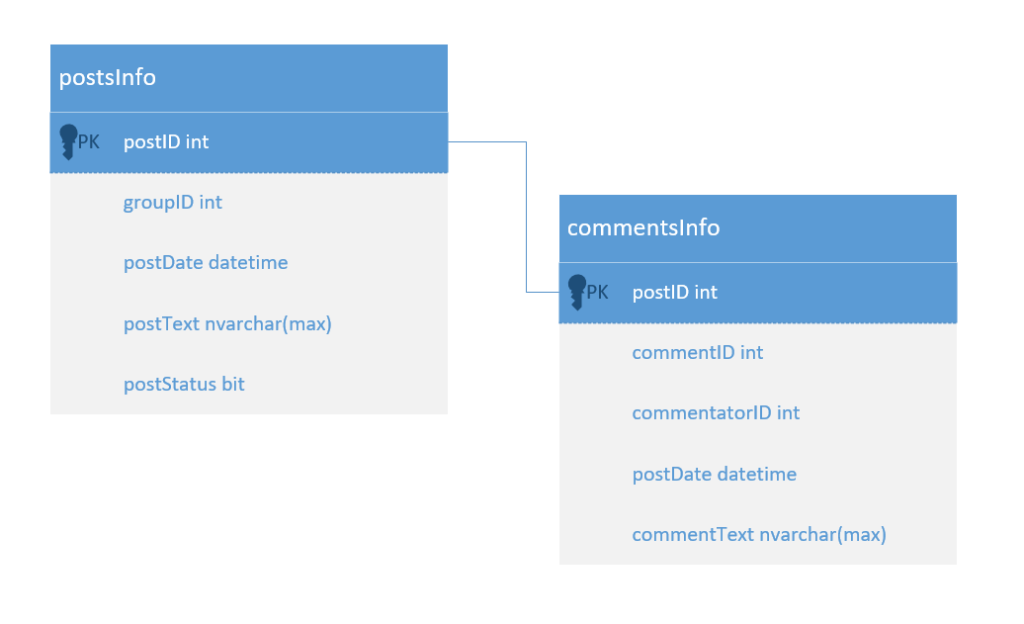
postsInfo – таблица, хранящая информацию о публикациях сообществ
postID – id публикации в сообществе
groupID – id сообщества
postDate – дата размещения публикации
postText – текст публикации
postStatus – статус обработки публикации
commentsInfo – таблица, хранящая информацию о комментариях к публикациям сообществ
commentID – id комментариях к публикации
commentatorID – id пользователя, оставившего комментарий
postDate – дата размещения комментария
commentText – текст комментария к публикации
Многих может заинтересовать вопрос: «Для чего предназначено поле postStatus?». Данное поле было добавлено в ходе программной реализации, с целью отслеживания статуса обработки информации по публикациям, а также во избежание потери информации при возникновении исключений (при возникновении ошибки необходимо только перезапустить код и он продолжит обработку данных с момента «падения»)
После определения схемы хранения данных, приступим к программной реализации.
Импортируем необходимые для работы библиотеки:
import requests from datetime import datetime as dt import pyodbc import os import time import re
Для отправки http-запросов к vk api будет использоваться библиотека requests, а запись полученных результатов будет осуществляться в базу данных посредством библиотеки pyodbc.
После импорта необходимых библиотек реализуем класс для обработки и записи получаемой информации в базу данных:
class DbClient: def __init__(self,connectionString): self.connectionString = connectionString def createDb(self,conStrForCreateDb): try: # проверка на наличие директории для хранения базы данных if not os.path.exists(«C:Databases»): os.mkdir(«C:Databases») # создание директории в случае ее отсутствия #создание подключения к БД connection = pyodbc.connect(conStrForCreateDb,autocommit=True) createDbRequest = «»»CREATE DATABASE YOUR_DATABASE_NAME ON PRIMARY (NAME=N’ YOUR_DATABASE_NAME ‘,FILENAME=N’C:\Databases\ YOUR_DATABASE_NAME.mdf’) LOG ON (NAME=N’ YOUR_DATABASE_NAME _log’,FILENAME=N’C:\Databases\ YOUR_DATABASE_NAME _log.ldf’)»»» # создание объекта- курсора, посредством которого будут производиться запросы к таблицам dbCursor = connection.cursor() # выполнение скрипта на создание БД dbCursor.execute(createDbRequest) connection.commit() connection.close() print(«Database creation completed. «) except Exception as error: print(«Method failed with error:» + str(error)) def createTables(self): createTablesRequests = [«»»CREATE TABLE postsInfo(groupID int,postID int,postDate datetime,postText nvarchar(max),postStatus bit)»»», «»»CREATE TABLE commentsInfo(commentId int,commentatorId int,postID int,postDate datetime,commentText nvarchar(MAX),userStatus bit,textStatus bit)»»»] # итеративное прохождение списка sql-запросов и их выполнение для создания необходимых таблиц for request in createTablesRequests: connection = pyodbc.connect(self.connectionString) dbCursor = connection.cursor() dbCursor.execute(request) connection.commit() connection.close() print(«Creation of work tables is completed. «) def insertDataInPostInfo(self,postID,postDate,postText,groupID): try: sqlString = «»»IF NOT EXISTS(SELECT * FROM postsInfo WHERE postID=?) INSERT INTO postsInfo (groupID,postID,postDate,postText,postStatus) VALUES (. 0)»»» connection = pyodbc.connect(self.connectionString) dbCursor = connection.cursor() dbCursor.execute(sqlString,postID,groupID,postID,postDate,re.sub(‘n’,’ ‘,postText)) connection.commit() connection.close() except Exception as error: print(error) def insertDataInCommentsInfo(self,commentId,commentatorId,postID,postDate,commentText): try: sqlString = «»»IF NOT EXISTS(SELECT * FROM commentsInfo WHERE commentId=?) INSERT INTO commentsInfo (commentId,commentatorId,postID,postDate,commentText,userStatus,textStatus) VALUES(. 0,0)»»» connection = pyodbc.connect(connectionString) dbCursor = connection.cursor() dbCursor.execute(sqlString, commentId,commentId,commentatorId,postID,postDate,re.sub(‘n’,’ ‘,commentText)) connection.commit() connection.close() except Exception as error: print(«Error in insertDataInCommentsInfo » +str(error)) def updatePostInfo(self, postID): # запрос на изменение статуса публикации после выгрузки комментариев к нему sqlString = «»»update postsInfo set postStatus=1 where postID=?»»» connection = pyodbc.connect(connectionString) dbCursor = connection.cursor() dbCursor.execute(sqlString,postID) connection.commit() connection.close()
При инициализации объекта класса DbClient в конструктор будет передана строка подключения к нашей базе. Данный класс содержит следующие методы:
createDb – служит для создания базы данных
createTables – создаёт необходимые для записи таблицы
insertDataInPostInfo – производит запись информации о публикации
insertDataInCommentsInfo – производит запись комментариев к публикации и информации о них
updatePostInfo – обновляет статус обработки данных публикации
Когда вопрос с записью и хранением данных закрыт, можно приступить к непосредственной разработке методов по их сбору.
class Vk: def __init__(self,token,connectionString): self.token = token self.connectionString = connectionString self.db = DbClient(connectionString) #создание экземпляра класса для работы с БД def searchPosts(self,groupId): offset= 0 # начальный индекс поиска публикаций count= 95 #шаг продвижения индекса поиска публикаций try: for _ in range(0,4): #формирование списка параметров запроса к api params = #отправка запроса с заданными параметрами r = requests.get(‘https://api.vk.com/method/wall.get’,params) for j in range(0,count): #запись получаемых данных в таблицу self.db.insertDataInPostInfo(r.json()[‘response’][‘items’][j][‘id’], dt.fromtimestamp(r.json()[‘response’][‘items’][j][‘date’]).strftime(‘%Y%m%d %H:%M:%S’),r.json()[‘response’][‘items’][j][‘text’],groupId) offset += count # наращивание шага продвижения по публикациям # принудительная «остановка» работы программы, для соблюдения требований api по количеству запрсов time.sleep(2) except Exception as error: print(error) def searchComments(self,groupId): groupId = int(groupId) # поиск публикаций, к которым еще не произведен поиск комментариев sqlString = «»»select postID from postsInfo where groupID=? and postStatus=0″»» connection = pyodbc.connect(self.connectionString) dbCursor = connection.cursor() dbCursor.execute(sqlString,groupId) for row in dbCursor: self.searchPostComments(groupId,row.postID,self.token) self.db.updatePostInfo(row.postID) connection.commit() connection.close() time.sleep(2) def searchPostComments(self,groupId,postID,userToken): params = r2 = requests.get(‘https://api.vk.com/method/wall.getComments’,params) commentsCount = int(r2.json()[‘response’][‘count’]) for i in range(0,commentsCount): try: countThreads = int(r2.json()[‘response’][‘items’][i][‘thread’][‘count’]) commentId = int(r2.json()[‘response’][‘items’][i][‘id’]) if countThreads !=0: self.db.insertDataInCommentsInfo(int(r2.json()[‘response’][‘items’][i][‘id’]), int(r2.json()[‘response’][‘items’][i][‘from_id’]), int(postID), dt.fromtimestamp(r2.json()[‘response’][‘items’][i][‘date’]).strftime(‘%Y%m%d %H:%M:%S’), str(r2.json()[‘response’][‘items’][i][‘text’])) self.writeThreadsComments(groupId,postID,commentId,userToken) else: self.db.insertDataInCommentsInfo(int(r2.json()[‘response’][‘items’][i][‘id’]), int(r2.json()[‘response’][‘items’][i][‘from_id’]), int(postID), dt.fromtimestamp(r2.json()[‘response’][‘items’][i][‘date’]).strftime(‘%Y%m%d %H:%M:%S’), str(r2.json()[‘response’][‘items’][i][‘text’])) except Exception as error: print(«Error in searchComments»+str(error)) continue time.sleep(2) def writeThreadsComments(self,groupId,postId,commentId,userToken): params = r = requests.get(‘https://api.vk.com/method/wall.getComments’,params) commentsCount = int(r.json()[‘response’][‘count’]) for i in range(0,commentsCount): try: self.db.insertDataInCommentsInfo(int(r.json()[‘response’][‘items’][i][‘id’]),int(r.json()[‘response’][‘items’][i][‘from_id’]),int(postId),dt.fromtimestamp(r.json()[‘response’][‘items’][i][‘date’]).strftime(‘%Y%m%d %H:%M:%S’),str(r.json()[‘response’][‘items’][i][‘text’])) except Exception as error: print(«Error in writeThreadsComments.»+str(error)) continue time.sleep(2)
searchPosts — производит поиск публикаций для заданного сообщества
searchComments – производит поиск еще необработанных публикаций, для которых необходимо произвести поиск комментариев
searchPostComments, writeThreadsComments – методы для поиска и записи комментариев к публикациям.
Для более удобной манипуляции с разработанными методами создадим небольшое консольное меню, реализовав класс Main
class Main: def __init__(self,groupId,token,conStrForCreate,connectionString): self.id = groupId self.token = token self.conStrForCreate = conStrForCreate self.connectionString = connectionString self.db1 = DbClient(conStrForCreate) self.db2 = DbClient(connectionString) self.vk = Vk(token,connectionString) def menu(self): p = [‘1-Создать базу данных для работы’,’2-Создать необходимые таблицы’, ‘3-Произвести поиск постов (searchPosts)’,’4-Поиск комментариев к постам’] print(‘Выберите необходимое действие:nnnnn’.format(p[0],p[1],p[2],p[3])) choice = str(input()) if choice==»createDb» or choice==»1″: self.db1.createDb(self.conStrForCreate) if choice==»createTables» or choice==»2″: self.db2.createTables() if choice==»searchPosts» or choice==»3″: self.vk.searchPosts(self.id) if choice==»searchComments» or choice==»4″: self.vk.searchComments(self.id) После создания всех необходимых if __name__==»__main__»: token = ‘YOUR_VK_API_TOKEN’ conStrForCreate = «Driver=;Server=DESKTOP-R9VI2A2SQLEXPRESS;Database=master;Trusted_Connection=yes;»#строка подключения для создания новой БД для работы connectionString = «Driver=;Server=DESKTOP-PSQLEXPRESS;Database=YOUR_BD_NAME;Trusted_Connection=yes;»#строка подключения к используемой БД m = Main(id,token,conStrForCreate,connectionString) while(True): m.menu()
В результате запуска получаем окно:

Результатом запуска программы являются созданные таблицы со списком публикаций и комментариев к ним:
Источник: newtechaudit.ru