Ещё совсем недавно было первое июня, а тут уже первое сентября. Осень на дворе.
Да, недавно тоже так отвернулся, а очнулся — Mail поглотил VK. И началось: видео без рекламы не посмотришь, музыку не послушаешь — запретили правообладатели. Ходят слухи, что вообще запретят. Почуял неладное. А тут как раз такое время года. Вот и подумал, а почему бы мне не собрать свои запасы?
Законсервирую свою музыку на своём компе, перекину на диск — слаще любого варенья будет! А поможет мне в этом, как не странно, сам ВК, а точнее — его api. А ещё третий python, встроенная библиотека urllib и библиотека по работе с данным в формате json.
У api vk можно запрашивать информацию о аудиозаписях пользователя. Ответ нам будет приходить в формате json, и в нём будет содержаться количество аудиозаписей пользователя, а также расширенная информация о каждой песне, если такая информация имеется. А главное, что у каждой песни будет url-адрес, по которому она лежит на серверах ВК. Как раз то, что нам нужно.
Парсим данные вконтакте. Что такое API? Программируем на python. Как спарсить данные через API?
Для работы с большинством методов api нужен специальный ключ (далее — access_token), который vk выдает приложениям. Как его получить — расскажу чуть позже.
Помните окошко, которое появляется, как только приложение запрашивает доступ к информации с вашей страницы? Нажимая «Разрешить», вы даете приложению право получить access_token на ваше имя, в котором будут содержаться параметры доступа к информации с вашей страницы.
Откроем вкладку «разработчикам» и создадим новое приложение:
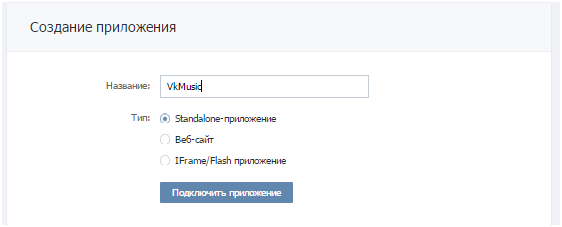
Вводим название вашего приложения и выбираем его тип: standalone-приложение:
Подтверждаем действие через смс, которая падает в ваш мобильный:

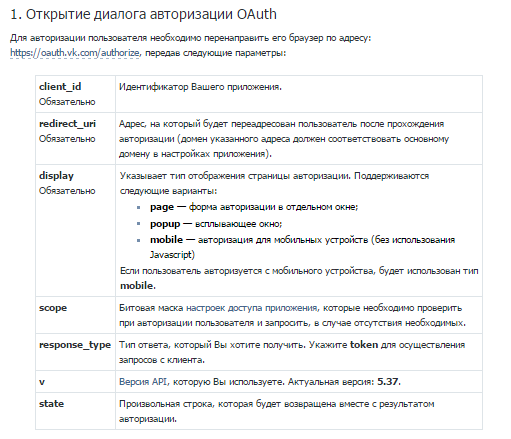
Как только мы прошли все формальности, мы получаем id нашего приложения, который будем использовать для получения access_token-a. Откроем ту часть документации, которая посвящена авторизации клиентских standalone-приложений.

Важно
redirect_uri в нашем случае должен быть равен oauth.vk.com/blank.html , так как другой адрес нужно указывать, только если мы разрабатываем браузерное javascript-приложение.
Так как в нашем приложении мы будем работать с аудиозаписями, в атрибут scope мы передадим параметр audio. Обычно access_token выдается на время. Чтобы получить его бессрочно, в атрибут scope можно передать параметр offline.
Работа с API VK (Вконтакте) через JavaScript. Урок 1. Вывод списка друзей
- несколько параметров в один и тот же атрибут пишутся через запятую.
- атрибуты в запросе пишутся через амперсанд (redirect_uri=https://oauth.vk.com/blank.htmlresponse_type=token
Если у вас всё получилось, вы увидите это окошко.
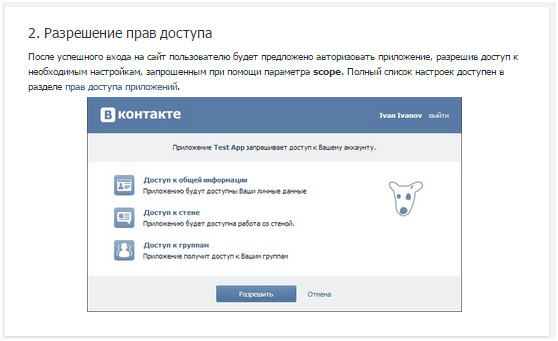
После успешной авторизации и получения прав доступа вы будете перенаправлены по адресу oauth.vk.com/blank.html . В адресной строке вы увидите атрибут access_token= YOUR_ACCESS_TOKEN . Обязательно сохраните этот ключ, чтобы не потерять его в дальнейшем. Именно его мы будем использовать при написании запросов к api.
Для того, чтобы получать список аудиозаписей пользователя, мы воспользуемся методом api audio.get. Как я уже говорил выше, метод audio.get возвращает нам ответ в json-формате. Вот пример json-объекта, который возвращает этот метод.
Итак, как вы видите, объект состоит из словаря с ключом response, по которому хранится массив песен.
Первый объект — количество песен на странице пользователя, а все последующие являются словарями, содержащими информацию о песнях. Воспользуемся методом request.urlopen из библиотеки urllib, который позволяет получать данные, хранящиеся по url-адресу в интернете.
from urllib.request import urlopen
Функция urlopen требует обязательный параметр — url-адрес, который она откроет. В нашем случае — это метод audio.get:
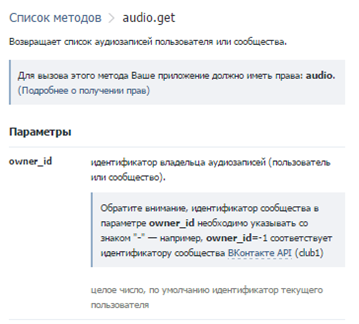
Для обращения к методам api vk нужно дергать методы, расположенные по адресу
https://api.vk.com/method/METHOD_NAME?
передавая туда все нужные методу аргументы.
Итак, напишем тот урл, который будем открывать:
data = urlopen(address)
Данные, которые мы получили, надо прочитать и раскодировать, так как нам приходит нераскодированная информация. А так, как это всё завернуто в формат json, то чтобы обращаться со словарём, как с объектом Python, мы должны воспользоваться библиотекой json.
import json
Воспользуемся методом loads(), который превращает строку, содержащую объект формата json, в объект языка Python:
decoded_response = data.read().decode()
final_data = json.loads(decoded_response)Ура! Теперь мы можем обращаться к данным, содержащимся в переменной final_data. Получим все словари, в которых содержится информация о песнях:
songs = final_data[‘response’][1:]
Этой строчкой мы получили все элементы массива response с 1 по конечный. Теперь будем работать с каждой песней отдельно.
for song in songs: song_artist = song[‘artist’] song_title = song[‘title’] song_url = song[‘url’]
Получим информацию, хранящуюся по адресу song_url:
cached_song = urlopen(song_url).read()
И запишем её в файл. Где же его создавать, спросите вы? А для этого вам нужна будет библиотека os. Напишем вне нашего цикла:
И создадим папку music на диске С функциейos.mkdir(‘C://Music’)
Теперь у нас есть папка, в которую мы хотим записывать наши песни.
Для того, чтобы наши песни хранились в порядке, мы будем создавать группы для каждого артиста. А для того, чтобы понять, нужно ли нам создавать папку, или нет, воспользуемся функцией os.listdir, которая возвращает список объектов по указанному пути:
if song_artist not in os.listdir(‘C://Music’): os.mkdir(‘C://Music/%s’ %(song_artist))
Теперь мы создаём файл и записываем туда нашу песню.
filename = ‘C://Music/%s/%s.mp3’ %(song_artist, song_title)
file = open(filename, ‘wb’)
file.write(cached_song)
file.close()Ура. Осталось всего лишь ещё раз посмотреть на красивый код и нажать «Выполнить». Ну, а ещё, конечно, подождать немного, ведь песням нужно какое-то время на запись.
Полный текст программы
from urllib.request import urlopen import json import os os.mkdir(‘C://Music’) address = ‘https://api.vk.com/method/audio.get?owner_id=MY_IDhttps://habr.com/ru/articles/266671/» target=»_blank»]habr.com[/mask_link]
Библиотека vk_api для импорта списка audio пользователя вконтакта и альтернативные пути
Необходимо получать списки аудио пользователей вк, для этого я использую библиотеку vk_api, обеспечивающую работу с api вконтакта:
import vk_api from vk_api import audio
Соответствуют ли действительности мои подозрения о том, что эта библиотека использует парсинг страниц с аудио пользователя, а не запрашивает списки аудио через api вконтакта? В разделе https://vk.com/dev/audio сказано что доступ к публичному API аудиозаписей ограничен и дана ссылка на страницу https://vk.com/dev/audio_api с подробностями, где сказано:
1. Как это работает сейчас Методы для работы с аудиозаписями пользователей и сообществ (audio) доступны для любых приложений, использующих публичный API ВКонтакте. В ответ на запрос сервер отправляет информацию о композиции, включая название, имя исполнителя, ссылку на mp3-файл. Приложение использует эти данные для отображения, воспроизведения и других действий с аудиозаписями.
2. Что изменится С 16 декабря 2016 года мы отключаем публичный API для работы с аудиозаписями. Существующие методы секции audio будут недоступны для вызова, кроме методов для загрузки аудиофайлов.
Первый пункт звучит достаточно противоречиво относительно второго, потому что 2016 уже давно минул и если я правильно понял, то первый пункт уже не о том как работает сейчас, а о том как работало до 2016 года. При первом использовании vk_api были какие то ошибки с bs4 и правильно ли я понял, что: 1) ввиду ограничений api вконтакта на работу с аудио, эта библиотека использует Beautiful Soup 4 для парсинга страниц с аудио пользователя? 2) Сам по себе парсинг работает по определению гораздо медленнее, чем могло бы работать через api, если бы такая возможность была, но ее нет и другого пути более быстро получать списки аудио пользователей, чем с помощью библиотеки vk_api (с Beautiful Soup 4) не существует?
Источник: ru.stackoverflow.com
Как получать музыку из ВКонтакте в 2022 году

2022-07-16 в 4:36, admin , рубрики: HLS, m3u8, python, VKMusicApi, Вконтакте API
Началось все с того, что мне захотелось написать музыкального бота для своего discord сервера.
При проектировании проекта, я решил разделить его на две части. Первая — получение музыки из ВК. Вторая — сам бот. И начать я решил с первой части.
Поиск какой-либо информации на этот счет или уже возможно готового куска кода не принес никаких результатов из-за чего очевидным решением данной проблемы было то, что придется разбираться с этим самому.
Я решил посмотреть что сейчас отдает ВКонтакте при воспроизведении записи и полез во вкладку network, вот что я там увидел: Фото
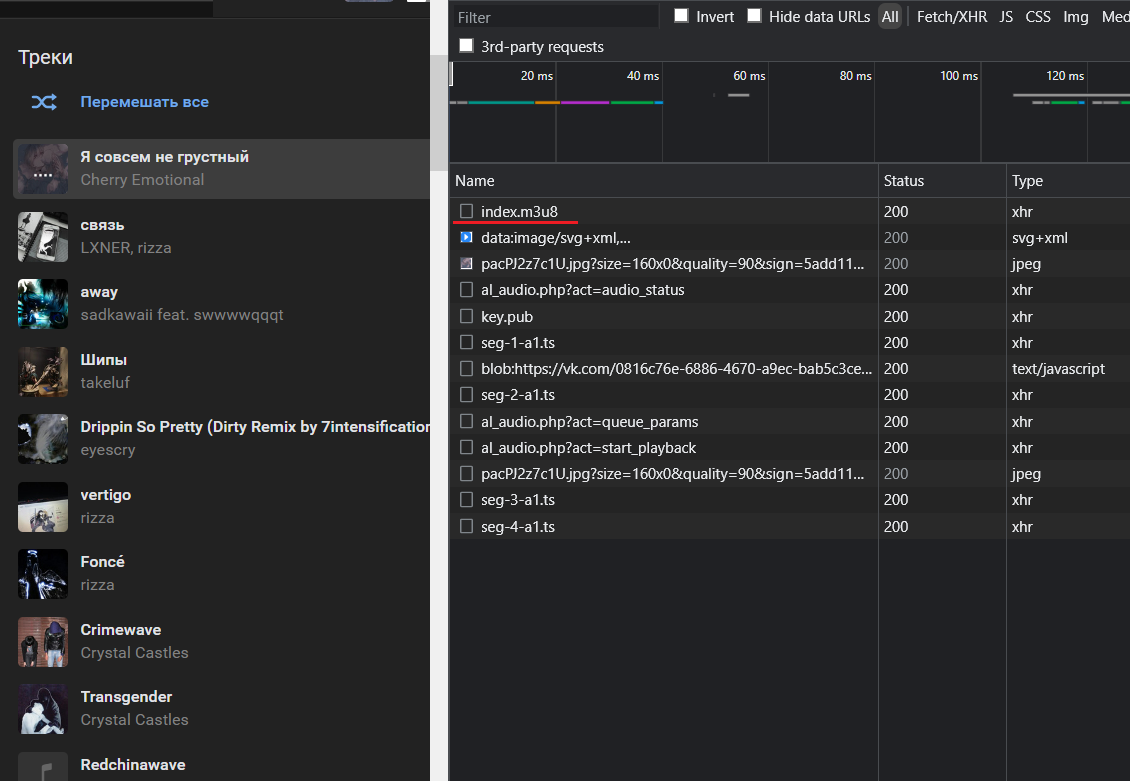
Теперь передо мной стояла новая задача, как получить с определенного аудио нужную ссылку на m3u8 файл и уже потом думать как его разбирать и собирать в дальнейшем в цельным mp3 файл.
В ходе раздумий был найден довольно простой вариант в виде библиотеки для питона vk_api и реализация получения такой ссылки через эту библиотеку выглядит так:
from vk_api import VkApi from vk_api.audio import VkAudio login = «+7XXXXXXXXXX» password = «your_password» vk_session = VKApi( login=login, password=password, api_version=’5.81′ ) vk_session.auth() vk_audio = VKAudio(vk_session) # Делаем поиск аудио по названию # Так же можно получать аудио со страницы функцией .get_iter(owner_id) # где owner_id это айди страницы # или же можно получить аудио с альбома, где мы сначала получаем айди альбомов # функцией .get_albums_iter() # и после снова вызываем .get_iter(owner_id, album_id), где album_id полученный # айди альбома q = «audio name» audio = next(vk_audio.search_iter(q=q)) url = audio[‘url’] # получаем ту длиннющую ссылку на m3u8 файл
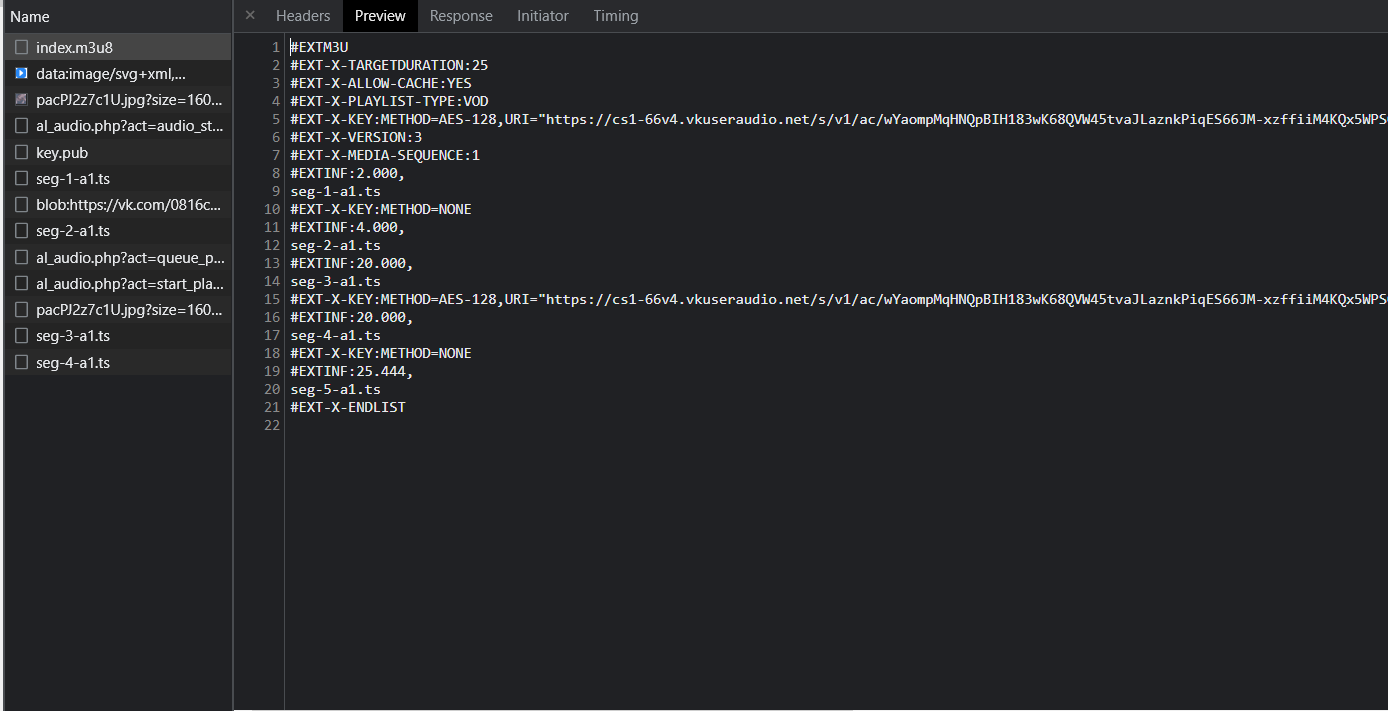
Вот мы и получили ссылку на этот файл и встал вопрос, а что делать дальше. Я попробовал запихнуть эту ссылку в ffmpeg и уже было обрадовался, ведь он скачал мой заветный аудиофайл и сразу же сделал конвертацию в mp3, однако, счастье мое длилось не долго, ведь ffmpeg хоть и скачал все сегменты, самостоятельно склеив их, но зашифрованные сегменты он не расшифровал, поэтому давайте еще раз взглянем на внутренности m3u8 файла
#EXTM3U #EXT-X-TARGETDURATION:25 #EXT-X-ALLOW-CACHE:YES #EXT-X-PLAYLIST-TYPE:VOD #EXT-X-KEY:METHOD=AES-128,URI=»https://cs1-66v4.vkuseraudio.net/s/v1/ac/wYaompMqHNQpBIH183wK68QVW45tvaJLaznkPiqES66JM-xzffiiM4KQx5WPS0Vg99U9ggCDronPKO8bzit3v_j8fH6LymN2pngBXYTv5uaDnFiAfc2aXv848bhRJEyFVB1gaJw1VR4BS9WnSb8jIMd0haPgfvJMcWC7FW7wpFkGU14/key.pub» #EXT-X-VERSION:3 #EXT-X-MEDIA-SEQUENCE:1 #EXTINF:2.000, seg-1-a1.ts #EXT-X-KEY:METHOD=NONE #EXTINF:4.000, seg-2-a1.ts #EXTINF:20.000, seg-3-a1.ts #EXT-X-KEY:METHOD=AES-128,URI=»https://cs1-66v4.vkuseraudio.net/s/v1/ac/wYaompMqHNQpBIH183wK68QVW45tvaJLaznkPiqES66JM-xzffiiM4KQx5WPS0Vg99U9ggCDronPKO8bzit3v_j8fH6LymN2pngBXYTv5uaDnFiAfc2aXv848bhRJEyFVB1gaJw1VR4BS9WnSb8jIMd0haPgfvJMcWC7FW7wpFkGU14/key.pub» #EXTINF:20.000, seg-4-a1.ts #EXT-X-KEY:METHOD=NONE #EXTINF:25.444, seg-5-a1.ts #EXT-X-ENDLIST
Мы видим, что перед зашифрованными сегментами в EXT-X-KEY указан метод шифровки AES-128 и ссылка на скачку ключа для расшифровки.
Для решения уже этой проблемы была найдена прекрасная библиотека m3u8 и pycryptodome:
import m3u8 import requests from Crypto.Cipher import AES from Crypto.Util.Padding import unpad # Получаем этот самый m3u8 файл m3u8_data = m3u8.load( url=»» # Вставляем наш полученный ранее url ) segments = m3u8.data.get(«segments») # Парсим файл в более удобный формат segments_data = <> for segment in segments: segment_uri = segment.get(«uri») extended_segment = < «segment_method»: None, «method_uri»: None >if segment.get(«key»).get(«method») == «AES-128»: extended_segment[«segment_method»] = True extended_segment[«method_uri»] = segment.get(«key»).get(«uri») segments_data[segment_uri] = extended_segment # И наконец качаем все сегменты с расшифровкой uris = segments_data.keys() for uri in uris: # Используем начальный url где мы подменяем index.m3u8 на наш сегмент audio = requests.get(url=index_url.replace(«index.m3u8″, uri)) # Сохраняем .ts файл open(f»../m3u8_downloader/segments/», «wb»).write(audio.content) # Если у сегмента есть метод, то расшифровываем его if segments_data.get(uri).get(«segment_method») is not None: # Качаем ключ key_uri = segments_data.get(uri).get(«method_uri») key = requests.get(url=key_uri) open(f»../m3u8_downloader/keys/key.pub», «wb»).write(key.content) # Открываем .ts файл f = open(f»../m3u8_downloader/segments/», «rb») # Читаем только первые 16 символов для расшифровки iv = f.read(16) # Читаем все остальное ciphered_data = f.read() # Открываем ключ key = open(f»../m3u8_downloader/keys/key.pub», «rb»).read() # Расшифровываем cipher = AES.new( key, AES.MODE.CBC, iv=iv ) data = unpad(cipher.decrypt(ciphered_data), AES.block_size) # перезаписываем .ts файл в уже расшифрованный и удаляем ключ из директории open(f»../m3u8_downloader/segments/», «wb»).write(data) os.remove(f»../m3u8_downloader/keys/key.pub»)
После чего собираем все сегменты в один .ts файл:
# путь где храним все сегменты и файлы внутри папки segments_path = «segments/» segments_file = os.listdir(segments_path) for file in segments_file: f = open(f»../m3u8_downloader//», «rb»).read() open(«../m3u8_downloader/mp3/temp.ts», «ab»).write(f)
И наконец конвертируем все в mp3 формат, для чего нам понадобиться установленный ffmpeg на ПК.
import os os.system(‘ffmpeg -i «../m3u8_downloader/mp3/temp.ts» «../m3u8_downloader/mp3/temp.mp3″‘) os.remove(«../m3u8_downloader/mp3/temp.ts»)
После чего можем спокойно удалять уже ненужные сегменты.
segments_path = «segments/» segments_file = os.listdir(segments_path) for file in segments_file: os.remove(segments_path + file)
Для меня это был довольно интересный опыт, поскольку я никогда до этого в своей жизни не работал с зашифрованными файлами и HLS протоколом, надеюсь Вам тоже было интересно читать это. Так же надеюсь я смог помочь другим людям, ведь никаких решений по скачиванию аудио с ВКонтакте на питоне в 2022 году я не нашел.
Так же выложу весь код: Hidden text
Источник: www.pvsm.ru