Интернет постоянно меняется, но с помощью Wayback Machine вы можете просмотреть прошлые версии страниц или даже увидеть, как выглядели мертвые ссылки – теперь это доступно в виде расширения для Chrome  Возможно, вы слышали об Архиве Интернета. Это пыльное место в сети для всех цифровых артефактов.
Возможно, вы слышали об Архиве Интернета. Это пыльное место в сети для всех цифровых артефактов.
Это не гробница, а тайник знаний, которые составляют наш цифровой опыт Его веб-гусеницы собирают данные со всех уголков Интернета, чтобы создать историческую коллекцию, которую мы можем просматривать бесплатно в любое время. Если вы считаете это полезной работой, то вам понравится расширение Wayback Machine Chrome Расширение Wayback Machine Chrome обнаруживает мертвые веб-страницы и дает вам возможность просмотреть архивную версию страницы Представьте себе это в действии.
Веб-сайт с ошибкой 404 или сообщением Page Not Found может быть раздражающим фактором. Немного устаревшая, но все еще актуальная версия веб-страницы – следующий лучший вариант. Расширение проверяет Wayback Machine, чтобы узнать, есть ли что-нибудь в ее архивах.
2. Как работать с веб-архивом
Если ответ положительный, вам будет предложено нажать и просмотреть последнюю заархивированную версию  Представьте себе это на юридическом сайте, где историческая информация может быть все еще актуальна. Или сайт, на котором когда-то размещалась нишевая информация, не обслуживаемая Google на первой странице. Гарвардское исследование 2013 года показало, что 49% URL-адресов, на которые ссылались в решениях Верховного суда США. Решения Верховного суда США теперь мертвы Ценность сохранения этих самородков цифровой золотой пыли невозможно переоценить. Расширение Wayback Machine Chrome работает для предотвращения утечки знаний из-за гниения ссылок и других распространенных веб-разрушений Марк Грэм, директор The Wayback Machine в Internet Archive, говорит во вступительном сообщении в блоге:
Представьте себе это на юридическом сайте, где историческая информация может быть все еще актуальна. Или сайт, на котором когда-то размещалась нишевая информация, не обслуживаемая Google на первой странице. Гарвардское исследование 2013 года показало, что 49% URL-адресов, на которые ссылались в решениях Верховного суда США. Решения Верховного суда США теперь мертвы Ценность сохранения этих самородков цифровой золотой пыли невозможно переоценить. Расширение Wayback Machine Chrome работает для предотвращения утечки знаний из-за гниения ссылок и других распространенных веб-разрушений Марк Грэм, директор The Wayback Machine в Internet Archive, говорит во вступительном сообщении в блоге:
В течение последних 20 лет Архив Интернета записывал и сохранял веб-страницы, и сотни миллиардов из них доступны через Wayback Machine. Это хорошо, потому что мы учимся тому, что веб хрупок и эфемерен
Установите расширение и опробуйте его на тестовом URL No Longer Available. Или со следующей ошибкой ‘Page Not Found’, которую вы хотите парировать Вернитесь сюда и скажите нам, добавляет ли это еще одно перо к удобству использования The Internet Archive и The Wayback Machine. Image Credit: Zhitkov Boris via Shutterstock.com
Тематические статьи

Как отключить живые субтитры в Chrome

Нужны ли Интернету правила и нормы? Мы спросим вас

How to Use the Internet Archive’s Wayback Machine
Нужно сжать изображение? Попробуйте эти 5 онлайн-инструментов
Как изменить адрес электронной почты на Payoneer
Поиск Google развернул новые инструменты для помощи ищущим работу

Что такое Google One? 4 причины, почему вы должны его использовать
Об авторе
Алексей Белоусов
Привет, меня зовут Филипп. Я фрилансер энтузиаст . В свободное время занимаюсь переводом статей и пишу о потребительских технологиях для широкого круга изданий , не переставая питать большую страсть ко всему мобильному =)
Источник: xn—-jtbhalmdgfdiny5d9d6a.xn--p1ai
Качаем копию сайта с Wayback Machine бесплатно
Рано или поздно любому вебмастеру потребуется скачать какой-то сайт с вебархива. Цели бывают разные, от получения забытого поисковиками и типо уникального контента, до полного копирования сайта с сохранением всей страктуры, для восстановления на приобретенном дроп-домене. Лучше всего для этого подойдет бесплатный сервис web.archive.org.
У сервиса нет никаких квот на объемы данных и время скачивания. Нам потребуется только терминал и 5 минут на настройку. Все манипуляции будут производиться в операционной системе Windows пусть 10.
Установка Ruby
Поддержка Ruby в системе необходима для работы нашей утилиты для скачивания сайтов с вебархива. Установить проще всего дистрибутивно, то есть зайти на сайт этого языка программирования и скачать инсталлятор. Все должно установиться автоматически, включая переменные окружения, и по итогу Ruby вот так мило встанет на диск C:
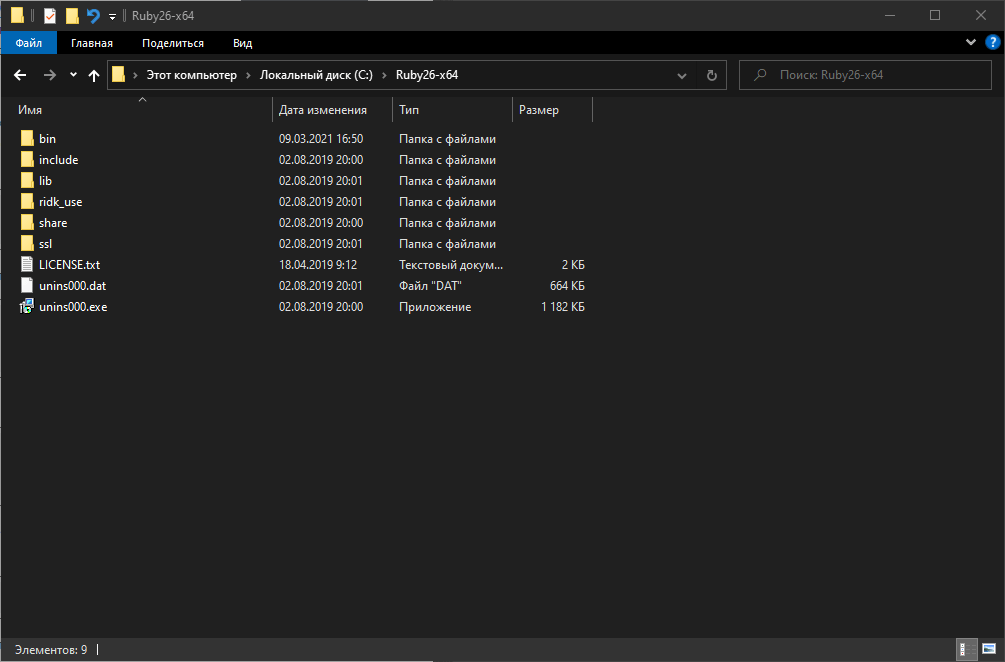
Установка Wayback Machine Downloader
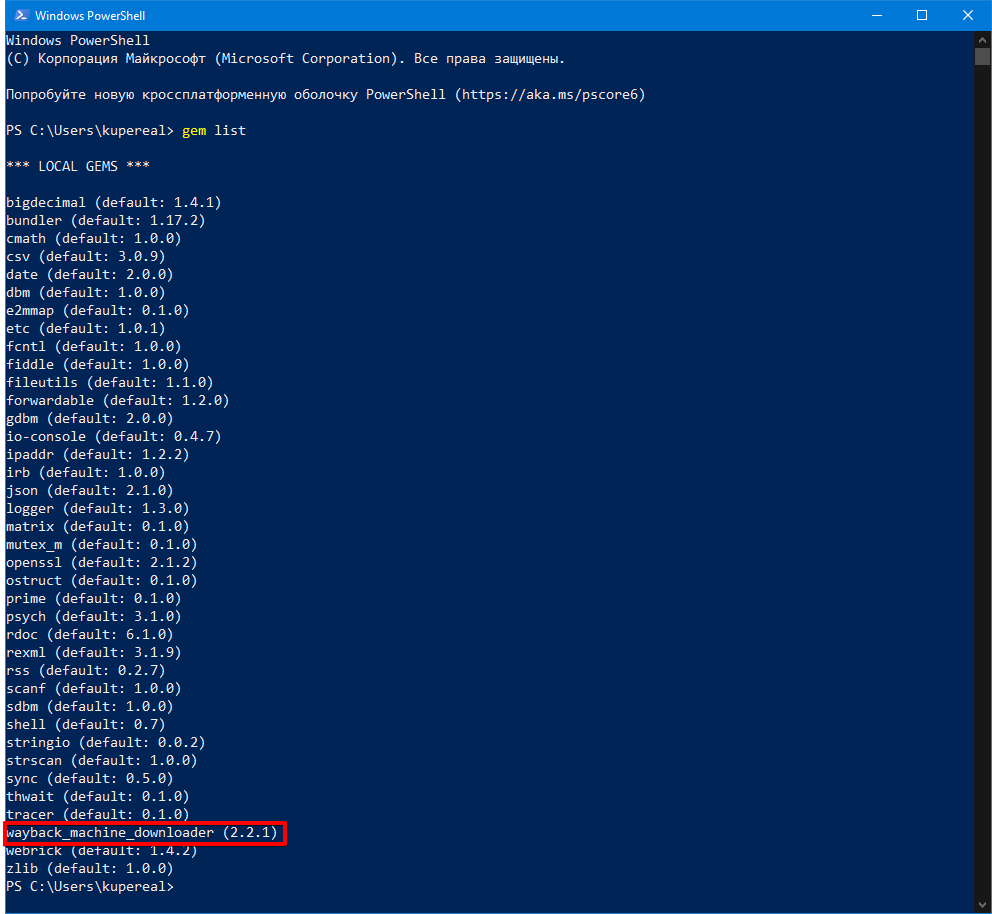
Это и есть наша бесплатная консольная утилита для скачивания архивной версии сайта. Устанавливать мы ее будем через встроенный в Ruby пакетный менеджер RubyGems, вот такой командой:
gem install wayback_machine_downloader
У меня эта программа уже установлена:
И теперь переходим к самому главному!
Качаем сайт с веб-архива бесплатно
В терминале вводим команду:
wayback_machine_downloader https://site.com
Где https://site.com — любой сайт, который нужно скачать (сайт можно указать и без протокола). Оговорка, почти любой. Некоторые сайты закрывают доступ боту вебархива в robots.txt и не сканируются сервисом, также владельцы сайта могут попросить удалить все снимки своего сайта, и это будет выполнено безоговорочно администрацией Wayback Machine.
ЧИТАЙТЕ ТАКЖЕ: Начинаем работать в JetBrains PhpStorm
Дополнительные параметры утилиты можно посмотреть на ее старнице в GitHub (см. ссылку выше по тексту).
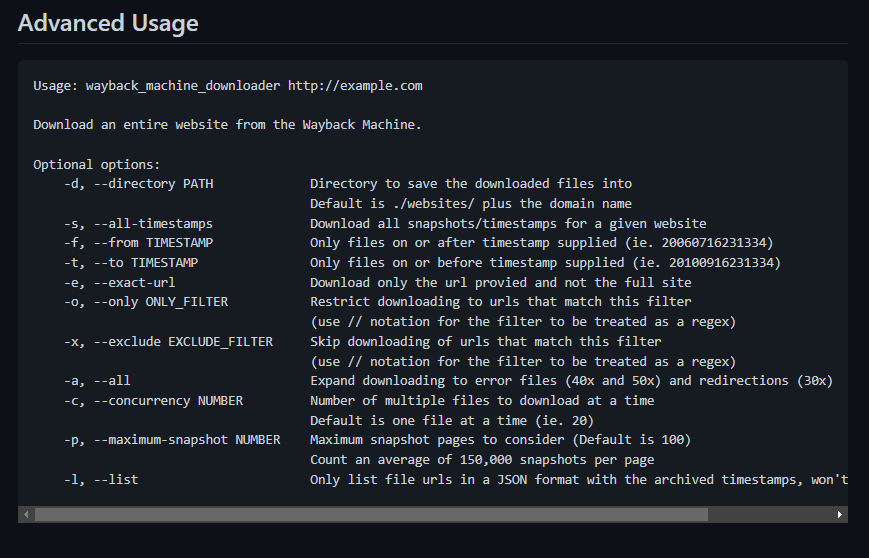
Для понимания, как пользоваться дополнительными параметрами, приведу пример. Ситуация такая, что сайт обновлялся только до определенной даты, а потом домен был припаркован. Значит нам нужно скачать сайт только до определенной даты, чтобы не скачивать мусорные страницы из снимков архива. Для наглядности проще всего посмотреть эти моменты на сайте веб-архива:

Это значение в URL — 20150214182119 называется TIMESTAMP, теперь мы можем использовать его в параметрах утилиты для скачивания старого сайта. Вот так:
wayback_machine_downloader https://site.com —to 20150214182119
Еще одна важная опция. Если скачиваемый сайт огромен, то нужно скачивать его не постранично, а, например, по 20 страниц за один подход:
wayback_machine_downloader https://site.com —to 20150214182119 —concurrency 20
Результат
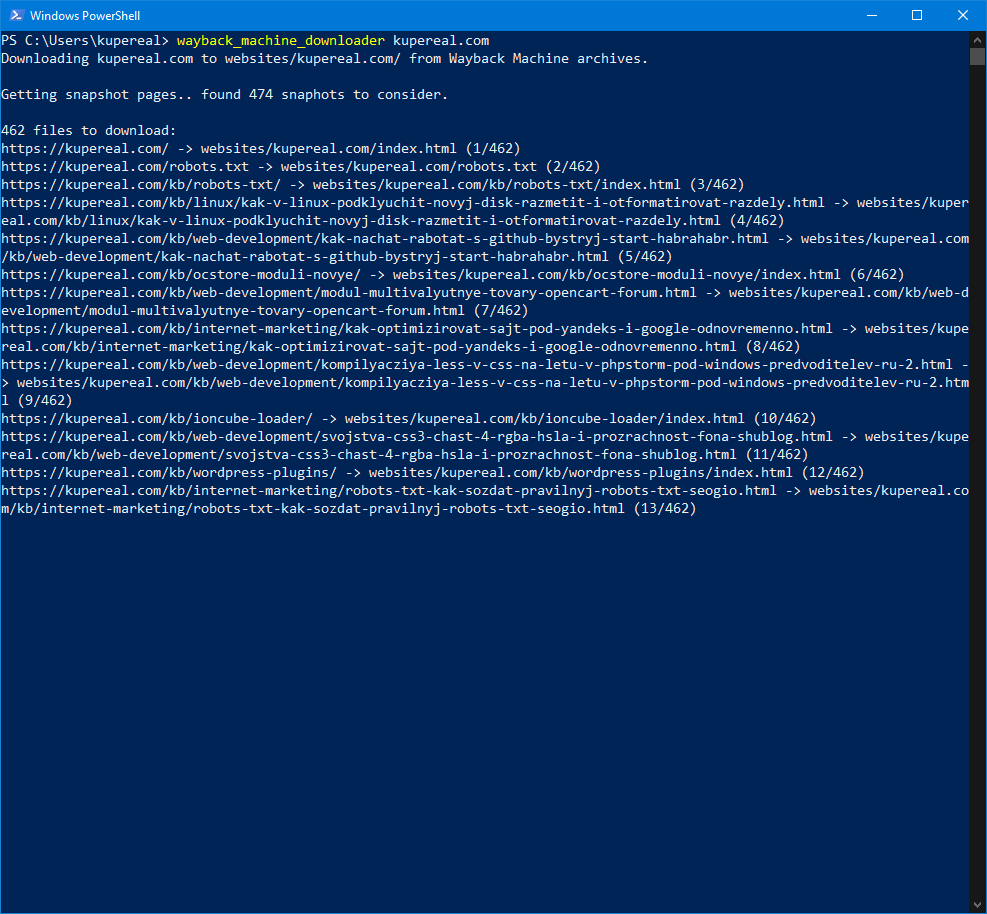
Отменить процесс можно нажав Ctrl+C. Все сайты по умолчанию будут скачиваться в папку websites в профиле пользователя.
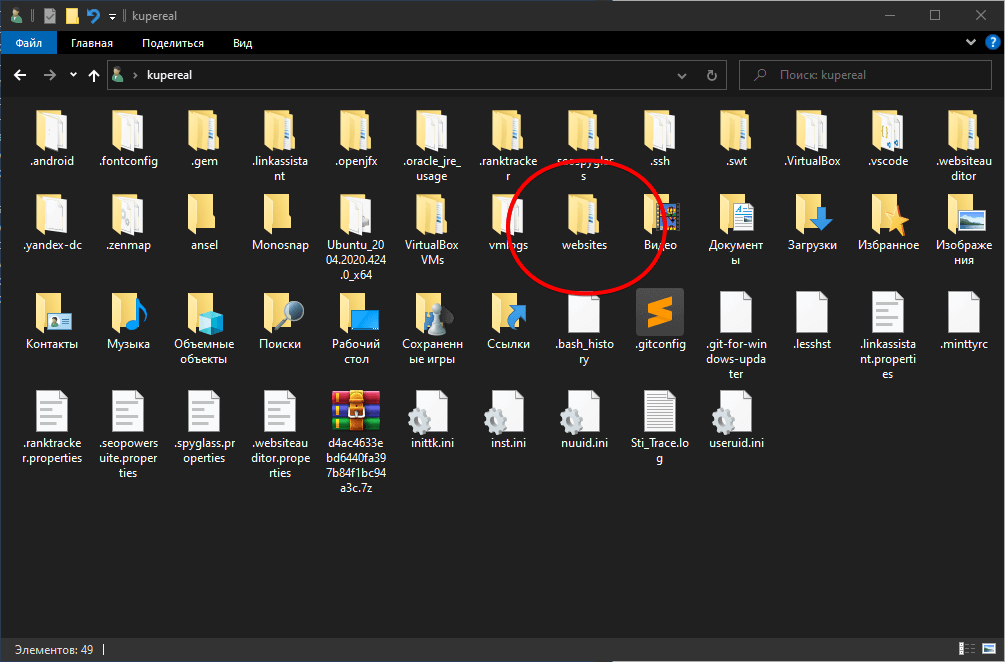
Скачиваться сайт будет в HTML формате, с сохранением структуры катологов, все внутренние ссылки тоже будут работать. По сути, это не просто скачивание архива сайта, а создание готового статического сайта на файлах, который потом можно выгружать на любой хостинг. Если вы планируете размещать статические сайты массово, то лучше выбрать хостинг с раздельной оплатой за сервисы, когда например можно оплачивать только наличие веб-сервера Apache и не платить за интерпретатор PHP или поддержку СУБД MySQL. Как вариант, можно использовать бесплатные площадки для подобных сайтов типа GitHub Pages или Cloudflare Pages. Но это уже отдельная история…
ЧИТАЙТЕ ТАКЖЕ: Спам репорт в Яндекс и Google
- Об авторе
- Недавние публикации
Источник: kupereal.com
Веб-архив сайтов: как пользоваться Internet Archive Wayback Machine

В цифровом мире, которым является Глобальная сеть, машина времени вполне реальна. Более того, она давно существует и позволяет всем желающим вернуться в те самые «старые добрые» времена, когда солнце было ярче, а трава зеленее.
Найти сервис, предоставляющий доступ к старым версиям современных сайтов все желающие могут просто перейдя по ссылке . Казалось бы, для чего нужен ресурс, хранящий на своих серверах полноценный архив Глобальной сети? Но причин для этого есть множество:
- Это просто интересно с точки зрения рядового пользователя – многим любопытно вернуться к тому самому старому дизайну привычных сайтов, который много лет назад радовал глаз и казался родным и близким. Те изменения, которые претерпевают с годами все популярные ресурсы в интернете, вызывает массу споров и критики. И, как результат, совершенно естественное желание ещё раз вернуться к классическим версиям, крепко засевшим в памяти.
- Ведение архивов позволяет восстановить доступ к утерянной информации. Сайты закрываются и пропадают, вместе со всем, размещённым на них, контентом. Поэтому иногда может быть критически важным восстановить доступ к старой информации. Также ряд вебмастеров, владеющих собственной интеллектуальной собственностью в Глобальной сети, не ведут самостоятельно архивы. И в случаях повреждения баз данных, могут рассчитывать лишь на централизованные источники бекапов.
- Возможность проведения сравнительного анализа состава наиболее важных ресурсов интернета позволяет делать далекоидущие выводы и прогнозы. Не менее ощутимые результаты приносят подобные анализы собственных ресурсов. Проследите их прогресс и те дивиденды, которые он принёс вместе с собой.
Где хранится история интернета?
Архив интернета – это самостоятельная некоммерческая организация. Она была основана в 1996 году в Сан-Франциско. Именно американский программист Брюстер Кейл решил вести учёт всей информации, накапливающейся в Глобальной сети.
Этот архив хранит не просто старые версии сайтов. Он регулярно сканирует интернет и сохраняет различные версии ресурсов, ведя историю их изменений. Помимо сайтов, здесь можно найти аудиокниги, различные видео и даже программное обеспечение.
В 2001 году владельцы Архива интернета разработали и саму машину времени – Wayback Machine . Инструмент занимается сканированием основной части открытой Сети и предоставляет доступ в интернет прошлого.
Книга и надпись History
Её используют не только для того, чтобы ностальгировать о прошлом, но находят ей практическое применение. Таким образом, например, можно возвращать к жизни старый контент. Он мог выпасть из поля зрения поисковых систем после удаления родительского сайта. Так что публикация таких статей зачастую рассматривается, как написание нового и уникального контента .
Помимо машины времени, разработчики Архива интернета дали жизнь и другим сервисам:
- Open Library – или открытая библиотека. Она хранит множество цифровых изданий и предоставляет к ним доступ сроком на две недели совершенно бесплатно.
- Archive it – полноценная служба архивирования. Она помогает физическим и юридическим лицам с созданием и обработкой цифровых архивов. Благодаря подобным программным решениям, вы можете создавать собственные библиотеки ключевых бекапов личной интеллектуальной собственности.
Технически Архив интернета основан на принципе зеркальных сайтов. То есть создаёт несколько собственных резервных копий на различных серверах. Они размещаются по всему свету и не могут быть выведены из строя одновременно.
Что такое веб-архив?
В широком смысле, веб-архив – это база данных с сохранёнными версиями страниц Глобальной сети. То есть владелец сайта может самостоятельно скопировать нужные страницы и отправить их на хранение в веб-архив.
Для самостоятельного сохранения внешнего вида интернета на определённый момент времени, веб-архивы используют поисковых роботов , активно перемещающихся по просторам Глобальной сети. Они копируют все доступные страницы и фиксируют наименования серверов их размещения. Систематизируя собранный контент по датам получения, веб-архивы фиксируют реальную историю интернета.
Благодаря таким сервисам, любой желающий может отправиться на пару десятков лет назад и посмотреть, как именно выглядели сайты того времени. Насколько они отличаются от современных аналогов и были ли действительно лучше.
Ведь на самом деле большинство изменений связаны с прогрессом и оптимизацией, а вовсе не вводятся для того, чтобы вас позлить. Дизайн меняется в угоду упрощению и эргономичности.
Сегодня наиболее важным параметром для любого ресурса является скорость его загрузки , а значит объёмные программируемые элементы просто недопустимы.
Самые посещаемые сайты могут похвастаться не одной сотней тысяч различных точек сохранения. Это говорит о важности фиксирования информации во всём её многообразии и изменении.
Воспринимая Глобальную сеть, как живой организм, который растёт и развивается, веб-архивы предстают в роли биологов, ведущих научные исследования.
Зачем нужен web archive и как его можно использовать?
Визуализация архива
Вариантов применения веб-архивов более чем достаточно. Хотя, с точки зрения рядового пользователя, не создающего самостоятельно контент в Глобальной сети, области применения подобных инструментов могут казаться и не столь очевидными:
Как просмотреть старые версии сайтов на Wayback Machine?
Принцип работы поиска веб-архивов, в общем-то, не должен вызывать особых вопросов:
Источник: rookee.ru