С 1 января 2016 года вступил в силу так называемый закон «о забвении». Согласно этому закону, российские поисковые системы по обращениям граждан должны «забывать» ссылки на страницы, содержащие недостоверную информацию о них. Банки.ру вспомнил, с чего все началось и какими проблемами уже обернулось.
ЕС против Google
Вопрос об актуальности данных в поисковых системах всплыл относительно недавно – в 2009 году. Испанец Марио Костеха Гонсалес обнаружил, что с помощью поисковой системы Google на сайте одной из газет можно найти объявление 1998 года об аресте его имущества за долги.
Гражданин потребовал удалить информацию как устаревшую, однако газета отказалась это делать, сославшись на то, что публикация была сделана Министерством труда и социальной защиты. Тогда испанец обратился с аналогичной просьбой к поисковому оператору. Который тоже отказал в удовлетворении просьбы.
В 2010 году Костеха Гонсалес обращается в испанское ведомство по защите персональных данных (Agencia Española de Protección de Datos, AEPD), которое, рассмотрев дело, отказывает в претензии к газете, но полностью удовлетворяет жалобу к Google. Спустя год испанский суд передает на рассмотрение Европейского суда дело, в котором объединено около 180 подобных разбирательств. В результате суд ЕС расценил, что обработка информации в Интернете поисковыми системами может затрагивать персональные данные, что означает о необходимости контроля этого процесса. Это разбирательство послужило толчком к разработке акта о защите персональных данных, принятого в 2014 году, благодаря которому за гражданами закреплялось право требовать от поисковых систем удаления ссылок на ресурсы, содержащие недостоверную информацию.
Страница «Ничего не найдено». Куда направить посетителя со страницы нулевого результата поиска
Эхо в Москве
Спустя какое-то время о праве «на забвение» заговорили и российские законодатели. Тем более что им самим, как и многим российским бизнесменам, точно есть что скрывать и не дать вспомнить своим оппонентам.
За дело взялись довольно активно: с момента возникновения самой идеи до принятия поправок к закону «Об информации, информационных технологиях и о защите информации» прошло чуть менее года. Скорость, с которой принимались решения, чуть было не привела к плачевным результатам для всей отрасли: в первой версии закона «о забвении» определение поисковой системы было слишком размыто, и под его действие чуть было не попали все сайты в Интернете, на которых имеется строка поиска. Об этом напомнил директор Российской ассоциации электронных коммуникаций (РАЭК) Сергей Плуготаренко на Cyber Security Forum 2016. По его словам, если бы до законодателей не удалось донести мнение круга компаний, работу которых так или иначе затрагивает законопроект, под действие закона «о забвении» могли бы попасть даже внутрикорпоративные системы поиска. Несмотря на попытки РАЭК отсрочить дату вступления закона в действие как минимум на год, чтобы дать операторам поиска адаптироваться к новым условиям, изменения вступили в силу с начала 2016 года.
Почему ваше видео НЕ в топе поиска YouTube?
Что можно удалить
Воспользоваться «правом на забвение» можно, лишь если заявитель является гражданином РФ, ссылки на информацию доступны только пользователям российского сегмента Сети, а сами данные содержат неактуальную, недостоверную или утратившую (для заявителя) значение информацию. При этом удалению не подлежат ссылки на информацию о преступлениях или данных о непогашенной судимости.
Срок рассмотрения жалобы поисковым оператором не должен превышать десять дней. Главной проблемой реализации закона является то, что проверкой достоверности фактов, перечисленных в обращении граждан, вынуждены заниматься сами поисковики.
По каждому обращению компания должна своими силами проводить небольшое расследование, чтобы установить законность требований пользователя. Для этого поисковая система вправе запросить такую информацию, как паспортные данные заявителя, и документы, подтверждающие неправомерность конкретных сведений.
Учитывая относительно небольшой срок, отводящийся на рассмотрение жалобы, нагрузка на этапе «проверить обоснованность жалобы» может быть довольно серьезной. «Было бы очень комфортно, чтобы все первоначальные запросы получал Роскомнадзор, разбирался бы в их адекватности и взаимодействовал с пользователями, задавал им вопросы уточняющего плана […] и уже после проведения первоначального расследования, отправлял (запрос. – Прим. ред.) в поисковые системы», — сказал Плуготаренко. Сами компании, предоставляющие услуги поиска, не слишком охотно комментируют последствия вступления в силу закона «о забвении». К примеру, в пресс-службе «Яндекса» порталу Банки.ру сообщили, что «пока недостаточно статистики для обобщения ситуации. …Обращения об удалении ссылок рассматривает наша служба поддержки совместно с юристами компании, на разбор каждого заявления новый закон отводит десять рабочих дней. По результатам рассмотрения ответ будет направлен на электронный адрес, который указал пользователь в своем обращении». Похожими ответами ограничиваются и другие игроки рынка.
Не все поисковые системы – поисковики
Учитывая новизну закона, большинство пользователей Сети пока еще не очень понимают, каким конкретно критериям должна соответствовать информация для изъятия ее из поисковой выдачи. Кроме этого, мало кто знает, что не каждая поисковая система является поисковиком. К примеру, Rambler использует поисковую технологию «Яндекс».
Так что найти на страницах ресурса форму для подачи жалобы не получится. Еще один непонятный момент в этой истории – зарубежные поисковые системы, не имеющие представительства в России и получающие, благодаря поправкам, преимущества перед отечественными поисковиками. Механизмов, позволяющих добиться от них удаления ссылок, нет. По мнению экспертов, таким образом, эти ресурсы получили благодаря закону преимущества перед отечественными системами.
Будет ли это работать
Насколько хорошо будет работать закон и сколько людей пожелают воспользоваться правом на забвение, предсказать сложно. Неизвестно пока и то, сколько жалоб будет удовлетворено поисковиками. Одно можно сказать точно: «всеобщего забвения» все равно не наступит, благодаря довольно четко прописанным критериям. Кроме этого, по словам руководителя проекта «Роскомсвобода» (общественная организация «Роскомсвобода» признана иноагентом) Артема Козлюка, из закона следует, что поисковая система имеет право не удовлетворять жалобу пользователя без судебного постановления. Так что судиться за свою репутацию тем же политикам или бизнесменам все равно придется.
- право на забвение
- интернет
- защита информации
Источник: www.klerk.ru
Магазины


По техническим причинам личный кабинет временно недоступен.
Ростовская область, Аксайский район, г. Аксай, пр. Аксайский, 23
Режим работы МЕГИ
Ежедневно: c 10:00 до 22:00
Выбери свою МЕГУ
Санкт-Петербург
Нам нужны ваши отзывы!
Это займет пару минут
Файлы куки
Почему Google не индексирует некоторые страницы моего сайта

Многие страницы никогда не индексируются Google. Узнайте, почему почему Гугл не индексирует страницы сайта. Но сначала подпишитесь на наш Телеграм. Там идеи, которые мы больше нигде не публикуем.
Почему мы пишем про индексацию сайта в Гугл:
Напишите нам, пожалуйста, в WhatsApp, когда вам понадобится что-то из этого:
Если вы работаете с сайтом, особенно с большим, вы, вероятно, заметили, что не все страницы вашего сайта индексируется. Почему Google пишет: «страница просканирована, но пока не проиндексирована указанные ниже страницы не индексируются Google и не появляются в результатах поиска»?
Причин может быть несколько.
Многие seo-оптимизаторы по-прежнему считают, что Google не может индексировать контент из-за технических особенностей, но это миф. Правда в том, что Google может не проиндексировать ваши страницы, если вы не отправляете последовательные технические сигналы о том, какие страницы вы хотите проиндексировать.
Что касается других технических проблем: такие вещи, как JavaScript, действительно усложняют индексацию, ваш сайт может страдать от серьезных проблем с индексированием, даже если он написан на чистом HTML.
Причины, по которым Google не индексирует ваши страницы
Проверив самые популярные интернет-магазины мира, обнаружили, что в среднем 15% их индексируемых страниц продуктов невозможно найти в Google.
Результат удивительный. Почему? Каковы причины, по которым Google решает не индексировать то, что технически должно быть проиндексировано?
Консоль поиска Google сообщает о нескольких статусах неиндексированных страниц, например «Просканировано — в настоящее время не проиндексировано» или «Обнаружено — в настоящее время не проиндексировано». Хотя эта информация явно не помогает решить проблему, это хорошее начала диагностики.
Основные проблемы с индексацией
Наиболее популярные проблемы индексации, о которых сообщает Google Search Console:
1. «Просканировано — в настоящее время не проиндексировано»
В этом случае Google посетил страницу, но не проиндексировал ее.
Исходя из моего опыта, это обычно проблема качества контента. Учитывая бум электронной коммерции, который в настоящее время происходит, ожидаемо, что Google стал более требовательным к качеству сайтов. Поэтому, если вы заметили, что ваши страницы «просканированы — в настоящее время не проиндексированы», убедитесь, что контент на этих страницах имеет уникальную ценность:
- Используйте уникальные заголовки, описания и текст на всех индексируемых страницах.
- Избегайте копирования описаний продуктов из внешних источников.
- Используйте канонические теги для объединения повторяющегося контента.
- Запретите Google сканировать или индексировать некачественные разделы вашего сайта с помощью файла robots.txt или тега noindex.
2. «Обнаружено — в настоящее время не индексируется»
Это проблема может охватывать всё, от проблем со сканированием до недостаточного качества контента. Это серьезная проблема, особенно в случае крупных интернет-магазинов. И такое может случиться с десятками миллионов URL-адресов на одном сайте.
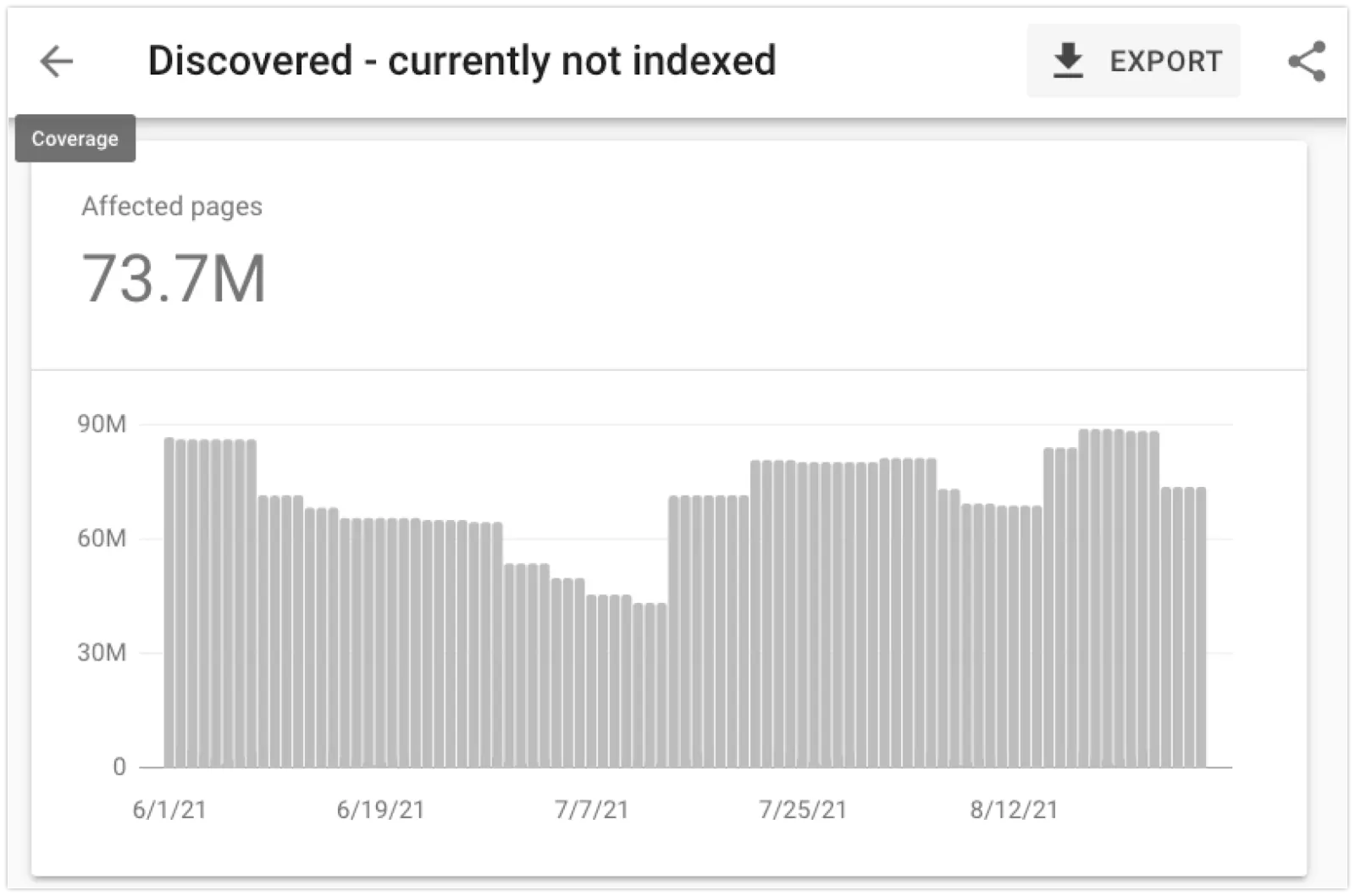
Google может сообщить, что страницы продуктов электронной коммерции «обнаружены — в настоящее время не проиндексированы» по следующим причинам:
- Проблема с бюджетом сканирования: в очереди сканирования может быть слишком много URL-адресов, и они могут быть просканированы и проиндексированы позже.
- Проблема с качеством: Google может подумать, что некоторые страницы в этом домене не стоит сканировать и решит не посещать их, ища шаблон в их URL.
Чтобы справиться с этой проблемой, требуется некоторый опыт. Если вы обнаружите, что ваши страницы «обнаружены — в настоящее время не проиндексированы», сделайте следующее:
- Определите, есть ли шаблоны страниц, попадающих в эту категорию. Может быть, проблема связана с определенной категорией товаров, а вся категория не имеет внутренней связи? Или, может быть, огромная часть страниц продуктов ожидает в очереди на индексирование?
- Оптимизируйте свой краулинговый бюджет. Сосредоточьтесь на обнаружении некачественных страниц, которые Google тратит много времени на сканирование. К обычным подозрениям относятся страницы отфильтрованных категорий и страницы внутреннего поиска — эти страницы могут легко попасть в десятки миллионов на типичном сайте электронной коммерции. Если робот Googlebot может свободно их сканировать, у него может не быть ресурсов для доступа к ценным материалам на вашем сайте, проиндексированным в Google.
Дублирование контента может быть вызвано разными причинами, например:
- Варианты языка (например, английский язык в Великобритании, США или Канаде). Если у вас есть несколько версий одной и той же страницы, ориентированных на разные страны, некоторые из этих страниц могут оказаться неиндексированными.
- Дублированный контент, используемый вашими конкурентами. Это часто происходит в e-commerce, когда несколько сайтов используют одно и то же описание продукта, предоставленное производителем.
Помимо использования rel = canonical, 301 редиректа или создания уникального контента, я бы сосредоточился на предоставлении уникальной ценности для пользователей. Fast-growing-trees.com может быть примером. Вместо скучных описаний и советов по посадке и поливу на сайте можно увидеть подробный FAQ по многим продуктам.
Кроме того, вы можете легко сравнивать похожие товары.
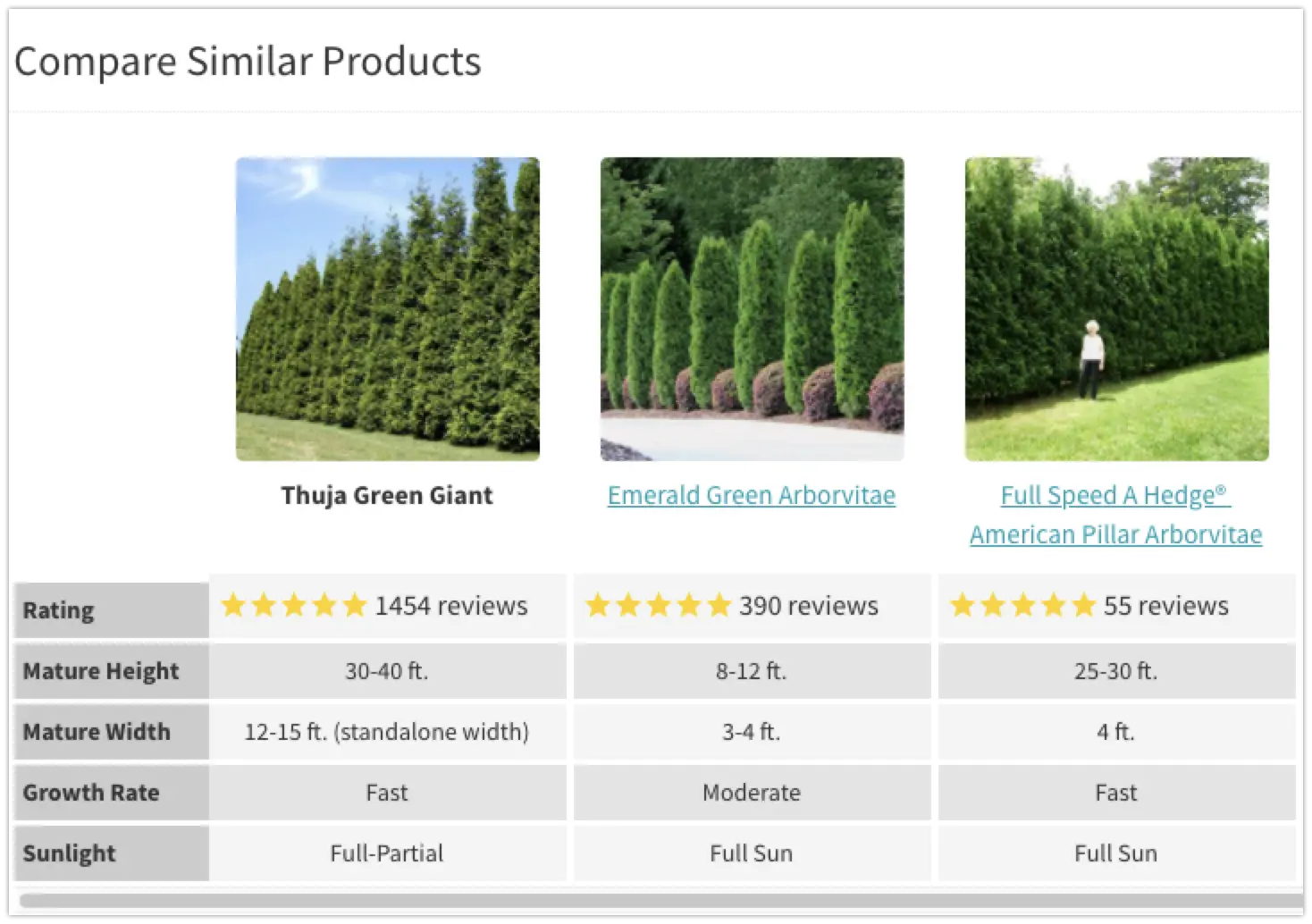
Для многих продуктов есть FAQ.
Как проверить индексирование вашего сайта
Вы можете легко проверить, сколько страниц вашего сайта не проиндексировано, открыв отчет об индексировании в Google Search Console.
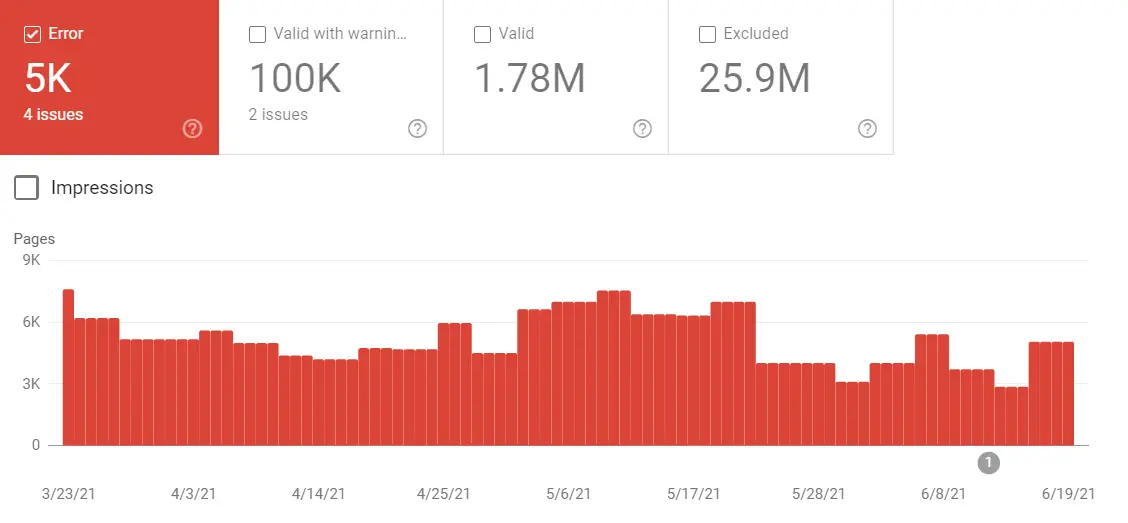
Первое, на что следует обратить внимание, — это количество исключенных страниц. Затем попробуйте найти закономерность — какие типы страниц не индексируются?
Если у вас интернет-магазин, вы, скорее всего, увидите неиндексированные страницы продуктов. Хотя это всегда должно быть предупреждающим знаком, вы не можете ожидать, что все страницы ваших продуктов будут проиндексированы, особенно на большом сайте. Например, в большом интернет-магазине обязательно будут дублирующиеся страницы и товары с истекшим сроком годности или отсутствующие в наличии. Этим страницам может не хватать качества, которое поместило бы их в начало очереди индексации Google (и это если Google вообще решит сканировать эти страницы).
Кроме того, на крупных интернет-магазинах, как правило, возникают проблемы с бюджетом сканирования. Я видел случаи, когда в интернет-магазинах было более миллиона товаров, в то время как 90% из них были классифицированы как «обнаруженные — в настоящее время не проиндексированные». Но если вы видите, что важные страницы исключаются из индекса Google, вы должны быть серьезно обеспокоены.
Как повысить вероятность того, что Google проиндексирует ваши страницы
Каждый сайт индивидуален и может иметь разные проблемы с индексированием. Тем не менее, вот советы, как проиндексировать сайт:
1. Избегайте ошибок «Soft 404».
Убедитесь, что на ваших страницах нет ничего, что может ложно указывать на мягкий статус 404. Это включает в себя все, что угодно, от использования «Не найдено» или «Недоступно» в копии до наличия числа «404» в URL-адресе.
2. Используйте внутренние ссылки.
Внутренние ссылки — один из ключевых сигналов для Google о том, что данная страница является важной частью сайта и заслуживает индексации. Не оставляйте лишних страниц в структуре вашего сайта и не забудьте включить все индексируемые страницы в карты сайта. Внутренние ссылки — один из элементов кайдзен сайта.
3. Реализуйте надежную стратегию сканирования.
Не позволяйте Google сканировать ваш сайт. Если на сканирование менее ценных частей вашего домена тратится слишком много ресурсов, Google может потребоваться слишком много времени, чтобы добраться до нужного. Анализ журнала сервера может дать вам полное представление о том, что сканирует робот Googlebot и как его оптимизировать.
4. Устранение некачественного и дублированного контента.
На каждом большом сайте в конечном итоге появляются страницы, которые не следует индексировать. Убедитесь, что эти страницы не попадают в ваши карты сайта, и при необходимости используйте тег noindex и файл robots.txt. Если вы позволите Google проводить слишком много времени в худших частях вашего сайта, это может недооценить общее качество вашего домена.
5. Посылайте последовательные сигналы SEO.
Один из распространенных примеров отправки непоследовательных сигналов SEO в Google — это изменение канонических тегов с помощью JavaScript. Как сказал Мартин Сплитт из Google во время работы JavaScript SEO Office Hours, вы никогда не можете быть уверены в том, что Google будет делать, если у вас есть один канонический тег в исходном HTML и другой после рендеринга JavaScript.
Интернет становится слишком большим
За последние пару лет Google совершил гигантский скачок в обработке JavaScript, упростив работу оптимизаторов поисковых систем. В наши дни реже можно увидеть сайты на базе JavaScript, которые не индексируются из-за конкретного технического стека, который они используют.
Но можем ли мы ожидать того же самого с проблемами индексации, не связанными с JavaScript? Я так не думаю. Интернет постоянно растет. Каждый день появляются новые сайты, а существующие растут. Сможет ли Google справиться с этой проблемой?
Этот вопрос появляется время от времени. Цитата Google:
«У Google ограниченное количество ресурсов, поэтому, когда он сталкивается с почти бесконечным количеством контента, доступного в Интернете, робот Googlebot может найти и просканировать только часть этого контента. Затем из просканированного контента мы можем проиндексировать только его часть».
Другими словами, Google может посещать только часть всех страниц в Интернете и индексировать еще меньшую часть. И даже если ваш сайт великолепен, вы должны помнить об этом.
Вероятно, Google не будет посещать все страницы вашего сайта, даже если он относительно небольшой. Ваша задача — убедиться, что Google может обнаруживать и индексировать страницы, важные для вашего бизнеса.
Источник: reconcept.ru