Вот уже более трех лет мы занимаемся парсингом сайтов и знаем, насколько этот инструмент полезен и актуален в сфере бизнеса. До появления сервисов парсинга сайтов разработка парсера была камнем преткновения для людей, не смыслящих в программировании. Теперь каждый имеет возможность обратиться к специалистам в этой сфере, либо использовать для этого готовые инструменты.
11 925 просмотров
Преимущества ботов для парсинга сайтов :
— избавляют от рутинной работы (ничего копировать и вставлять не нужно)
— автоматизация получения данных в нужном вам формате
— экономия. Не придется тратить деньги на наём профессионального аналитика
— не требуются технические навыки и знания
От парсера афиши театра на Python до Telegram-бота. Часть 1

Я очень люблю оперу и балет, но не очень — отдавать большие деньги за билеты. Ежедневный просмотр сайта театра с тыканьем в каждую кнопку ужасно утомлял, а внезапно появлявшиеся билеты по 170 рублей на супер-составы бередили душу.
Telegram-бот + парсер на Python
Чтобы автоматизировать это дело появился скриптик, который бежит по афише и собирает информацию о самых дешевых билетах на выбранный месяц. Запросы из серии «выдай список всех опер в марте на старой и новой сцене до 1000 рублей». Подруга обронила «а ты не Telegram-бота делаешь?». Такого в плане не было, но почему бы и нет. Бот родился, хоть и крутился на домашнем ноутбуке.
Потом Telegram заблокировали. Мысль запулить бота на рабочий сервер растаяла, да и интерес, чтобы довести функционал до ума, угас. Под катом рассказываю о судьбе сыщика дешевых билетов с самого начала и о том, что с ним сталось после года использования.
1. Зарождение идеи и постановка задачи
В первоначальной постановке у всей истории была одна задача — формировать отфильтрованный по цене список спектаклей, чтобы экономить время на ручном просмотре каждого спектакля афиши в отдельности. Единственный театр, чья афиша интересовала, был и остается Мариинский. Личный опыт быстро показал, что бюджетная «галерка» открывается в случайные дни на случайные спектакли, а раскупается достаточно быстро (если состав стоящий). Чтобы ничего не упустить, и нужен автоматический сборщик.
Вид афиши с кнопочками, по которым приходилось вручную переходить

Хотелось за прогон скрипта получать ограниченный набор интересующих спектаклей. Главным критерием, как уже говорилось, была цена на билет.
API сайта и билетной системы в открытом доступе нет, поэтому было принято решение (не мудрствуя лукаво) пропарсить HTML-страницы, по тегам выдергивая нужное. Открываем главную, жмем F12 и изучаем структуру. Выглядело адекватно, так что дело быстро дошло до 1й реализации.
Понятно, что такой подход не масштабируется на другие сайты с афишами и посыпется, если текущую структуру решат сменить. Если у читателей есть идеи, как сделать стабильнее без API, пишите в комментарии.
#1 Парсинг сайта + Telegram бот на aiogram | Requests, beautifulsoup, aiogram
2. Первая реализация. Минимальный функционал
К реализации подошла с опытом работы с Python только для решения задач, связанных с машинным обучением. Да и какого-то глубокого понимания html и web-архитектуры не было (и не появилось). Поэтому все делалось по принципу «куда иду знаю, а как идти — сейчас найдем»
Для первых набросков понадобилось 4 вечерних часа и знакомство с модулями requests и Beautiful Soup 4 (не без помощи годной статьи, спасибо автору). Для допиливания наброска — еще выходной день. Не до конца уверена, что модули самые оптимальные в своем сегменте, но текущие потребности они закрыли. Вот что вышло на первом этапе.
Какую информацию и откуда выдергивать можно понять по структуре сайта. Первым делом — собираем адреса представлений, которые есть в афише на выбранный месяц.
Структура страницы афиши в браузере, все удобно подсвечивается
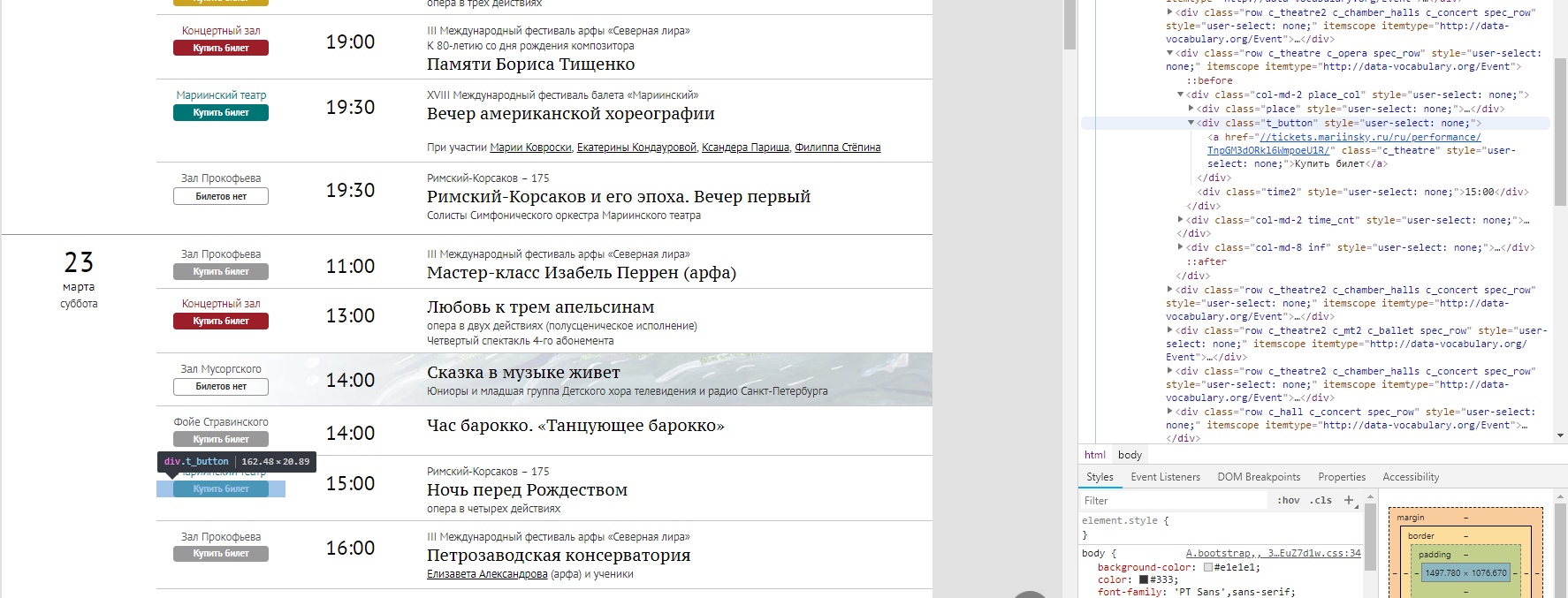
Из html-страницы нам надо считать чистые URL-адреса, чтобы потом пройтись по ним и посмотреть ценник. Примерно так происходит сборка списка линков.
import requests import numpy as np from bs4 import BeautifulSoup def get_text(url): #из URL вытаскиваем html r = requests.get(url) text=r.text return text def get_items(text,top_name,class_name): «»» из всего html-текста собираем «грязные» url-ки, т.е. с какой-то обвеской. В нашем случае выдергиваем их через top_name и class_name итог выглядит как-то так Купить билет «»» soup = BeautifulSoup(text, «lxml») film_list = soup.find(‘div’, ) items = film_list.find_all(‘div’, ) dirty_link=[] for item in items: dirty_link.append(str(item.find(‘a’))) return dirty_link def get_links(dirty_list,start,end): #из «грязной» версии забираем чистые URL-ы links=[] for row in dirty_list: if row!=’None’: i_beg=row.find(start) i_end=row.rfind(end) if i_beg!=-1 month=’+str(num) #ключевые слова для поиска top_name=’container content gr_top’ class_name=’t_button’ start=’tickets’ end=’/»>Купить’ #вызов функций text=get_text(url) dirty_link=get_items(text,top_name,class_name) #и получаем списочек URL-адресов, ведущих на покупку билетов links=get_links(dirty_link,start,end)
После изучения структуры страницы с покупкой билетов, помимо порога по цене, решила дать возможность пользователю также выбрать:
- тип представления (1-опера, 2-балет, 3-концерт, 4-лекция)
- место проведения (1-старая сцена, 2-новая сцена, 3-концертный зал, 4-камерные залы)
Вышло около 150 строк кода. В этом варианте, с описанными минимальными функциями скрипт живее всех живых и запускается регулярно с периодом в пару дней. Все остальные модификации либо были не допилены (шило утихло) и поэтому неактивны, либо не более выигрышные по функциям.
3. Расширение функционала
На втором этапе решила отслеживать изменение цен, храня ссылки на интересующие спектакли в отдельном файле (точнее URL на них). В первую очередь это актуально для балетов — сильно дёшево на них бывает редко и в общую бюджетную выдачу они не попадут. Но с 5 тысяч до 2х падение значимо, особенно если спектакль с звездным составом, и его хотелось отследить.
Чтобы это сделать надо сначала добавить URL-адреса для отслеживания, а потом периодически «перетряхивать» их и сравнивать новую цену со старой.
def add_new_URL(user_id,perf_url): #user_id нужно, чтобы отличать пользователей и потом пригодилось в телеграм-боте WAITING_FILE = «waiting_list.csv» with open(WAITING_FILE, «a», newline=»») as file: curent_url=’https://’+perf_url text=get_text(curent_url) #проходим разок и собираем инфо о спектакле-минимальную цену, название,дату,тип и место minP, name,date,typ,place=find_lowest(text) user = [str(user_id), perf_url,str(m)] writer = csv.writer(file) writer.writerow(user) def update_prices(): #а так можно обновлять цены на интересующие спектакли print(‘Обновляю цены’) WAITING_FILE = «waiting_list.csv» with open(WAITING_FILE, «r», newline=»») as file: reader = csv.reader(file) gen=[] for row in reader: gen.append(list(row)) L=len(gen) lowest=<> with open(WAITING_FILE, «w», newline=»») as fl: writer = csv.writer(fl) for i in range(L): lowest[gen[i][1]]=gen[i][2] #добавляем по ключу URL цену for k in lowest.keys(): text=get_text(‘https://’+k) minP, name,date,typ,place=find_lowest(text) if minP==0: #где билетов нет ставим большой ценник, а при их появлении цена «упадет» minP=100000 if int(minP)
Обновление цен запускалось в начале главного скрипта, отдельно не выносилось. Может, не так изящно, как хотелось бы, но свою задачу решает. Так что вторым дополнительным функционалом стал мониторинг снижения цен на интересующие спектакли.
Дальше рождался Telegram-бот, не так легко-быстро-задорно, но все же родился. Чтобы не собирать все в одну кучу, история о нем (а также о нереализованных идеях и попытке проделать такое с сайтом Большого театра) будет во второй части статьи.
ИТОГ: затея удалась, пользователь(я) доволен. Потребовалась пара выходных разобраться, как взаимодействовать с html-страницами. Благо Python язык-почти-для-всего и готовые модули помогают вбить гвоздь не задумываясь о физике работы молотка.
Надеюсь, кейс будет полезен хабравчанам и, возможно, сработает как волшебный пендель, чтобы сделать наконец давно сидящую в голове хотелку.
Источник: habr.com
Статья Парсим новости в бота с помощью почти забытой технологии. Использование RSS в Python
Начинающие программисты на питоне постоянно натыкаются на уроки о том, как создать бота. И да, боты – это довольно полезная штука, но лишь в том случае, если они еще и выполняют какие-либо полезные функции. С помощью телеграмм-бота можно даже управлять компьютером удаленно. И это не так уж и сложно реализовать. Но, в данной статье мы этого делать не будем.
А займемся более прозаическими вещами и все-таки создадим бота, который получает новости. Но в отличии от других мы не будем без ума парсить новостные ленты, чтобы получить заголовки новостей и ссылку. Мы пойдем другим путем. А вот каким, давайте и узнаем в статье.
А начнем мы все же с создания бота, прежде чем будем двигаться дальше. Ведь бот будет каркасом нашего скрипта.
Что потребуется?
Для того, чтобы создать бота, нужно установить библиотеку aiogram. Делается это довольно просто, с помощью команды в терминале:
pip install aiogram
И после того, как она установлена, давайте импортируем сразу же все, что нам пригодиться в дальнейшем. А понадобятся нам из библиотеки Bot, Dispatcher, executor и types. Так же, для оформления отправляемых сообщений в более-менее красивом виде импортируем методы hbold, hlink из модуля markdown.
from aiogram import Bot, Dispatcher, executor, types from aiogram.utils.markdown import hbold, hlink
Так же нам понадобиться токен и id канала. Но это лишь в том случае, если мы будем отправлять сообщения не в бота, а пересылать их непосредственно в канал. Как получить токен, думаю вы знаете. Инструкций на эту тему в интернете очень и очень много. Поэтому повторятся в данном вопросе не буду.
Скажу лишь, что, если вы создадите канал и будете отправлять с помощью бота в него сообщения, вам нужно будет после того, как вы создадите бота и канал, добавить бота в администраторы канала, чтобы он мог с ним взаимодействовать. Иначе у вас просто ничего не получиться.
А теперь давайте создадим бота и диспетчер. В бота мы передадим наш токен, а в диспетчера передадим бота для управления.
bot = Bot(token=token, parse_mode=types.ParseMode.HTML) dp = Dispatcher(bot)
Токен и id канала я сохранил в отдельном файле, который и импортировал в создаваемый скрипт с помощью:
from config import token, id_channel
Теперь давайте создадим функцию, в которой и будет происходить получение новостей и отправка их в канал или чат. Назовем ее просто start. Или можете назвать как-то иначе. Это не особо принципиально. И укажем в диспетчере, что вызов данной функции будет происходить посредством отправки боту команды /start.
Само тело функции пока что опущу, тут нужно будет более детально пройтись по всему, что будет в ней твориться. Об этом ниже. А пока запустим бота на исполнение. А вернее создадим для этого функцию, где и поместим команду на запуск.
if __name__ == «__main__»: # запускаем бота executor.start_polling(dp)
Теперь давайте перейдем к основному телу функции. Как вы уже поняли, нам нужно будет получить новости с какого-либо новостного сайта. И тут есть два путя. Можно парсить, можно не парсить. Я пошел по первому пути. Не сейчас, конечно, а когда только пробовал создать себе новостного бота. Не скажу, что это быстрая задача.
Ведь я поставил себе задачу обработать штук пять новостных сайтов. Или даже больше. Уже точно не помню. Но помню, что у меня получились простыни кода, которые пришлось вынести в отдельный модуль и вызывать его в основной функции.
Впрочем, наверное, так и надо делать. Но, просто я помню, сколько было потрачено усилий для того, чтобы просто получить новости. А оказывается, если бы мы не забывали о старых технологиях, о тех технологиях, которые постепенно сходят на нет, но, кое-где еще остаются, то все получилось бы гораздо быстрее и проще. А речь идет об RSS. И тут уже не надо парсить сотни строк кода.
Не надо искать тэги, в которых находится текст новости или ссылка на нее. Тут достаточно спарсить RSS, а затем пройтись по полученному xml.
Для начала установим библиотеку rss-parser с помощью команды:
pip install rss-parser
И импортируем нужные нам модули в скрипт:
from rss_parser import Parser
А теперь, когда все необходимые приготовления проделаны, давайте перейдем к написанию тела бота. Для начала создадим список, в который будем складывать заголовки. Это нужно для того, чтобы через полчаса не получить ту же самую новость.
А теперь запускаем бесконечный цикл, в котором и будет происходить получение новостей:
В первую очередь, чтобы не хранить в памяти слишком много значений списка, проверяем его длину. И если она больше 20, то сбрасываем все его значение.
if len(habr_title) > 20: habr_title = []
Теперь введем переменную, в которой будем хранить ссылку на ленту новостей. У Хабра ссылка, к примеру такая:
Дальше получаем содержимое xml по данной ссылке.
Полученное содержимое передаем в парсер, где и происходит основное действо. Тут же можно установить параметр limit, который будет выводить из RSS столько новостей, сколько вы укажете. Это очень похоже на точно такой же параметр lxml, когда парсишь сайт. Ну да ладно, вот код парсера:
parser = Parser(xml=xml.content, limit=3)
Теперь передаем все в переменную:
И запускаем цикл, в котором проходимся по каждому полученному значению, по каждой новости:
for item in reversed(feed.feed):
Дальше делаем проверку есть ли заголовок новости в списке или нет. Если есть, новость пропускаем. Если нет, добавляем заголовок в список и отправляем новость в чат или канал.
if not item.title in habr_title: habr_title.append(item.title) # await message.answer(f’nnnn’) await bot.send_message(id_channel, f’nnnn’)
Как вы понимаете, тут можно пойти двумя путями, про которые я уже упоминал. Выше указан код и для отправки в чат бота, и для отправки в канал, который будет создан вами. В чат бота это закомментированный код отправки, в канал, тот, что раскомментирован.
Давайте пройдемся чуть подробнее по коду. Здесь параметр publish_date, как можно понять из контекста, означает дату публикации. title – заголовок новости, а link – ссылка на нее. Ну и обернут этот код в разметку markdown.
Дату публикации я сделал жирной, а вот заголовок и ссылку поместил в специальный тэг, первым параметром у которого служит текст, в данном случае заголовок, а вторым параметром ссылка. Таким образом заголовок в сообщении будет уже содержать в себе ссылку на новость. Что намного эстетичнее, чем то и другое по раздельности.
Ну и запускаем таймер, в котором указываем, сколько секунд будем спать до следующей проверки. В данном случае указано полчаса.
Вот, собственно, и все. Такой просто и небольшой код, взамен простыней парсинга. Если бы я раньше вспомнил об этой технологии и поискал бы решение, то может быть мои боты работали до сих пор. А того бота я забросил. Уж не помню почему, но, по-моему, код изменился на странице какого-то из порталов.
А переписывать парсер мне было просто лень. Тем не менее, это было очень полезно, потому как я, все же получил бесценный опыт.
Полный код бота для парсинга новостей из RSS
Как видите, тут больше строк занимают комментарии, чем сам код. Если нужны новости с еще одного сайта, ищем у них RSS, копируем ссылку, пишем код, запускаем цикл и так же создаем словарь уже для заголовков нового сайта, чтобы не пересекались и не очищался словарь раньше, чем новости на сайте устареют. И все. Новости получены. И так можно продолжать довольно долго.
И даже вынести получение новостей в отдельный модуль. Но, тогда нужно будет создаваемый список возвращать боту. В общем, тут все зависит от вашей фантазии.
Бот в работе за получением новостей
Забыл упомянуть, что новости тут грузятся очень быстро. Просто потому, что не нужно тратить время на парсинг кучи страниц, а нужно всего лишь загрузить один xml-файлик.
Спасибо за внимание. Надеюсь, что данная информация будет вам полезна
Вложения
bot_rss_news.zip
1,1 КБ · Просмотры: 284
Johan Van
Well-known member
Green Team
Архонт
Green Team
03.12.2019 19 7
очень хочется захэйтить за «почти забытую технологию», но не буду. на самом деле, многие мои знакомые никогда ее и не знали. А для тех, кто связан с вебом она очень актуальна до сих пор (и Atom как продолжение)
У самого бот долгое время работал на рсс. Позже, когда появилось апи с нужными новостями, переделал на получение с апи.
Для определения новых новостей в своем боте я не храню все заголовки опубликованных новостей, храню только время публикации последней новости. При получении списка новостей, бот выбирает те, что были опубликованы позже, чем сохраненное время
В новой версии бота, там где используется апи, хранится айди новости и публикуются новости с большим айди
Johan Van
Green Team
13.06.2020 339 579
очень хочется захэйтить за «почти забытую технологию», но не буду. на самом деле, многие мои знакомые никогда ее и не знали. А для тех, кто связан с вебом она очень актуальна до сих пор (и Atom как продолжение)
У самого бот долгое время работал на рсс. Позже, когда появилось апи с нужными новостями, переделал на получение с апи.
Для определения новых новостей в своем боте я не храню все заголовки опубликованных новостей, храню только время публикации последней новости. При получении списка новостей, бот выбирает те, что были опубликованы позже, чем сохраненное время
В новой версии бота, там где используется апи, хранится айди новости и публикуются новости с большим айди
Позвольте немного пояснить. Вполне возможно, что мое суждение является сугубо субъективным. Я столкнулся с тем, что RSS, как и Atom стали пропадать с сайтов и заменятся соцсетями. А произошло это года два или три назад, когда у меня в браузере скопилась критическая масса ссылок на разные ресурсы и отслеживать все их физически я просто не мог.
Тогда я решил поставить себе какой-нибудь RSS-ридер и получать обновления сайтов уже туда. И когда я не нашел RSS на большей их половине, вот примерно тогда начало формироваться мое суждение о том, что данная технология постепенно выходит из употребления. Конечно же, полностью она никуда не уйдет. Но, все больше и больше ее заменяют соцсети.
Раньше, помню, можно было даже с помощью Feed Burner сделать себе ленту новостей. А теперь этот ресурс уже толком и не работает. Да и помню времена, когда наличие RSS на сайте было хорошим тоном. А теперь, даже если сайт на CMS и возможность включить RSS есть, она отключается уже намеренно. Ну или ее забывают включать. Тут уж не знаю.
На Дзен, так на тот вообще приходилось делать RSS с помощью стороннего ресурса. Так как там вообще не предусмотрено подобное. Может быть поэтому мне на секунду показалось, что данная технология уже почти забыта, а там где она остается, она была и раньше.
А с ботом. Ну, поначалу я хотел тоже сохранять id новости где-нибудь в json, а при проверке его подгружать и просто проверять id на совпадение. Но, потом подумал, что это в данном контексте будет немного избыточно. Тем более, что не на всех новостных сайтах у новости id есть. Я когда первую версию бота для себя делал, то сохранял id и делал проверку.
Для некоторых сайтов приходилось формировать его самостоятельно ) Тут же дело не только в Хабре. Хабр — как пример. Я знаю, что там можно и JSON получить.
Источник: codeby.net