В этой статье мы рассказываем о том, как работает веб-сервер, какие данные отправляются и принимаются между вашим браузером и веб-сервером.
Принцип работы веб-сервера
Веб-сервер – это компьютер, который отвечает за хранение файлов веб-сайта и обмен ими с другими компьютерами. Он обычно используется для приема от клиентов запросов на веб-документы и возвращения ответов на них с определенной информацией.
Сайт становится доступен на веб-сервере после того, как зарегистрировано его доменное имя и службой DNS (Domain Name System) выполнено преобразование адресов — то есть связывание IP-адреса, обозначенного набором цифр (например, 192.168.5.12), и доменного имени ( www.site.com ).
С одним IP-адресом может быть связано несколько доменных имен. В этом случае переадресация запроса к нужному сайту происходит за счет программного обеспечения сервера, которое определяет, из какой папки запускать программу или загружать файл.
На веб-сервере хранятся файлы сайта, а именно все HTML-документы и связанные с ними ресурсы, включая изображения, стили CSS, файлы JavaScript, шрифты и видео.
Профессия Веб разработчик: кто это? | GeekBrains
Ресурсы представляют собой не только реальные файлы на сервере (HTML, js, png и т. д.). Часть содержимого генерируется в момент поступления запроса специальным программным кодом с помощью шаблонов и баз данных — например: список новостей, сводка погоды, результаты поиска по сайту, корзина покупок и прочее. Соответственно различают статические (неизменяемые) ресурсы и динамические (изменяемые и адаптированные под конкретного пользователя). Получив запрос на динамическое содержимое, веб-приложение извлекает данные из БД и заполняет ими указанный в запросе шаблон.
Как происходит взаимодействие между клиентом и веб-сервером?
Клиент, которым обычно является веб-браузер, передает веб-серверу запросы на получение ресурсов, обозначенных URL-адресами. Ресурсы — это HTML-страницы, изображения, файлы, медиа-потоки или другие данные, которые необходимы клиенту. В ответ веб-сервер передаёт клиенту запрошенную информацию.
Более детально этот процесс можно описать следующим образом:
- Браузер делит запрошенный URL на три части: протокол, доменное имя, название файла. Например, URL:https:// www.site.com/ file.html будет разделен на следующие части:
- Протокол («https»).
- Доменное имя («www.site.com»).
- Имя файла («file.html»).
- Браузер при помощи сервисов DNS преобразует доменное имя в IP адрес, который используется для связи с серверной машиной.
- Используя полученный IP адрес, браузер связывается с нужным веб-сервером и посылает на него запрос, требующий отправки файла «www.site.com / file.html».
- Веб-сервер получает запрос и ищет указанную в нём HTML-страницу. Если страница существует, сервер отправляет браузеру ответ, в котором будет HTML-код веб-страницы и заголовок с информацией о запрошенном содержимом. Он предназначен для браузера и нужен, чтобы правильно определить размер, язык переданного файла и другие параметры. Пользователь не видит эту информацию. В заголовке передается и код ответа сервера – например, 200 ОК, когда страница найдена, или сообщение об ошибке 404, если сервер не может найти запрошенную страницу. Подробнее о кодах ответа читайте ниже — в разделе «Коды состояния http».
- Браузер читает полученную от сервера HTML-страницу и подгружает другие необходимые ресурсы, которые с ней связаны — изображения, файлы стилей CSS и JavaScript, отвечающие за оформление и функционал страницы, и т. д.
- После того, как браузер закончит загрузку всех этих ресурсов, веб-страница будет отображена на экране монитора.
387. Chrome 117 и бета 118, DevTools, экологичный веб, миксины и функции в CSS, Interop 2024, Figma
Схематично взаимодействие между браузером и веб-сервером можно представить так:
Рассмотрим это же взаимодействие на уровне HTTP-протокола.
Что такое HTTP-взаимодействие?
Обмен данными между клиентом и веб-сервером происходит по протоколу HTTP.
HTTP (HyperText Transfer Protocol, то есть «протокол передачи гипертекста») — это протокол, предназначенный для передачи гипертекстовых документов (то есть документов, которые могут содержать ссылки, позволяющие организовать переход к другим документам). Правила HTTP лежат в основе передачи информации в сети Интернет.
Задача, которая традиционно решается с помощью протокола HTTP — обмен данными между пользовательским приложением, осуществляющим доступ к веб-ресурсам (обычно это веб-браузер) и веб-сервером.
Клиентское приложение формирует HTTP-запрос и отправляет его на сервер, после чего серверное программное обеспечение обрабатывает данный запрос, формирует HTTP-ответ и передаёт его обратно клиенту, как правило, вместе с HTML-страницей или другими запрошенными данными.
Каждое HTTP-сообщение состоит из трех частей:
Больше узнать о заголовках можно в спецификации протокола HTTP.
Стартовая строка и заголовок являются обязательными элементами, а тело сообщения может отсутствовать.
Структура HTTP-запроса от клиента
Если клиент хочет загрузить, например страницу «About», HTTP-запрос может включать следующие элементы:
GET /about.html HTTP/1.1 Host: www.site.com Referer: https://www.google.com/ User-Agent: Mozilla/5.0 (Windows NT 6.3; Win64; x64) Accept-Language: en-us
GET /about.html HTTP/1.1
Стартовая строка, в которой содержатся:
GET — метод запроса, указывающий на основную операцию, которую необходимо осуществить над ресурсом;
/ about.html — запрашиваемый документ;
HTTP – протокол передачи данных;
/1.1 – версия протокола 1.1.
В заголовке Referer прописан URL страницы, откуда сделан запрос.
User-Agent: Mozilla/5.0 (Windows NT 6.3; Win64; x64)
Mozilla/5.0 – название и версию браузера, отправившего запрос;
Windows NT 6.3; Win64; x64 – название и версию операционной системы.
Структура HTTP-ответа веб-сервера
- Стартовая строка в HTTP-ответе указывает версию протокола передачи данных (HTTP/1.1), код статуса ответа (трехзначное число — например, 200), описание статуса (короткое пояснение к коду ответа – например, OK).
- Заголовки – предоставляют информацию об ответе, сервере или об объекте, отправленном в теле сообщения. Например, в заголовках Content-Type и Content-Length будут указаны тип и размер контента (в байтах).
- Тело ответа – при запросе содержимого веб-ресурса в нём содержится HTML-код запрошенной страницы или выгружаемые файлы. Отделяется от заголовков пустой строкой.
HTTP/1.1 200 OK Server: nginx/1.4.6 (Ubuntu) Date: Mon, 25 Jan 2021 16:54:33 GMT Content-Type: text/html; charset=UTF-8 Content-Length: 98 Last-Modified: Mon, 25 Jan 2021 16:22:21 GMT
An Example Page
Hello World
Стартовая строка, в которой прописаны:
HTTP – протокол передачи данных;
/1.1 – версия протокола 1.1;
200 – код ответа сервера (страница доступна);
ОК — пояснение к коду ответа.
Server: nginx/1.4.6 (Ubuntu)
Date: Mon, 25 Jan 2021 16:54:33 GMT
Content-Type: text/html; charset=UTF-8
В заголовке Content-Type прописаны тип отправленного контента (text/html) и его кодировка (charset=UTF-8).
Last-Modified: Mon, 25 Jan 2021 16:22:21 GMT
Тело ответа, в котором содержится HTML-код запрошенной страницы.
Коды состояния HTTP
Трехзначный код, возвращаемый сервером в стартовой строке ответа, называется кодом состояния HTTP. Он определяет результат совершения запроса. Коды состояния HTTP разработаны в соответствии со стандартами, определенными Инженерным советом Интернета (IETF).
Первая цифра кода указывает на класс состояния. В настоящее время выделено пять классов состояния:
- 1xx — Информационное сообщение (информирует о процессе передачи).
- 2xx — Сообщение об успехе (запрос получен и обработан).
- 3xx — Сообщение о перенаправлении (запрашиваемый ресурс был перемещен на другой адрес).
- 4xx — Сообщения об ошибках со стороны клиента (запрос содержит ошибки или не отвечает протоколу).
- 5xx — Сообщения об ошибках, относящихся к серверу (сервер не смог обработать запрос, хотя тот был составлен правильно).
Вторая и третья цифры в коде детализируют статус ответа. Например:
- 200 OK — запрос получен и успешно обработан.
- 201 Created — запрос получен и успешно обработан, в результате чего создан новый ресурс или его экземпляр.
- 301 Moved Permanently — запрашиваемый ресурс был перемещен навсегда, и последующие запросы к нему должны происходить по новому адресу. Адрес, по которому клиенту следует произвести запрос, сервер указывает в заголовке Location.
- 302 Moved Temporarily — ресурс перемещен временно.
- 401 Unauthorized (Неавторизованный запрос) — для доступа к документу необходимо вводить пароль или быть зарегистрированным пользователем.
- 404 Not Found — сервер не нашел ресурс по этому адресу.
- 500 Internal Server Error — сервер столкнулся с непредвиденным условием, которое не позволяет ему выполнить запрос.
- 503 Service Unavailable — сервис недоступен из-за временной перегрузки или отключения на техническое обслуживание.
Набор кодов состояния описан в соответствующих документах RFC («Request for Comments»), содержащих технические спецификации и стандарты, установленные IETF.
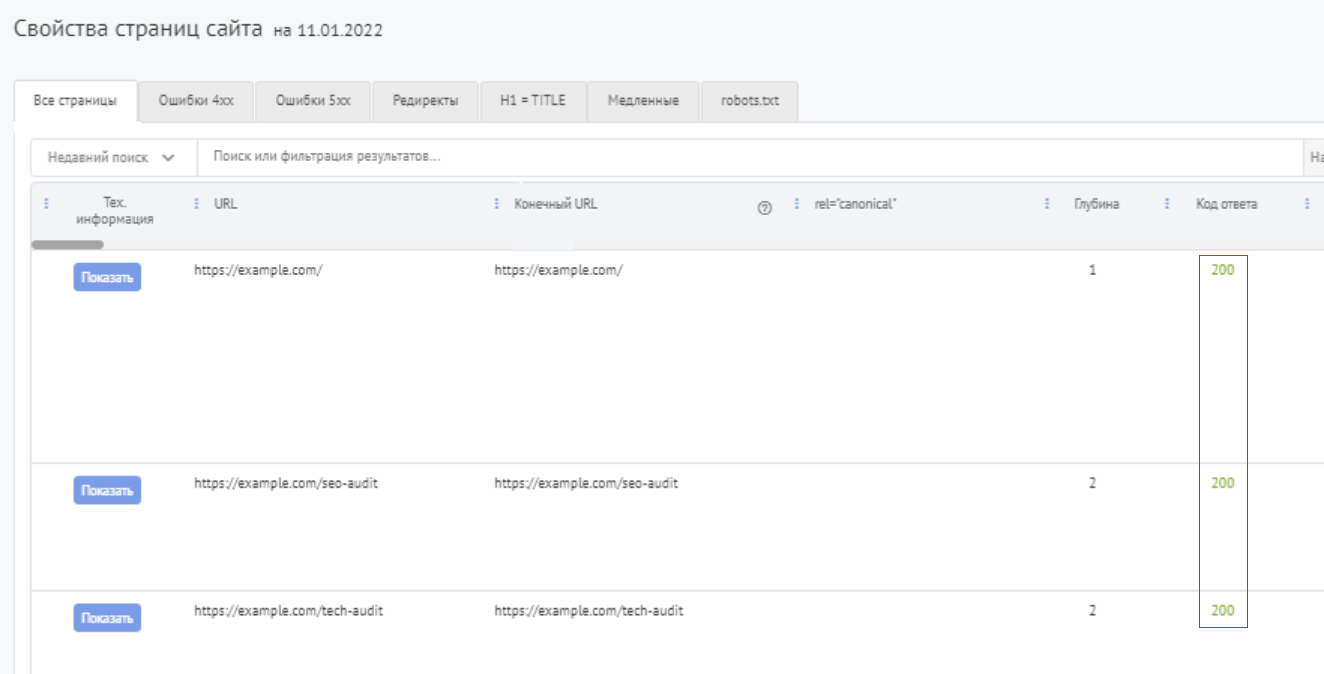
Вы можете проверить код статуса ответа страниц вашего сайта на сервисе Labrika в таблице «Свойства страниц сайта», расположенной в разделе «Инструменты».
Что такое куки (сookie)?
Куки или cookie (от англ. «печенье») — это небольшой текстовый файл с набором служебных данных о посещении сайтов, который веб-сервер отправляет для сохранения в браузере пользователя.
Браузер всякий раз при попытке открыть страницу сайта пересылает cookie обратно веб-серверу.
Примеры использования cookie:
- Автоматическая авторизация — с помощью cookie будут «запоминаться» логин и пароль.
- Для сохранения информации о товарах, добавленных в корзину.
- Для персонализации страниц с помощью cookie сохраняются личная информация и персональные настройки пользователя.
- В инструментах веб-аналитики — для отслеживания действий пользователей и сбора статистики.
От сервера браузеру cookie передаются в составе HTTP-ответа с помощью заголовка Set-Cookie:
HTTP/1.1 200 OK Content-type: text/html Set-Cookie: имя=значение
Браузер отправляет их серверу в HTTP-запросе в заголовке Cookie:
GET /spec.html HTTP/1.1 Host: www.example.org Cookie: имя=значение
Например, cookie могут содержать пароль, если пользователь авторизован на данном сайте:
Параметры HTTP-заголовков Cookie и Set-Cookie определяются в спецификации RFC 6265.
Без cookie каждый просмотр веб-страницы является изолированным действием, не связанным с другими просмотрами страниц того же сайта. Сookie позволяют выявить связь между просмотрами веб-страниц одним и тем же пользователем.
Аутентификация пользователей (то есть проверка их подлинности) с помощью cookie происходит следующим образом:
- Пользователь вводит логин и пароль в соответствующих полях на странице входа и отправляет их на сервер.
- Сервер получает имя пользователя и пароль, проверяет их и, если они верные, отправляет страницу успешного входа, прикрепив cookie с неким идентификатором сессии. Эти cookie могут быть действительны не только для текущей сессии браузера, но и быть настроены на длительное хранение.
- Каждый раз, когда пользователь запрашивает страницу с сервера, браузер автоматически отправляет cookie с идентификатором сессии серверу. Сервер проверяет идентификатор по своей базе и, при наличии в ней такого идентификатора, «узнаёт» пользователя.
HTTP и HTTPS
При передаче по протоколу HTTP данные не защищаются и передаются в открытом виде.
Расширение HTTPS (аббр. от англ. HyperText Transfer Protocol Secure) создано для того, чтобы соединение было безопасным, а данные передавались в зашифрованном виде по криптографическому протоколу SSL (secure sockets layer) или TLS (transport layer security). Это специальная «обертка» поверх HTTP, которая шифрует данные, делая их недоступными для злоумышленников.
Чтобы сайт стал работать по протоколу безопасного соединения HТТPS, нужен SSL-сертификат, который содержит криптографические ключи, а также данные о веб-сайте и подтверждает его подлинность. Надежные сертификаты выдаются специальными удостоверяющими центрами. Подробнее о том, как получить SSL-сертификат, вы можете прочитать в отдельной статье на нашем сайте.
Схема передачи данных по протоколу HTTPS
- Браузер пользователя просит сайт предоставить SSL-сертификат для подтверждения подлинности веб-ресурса.
- Сайт, поддерживающий HTTPS, отправляет сертификат.
- Браузер проверяет легальность сертификата в центре сертификации.
- Браузер и сайт договариваются о секретном ключе для шифрования данных. Они делают это при помощи асимметричного шифрования, которое предполагает использование двух ключей — открытого (для шифровки отправляемого сообщения) и закрытого (для расшифровки полученного сообщения).
- Браузер и сайт передают информацию, используя симметричное шифрование, при котором данные зашифровываются и расшифровываются с помощью одного и того же общего ключа.
Синтаксически HTTPS идентичен протоколу HTTP, то есть использует те же стартовые строки и заголовки.
Значение HTTPS для SEO
Использование протокола HTTPS является значимым фактором ранжирования сайтов в результатах поиска. Ещё в 2015 году специалист Google Гэри Иллис заявил, что повышение рейтинга компании по протоколу HTTPS может стать решающим фактором, когда в остальном сигналы качества для двух результатов поиска равны. Если поисковый робот обнаружит две одинаковые страницы — одну с HTTP, а вторую с HTTPS, он добавит в индекс страницу с безопасным протоколом.
Сайт, который не использует HTTPS-протокол, со временем может потерять свои позиции в поиске. Отсутствие HTTPS говорит пользователям и поисковым системам, что безопасность их данных находится под угрозой, а значит, отображать такой сайт на первых страницах выдачи и переходить на него не стоит.
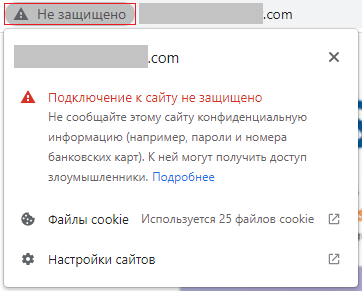
Кроме того, в строке браузера, например, Google Chrome, рядом с адресом сайта без HTTPS ставится отметка «Не защищено».
Тогда как сайты, использующие безопасный протокол HTTPS, помечаются значком в виде замка.
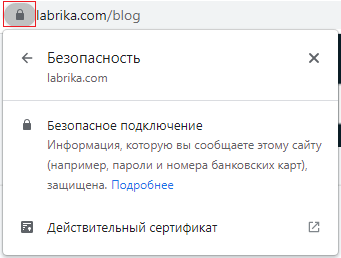
Посмотреть данные о наличии на вашем сайте протокола HTTPS и SSL-сертификата, позволяющего использовать зашифрованное соединение, вы можете на сервисе Labrika в отчете «Безопасность» раздела «Технический аудит».
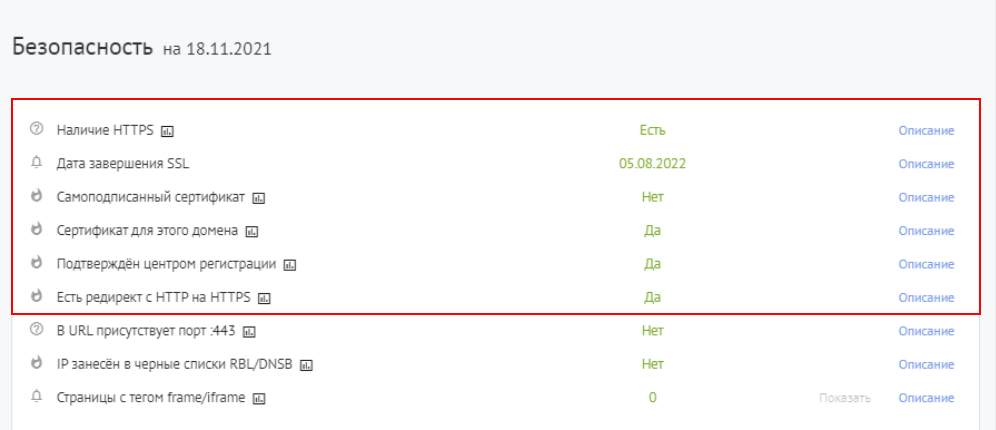
Протокол HTTPS обязательно должен быть на тех сайтах, которые запрашивают конфиденциальные данные пользователей: логины и пароли от аккаунтов, номера банковских карт, адреса электронной почты и т. п. В первую очередь это касается коммерческих ресурсов, социальных сетей, почтовых сервисов, сайтов с регистрацией пользователей.
Читать дальше подобные статьи
- Проверка сайта на ошибки 404. Как исправить ссылки на страницу?
- Что такое внутренние ошибки сервера 500 Internal server error и как их исправить?
- Веб-страница сайта временно недоступна или перемещена — что делать с долгим ответом сервера?
- Зачем нужны SSL и TLS сертификаты для SEO сайта?
Источник: labrika.ru
Что такое Web 3.0 и почему это должно волновать?

Добро пожаловать на информационном блоге infinitymoneyonline.com, в этой статье я рискну рассказать вам о том, какие инновации и достижения ожидают нас в Web 3.0, Web 4.0 и Web 5.0 и как они будут формировать нашу повседневную жизнь.
Веб 3.0 — это кульминация различных этапов развития Интернета, конкретное начало которому было положено в конце 1980-х годов в ЦЕРНе в Швейцарии. Она родилась из необходимости поделиться научными знаниями с остальным миром. Ученый Тим Бернерс-Ли разработал платформу, которая позволила бы пользователям всего мира обмениваться информацией, создавать ее и делать общедоступной.
Основная идея заключалась в том, что у всех людей в Интернете должна быть платформа, позволяющая обмениваться идеями и общаться без барьеров и цензуры. Важно интегрировать как частных пользователей, так и крупные компании или правительства.
Первые подходы представляли собой статичные веб-сайты, которые предоставляли только информацию и были связаны друг с другом гиперссылками. В начале 00-х годов эти статичные веб-сайты превратились в интерактивные, где также можно было вводить информацию.
В конце прошлого десятилетия были созданы новые протоколы, которые сделали возможным Web 3.0: Искусственный интеллект теперь используется для чтения, оценки и фильтрации записей данных и их пересылки пользователям. Веб 3.0 определяется тем, что веб-контент будет читаться машинами. Для этого разрабатываются новые HTML-протоколы, которые активно взаимодействуют друг с другом и образуют базовую сеть, обеспечивающую работу искусственного интеллекта. Таким образом, возникает двойственность, и интернет становится не просто средством достижения цели, но и платформой для нечеловеческого общения и автоматизированного обмена данными.
Web 3.0 — это сеть, которую в принципе можно понять как мозг, развившийся в результате естественного отбора: Информация и данные поступают в систему, протоколы и программы пытаются обработать и переварить эти данные, а затем возвращают соответствующую информацию пользователю, когда она необходима или запрашивается.
Если придерживаться этой метафоры: Web 1.0 был чисто реактивным мозгом, который мог только собирать информацию, не имея возможности влиять на нее. В Web 2.0 присутствуют первые черты «сознания» — контент можно вводить и снова выводить. Теперь содержимое можно редактировать с обеих сторон и записывать на «жесткий диск». Web 3.0 использует собственный интеллект для создания целевых результатов и их выполнения.
Что такое браузер простыми словами и для чего он нужен
Приветствую вас, уважаемый посетитель блога PenserMen.ru. Прежде чем ответить на вопрос, что такое браузер простыми словами и для чего он нужен, давайте обратимся к истории.
Хотя историей это, конечно, назвать можно с натяжкой. Но всё-таки, пара десятков лет по меркам современных интернет технологий это срок приличный.

Родоначальник всемирной паутины и прародитель браузера

Итак, встречайте Тимоти Джон Бе́рнерс-Ли. Закончил в 1976 году Оксфордский университет, причём с отличием и получил степень бакалавра физики. И уже в 1989 году, работая в Европейской лаборатории по ядерным исследованиям, предложил грандиозный проект, который ныне именуют всемирной паутиной.
А в 1993-ем был создан и выпущен в «тираж» первый «мозаичный» браузер, NCSA Mosaic. Разработали его инженер-изобретатель и в то же время инвестор-предприниматель Марк Андрессен. Также, в этом принял участие Эрик Бин, соучредитель Netscape, талантливый программист, он стал и соавтором Mosaic браузера.
Веб-протоколы Тима Бернерса-Ли обеспечивали все соединения браузера. А Марк Андриссен, в свою очередь, предоставил отличный интерфейс. И всё это в купе произвели в обществе эффект разорвавшейся бомбы. Да, буквально за два года никому неизвестный интернет стал повсеместным явлением.
Но в начале 1997 года развитие браузера Mosaic прекратилось и он уступил место целой плеяде новых, быстро развивающихся интернет-браузеров. Таких как Netscape Navigator и Internet Explorer, в которых сохранились идеи NCSA Mosaic и других, вскоре увядших, Air Mosaic, Infomosaic, Fujitsu.
Почему же именно браузер — в двух словах о названии
- Если дословно перевести слово browser с английского на русский получится просмотрщик. Согласитесь, не звучит.
- В сочетании со словом viewer уже будет программа просмотра. Немного лучше, но как-то длинновато что ли.
- Часто его называют обозревателем, хотя по-английски это будет observer, но приклеилось оно к нему намертво. Особенно словосочетание web browser, то есть веб обозреватель.
- Реже называют навигатором, хотя точный перевод этого слова и navigator, но тем не менее и это имеет место быть.
- Ещё реже, окно просмотра, полное соответствие было бы viewport, однако и такое словосочетание приобрело право на жизнь.
- И совсем редко, в узких кругах кличут бродилкой. Но если прикинуть, «просматривает», по смыслу вроде как и получается, что «бродит». Да и первые две буквы «бр» созвучны. Почему бы нет?
- Ну и просто браузер, это уже его английское произношение написанное русскими буквами. Кстати, транслитерация, тоже где-то рядом с этим — бров’сер.
Теперь, надеюсь, и чайнику понятно откуда взялось такое вполне логичное название. А с другой стороны очередное засорение русского языка иностранными словами. Но ничего не поделаешь, время диктует свои правила.
Что такое браузер доступным языком
Из всего, что было написано до этого можно сделать конкретный вывод. Браузер это программа. Но программа особенная, которая не просто производит какие-то действия на компьютере. Это программа, которая связывает его со всемирной сетью, налаживает взаимодействие с ней и выдаёт пользователю запрашиваемую им информацию.
Но информация то из сети поступает в таком виде, что сам чёрт в ней ногу сломает! И никакой рядовой пользователь ничего в ней не поймёт. Вот полюбуйтесь, это код случайной страницы из интернета :

Так вот, браузер все эти кракозябры преобразует в тексты, таблицы, ссылки, картинки, фотографии, видеоролики, фильмы и т. д. То есть во всё то, что привычно для нашего восприятия. Более того, он позволяет нам управлять всем, что мы видим на экране своего монитора.
Как работает компьютерная интернет бродилка
С помощью клавиатуры и мыши мы задаём команду браузеру. Будь то клик мышкой по ссылке, либо ввод текста в поисковую строку с последующим нажатием на «Enter» или ещё какие-то действия.
Наш веб обозреватель преобразует эти действие в код и отправляет их на сервер. Тот, в свою очередь, обрабатывает полученный запрос, ищет у себя запрошенную информацию и выдаёт обратно, опять таки, закодированную в кракозябры веб страницу.
Получив нечитабельный для нас ответ с сервера браузер, теперь уже, расшифровывает его в обратном порядке и преподносит нам в «человеческом» виде. Ну это очень простым языком, чтобы было понятно любому новичку.
Если сюда приплести такие термины, как HTML, XML, CSS, PHP, Java-skript и прочую лабуду, то для неподготовленного читателя это может вызвать отторжение от прочтения данного материала. Поэтому они намеренно упущены, хотя и очень просятся в тему.
Для чего ещё нужен веб браузер и его функции
В первую очередь, наш навигатор играет роль «переводчика» — «курьера» между человеком и сервером в интернете, а также транслятора информации на экран монитора. Но помимо этого он может выполнять и много других очень полезных функций. Основные это:
- Хранение информации и причём это относится не только к истории посещений, но даже к паролям. Хотя последние лучше, конечно, хранить в специальных программах.
- Перекачивание с просторов интернета любых необходимых данных. Будь то фильмы, картинки либо любые другие файлы или документы без использования дополнительных программ.
- Взаимодействие с другими интернет пользователями через социальные сети, электронную почту, множество различных форумов и всевозможных чат площадок.
- Защита пользователя ПК от атак различных программ, способных создать какую либо угрозу, путём блокировок или соответствующих предупреждений. Но, опять-таки, специальные программы всё же надёжнее.
Можно, конечно, список и продолжить, но наша цель простота в изложении данного вопроса, поэтому можно вполне ограничиться самыми главными.
Что это за расширения браузеров и зачем они нужны
Расширения это тоже небольшие программы. Их ещё называют плагинами. Они позволяют существенно увеличить возможности браузера в плане выполнения максимально возможного спектра задач.
К тому, же с помощью них можно изменить дизайн под свой вкус и цвет, изменить расположение и количество информации в окне самого браузера. А можно и вообще добавить узкоспециализированную информацию, которая вам необходима в работе.
Все имеющиеся на сегодняшний день браузеры имеют, так называемые интернет-магазины дополнений. Чтобы туда попасть нужно зайти в «Настройки и управление». Обычно это три точки справа вверху.
Если это браузер Microsoft Edge, то уже в первом выплывшем окне найдёте «Расширения». А в Google Chrome, например, сначала нужно выбрать «Дополнительные инструменты», а уже в следующем щёлкнуть «Расширения» и вас сразу же перебросит в этот самый магазин:

Вот как раз жёлтым цветом на картинке и подсвечены значки установленных расширений. Ну заодно ещё один момент попутно. Фото, слева от трёх точек это аватарка вашего профиля в гугл. Пока речь о Гугл Хром. Об этом будет сказано чуть ниже.
Как пользоваться браузером
Веб браузер является самой важной программой для «блужданий» в интернете. Поэтому-то так важно уметь им пользоваться, а для этого необходимо в первую очередь познакомиться с его базовыми инструментами. Все остальные можно освоить в процессе работы. Итак, просто об инструментах браузера и для чего они нужны.
Навигация
Название говорит само за себя. С помощью этого инструмента можно перемещаться на нужную страницу или от странички к страничке, искать необходимую информацию. Да, в общем, много чего. Посмотрим на примере браузера Microsoft Edge:

- Кнопка перехода на предыдущую страницу;
- Кнопка перехода на следующую страницу;
- Обновить страницу, в случае некорректной загрузки или для проверки возможных изменений;
- Кнопка перехода на домашнюю страницу, если в настройках такая установлена;
- Строка ввода адреса ресурса либо поискового запроса;
Имейте ввиду, что после ввода URL страницы или поискового запроса в адресную строку необходимо нажимать клавишу «Enter».
Окна и вкладки
Тоже очень удобная штука. Нажимать стрелочки туда сюда в поисках ранее открытых страниц это то ещё занятие. Но работа становится гораздо проще, если использовать в этих целях окна и вкладки. На картинке показаны некоторые возможные манипуляции с ними в браузере Google Chrome:

- Нажав на крестик можно просто закрыть уже открытую вкладку;
- Клик по плюсику даёт возможность открыть ещё одну вкладку, не закрывая предыдущую;
- Щелчок правой кнопкой мыши по свободному месту на поле вкладок позволит повторно открыть ошибочно или намеренно закрытую ранее вкладку;
- Нажав на левую кнопку мыши по открытой вкладке и протянув её в сторону, можно открыть выбранную вкладку в новом окне.
Последний пункт, вообще-то, очень даже может быть востребован. Бывают случаи, когда нужно произвести сравнение, например, каких то таблиц. Вот тут и поможет эта фишка. Располагайте их рядом и работайте с комфортом.
История или журнал просмотров
Тоже вещь очень даже полезная. Бывают случаи, что просматриваемую страницу вы забыли сохранить в закладки. Вот тогда то вам и пригодится эта опция браузера. Кликаете правой кнопкой по «Настройки и прочее». Так называются три точки в Edge и выбираете «Журнал»:

В Хроме же это будет иметь название «Истории». А впрочем, будь то Опера, Мазила, Сафари или какой другой веб браузер интуитивно будет понятно что искать.
Закладки
Ну это уж переоценить просто невозможно. Очень часто просматривая различные материалы в интернете нам либо не хватает времени на полное его изучение, либо просто хочется всегда иметь его под рукой. Как раз для этого и существует такая функция как закладки или избранное.
Чтобы сохранить URL активного окна в закладки необходимо кликнуть по звёздoчке в поле ввода запроса. Она находится с краю, справа. И после клика по кнопке «Готово», он у вас будет моментально сохранен вместе с названием страницы. Кстати, есть возможность и поменять это название (пункт 2):

Наверху изображено диалоговое окно браузера Эджи. В других оно выглядит несколько иначе, но суть остаётся той же самой.
Сихронизация
Архиполезная фича! На верхней картинке это кнопка «Включить синхронизацию». Она появится если вы не вошли в свой аккаунт Гугл. Так вот, благодаря этой самой синхронизации появляется возможность просматривать историю, закладки, да просто открытую в данный момент страничку на ПК, с любого вашего устройства.
И делается это без всякого контакта устройств между собой. Да что там контакта, они могут находиться хоть в разных концах планеты. Лишь бы интернет там был. Появилась эта возможность сравнительно недавно, но быстро приобрела популярность, так как оказалась очень востребованной и крайне удобной.
Скачивание файлов
Термин скачивание подразумевает под собой сохранение текстовых, мультимедийных установочных и прочих разных файлов на своём ПК или другом устройстве. Здесь тоже нет ничего сложного. Если это текст, достаточно просто его скопировать и вставить в тот же Word у себя на ПК.
У программных файлов обычно имеется кнопка «Скачать.» А для того чтобы загрузить на своё устройство фото нужно воспользоваться правой кнопкой мыши и вызвать меню. Потом выбрать «Сохранить изображение как»:

В разных браузерах это меню будет выглядеть по разному, но тем не менее разобраться в этом сможет любой пенсионер или просто чайник.
Зачем нужно обновлять браузер
Ну если с вопросом зачем нужен браузер мы разобрались, то с его обновлением необходимо уточнить. Некоторые пользователи ПК намерено не устанавливают эти обновления. А этого делать категорически нельзя. Почему? Вы сами себя лишаете новых разработок, которые появляются с неимоверной скоростью.
Но дело ещё в другом.
В процессе работы проявляются некоторые ошибки и уязвимости в работе веб браузеров, которые необходимо исправлять и закрывать. Да и компьютерные устройства со временем совершенствуются. И как следствие возникает необходимость в корректировке параметров самого браузера, как впрочем и любого другого программного обеспечения.
Если сказать простыми словами, обновления нужны для того чтобы идти в ногу со временем. Поэтому пренебрегать ими только себе во вред. И это, рано или поздно, непременно приведёт к сложностям в веб сёрфинге и как следствие к ограничению функциональности самого браузера. И для чего же тогда нужен такой браузер?
Так что не надо ущемлять возможности своего интернет навигатора и тогда вы получите полноценное программное обеспечение для комфортного взаимодействия со всемирной паутиной.
Удачи вам! До скорых встреч на страницах блога PenserMen.ru.
Источник: pensermen.ru